 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISUALSKILL: Multimodal Skills for Computer-Use Agents
Jun 16, 2026Computer-use agents (CUAs) approach human-level performance on standardised benchmarks but still struggle on long-horizon tasks and unseen software. Existing skill libraries address this with reusable skills, but represent the skill artifact as text only, despite the visual nature of GUI interaction. We propose VISUALSKILL: a hierarchical multimodal skill, tailored to each target application and organised as a central index over per-topic files, which the agent consumes through a load_topic MCP tool that fetches the relevant topic's text and figures on demand. We construct each skill with a two-stage pipeline that combines authored documentation with live-application UI exploration. On two CUA benchmarks, CUA-World and OSExpert-Eval, a Claude Code CLI agent backed by Claude Opus 4.6 reaches an average score of 0.456 with VISUALSKILL, a +15.3 point absolute lift over the no-skill baseline (0.303). Against a matched text-only skill that is generated from the same source content and differs from VISUALSKILL only in modality, VISUALSKILL yields a further +8.3 point absolute gain over the matched text-only skill (0.373 vs. 0.456), providing direct evidence that retaining visual figures in the skill artifact, rather than verbalizing them away, helps the agent both identify UI elements and verify workflow state after each action. Our code is available at https://github.com/XMHZZ2018/VisualSkills.
FederatedSkill: Federated Learning for Agentic Skill Evolution
Jun 02, 2026Modern LLM agents increasingly rely on skill libraries to handle complex tasks, making skill evolution a primary driver of self-improvement. However, isolated single-user task streams lack the diversity required to build comprehensive skills. While cross-user collaboration can overcome this data bottleneck, current trajectory-sharing approaches compromise user privacy and impose a uniform global library that fails to accommodate client heterogeneity. We introduce FederatedSkill, a privacy-preserving framework for collaborative agent evolution. Moving beyond raw trajectory sharing, FederatedSkill utilizes semantic skill diffs, structured patches over local libraries, as the fundamental unit of communication. On the server side, an evolution agent aggregates these patches to dynamically model client-specific capability boundaries, facilitating strictly personalized skill evolution rather than a suboptimal global average. Evaluated across 20 distinct agent task families, FederatedSkill demonstrates substantial gains over self-evolving baselines, achieving up to a 44.4% increase in success rate and a 37.5% reduction in computational cost.
GroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations
May 14, 2026Large Language Model (LLM) agents increasingly serve as personal assistants and workplace collaborators, where their utility depends on memory systems that extract, retrieve, and apply information across long-running conversations. However, both existing memory systems and benchmarks are built around the dyadic, single-user setup, even though real deployments routinely span groups and channels with multiple users interacting with the agent and with each other. This mismatch leaves three properties of group memory unmeasured: (i) group dynamics that go beyond concatenated one-on-one chats, (ii) speaker-grounded belief tracking, where the per-user memory modeling is needed, and (iii) audience-adapted language, where Theory-of-Mind shifts produce role-specific vocabulary. We introduce GroupMemBench, a benchmark that exposes all three. A graph-grounded synthesis pipeline produces multi-party conversations with controllable reply structure and conditions each message on per-user personas and target audiences. An adversarial query pipeline then binds every question to a specific asker across six categories, spanning multi-hop reasoning, knowledge update, term ambiguity, user-implicit reasoning, temporal reasoning, and abstention, and iteratively searches challenging, realistic queries that reflect comprehensive memory capability. Benchmarking leading memory systems exposes a sharp collapse: the strongest one reaches only 46.0% average accuracy, with knowledge update at 27.1% and term ambiguity at 37.7%, while a simple BM25 baseline matches or exceeds most agent memory systems. This indicates current memory ingestion erases the structural and lexical features group memory depends on, leaving multi-user memory far from solved.
Navigating the Clutter: Waypoint-Based Bi-Level Planning for Multi-Robot Systems
Apr 22, 2026Multi-robot control in cluttered environments is a challenging problem that involves complex physical constraints, including robot-robot collisions, robot-obstacle collisions, and unreachable motions. Successful planning in such settings requires joint optimization over high-level task planning and low-level motion planning, as violations of physical constraints may arise from failures at either level. However, jointly optimizing task and motion planning is difficult due to the complex parameterization of low-level motion trajectories and the ambiguity of credit assignment across the two planning levels. In this paper, we propose a hybrid multi-robot control framework that jointly optimizes task and motion planning. To enable effective parameterization of low-level planning, we introduce waypoints, a simple yet expressive representation for motion trajectories. To address the credit assignment challenge, we adopt a curriculum-based training strategy with a modified RLVR algorithm that propagates motion feasibility feedback from the motion planner to the task planner. Experiments on BoxNet3D-OBS, a challenging multi-robot benchmark with dense obstacles and up to nine robots, show that our approach consistently improves task success over motion-agnostic and VLA-based baselines. Our code is available at https://github.com/UCSB-NLP-Chang/navigate-cluster
CompliBench: Benchmarking LLM Judges for Compliance Violation Detection in Dialogue Systems
Apr 14, 2026As Large Language Models (LLMs) are increasingly deployed as task-oriented agents in enterprise environments, ensuring their strict adherence to complex, domain-specific operational guidelines is critical. While utilizing an LLM-as-a-Judge is a promising solution for scalable evaluation, the reliability of these judges in detecting specific policy violations remains largely unexplored. This gap is primarily due to the lack of a systematic data generation method, which has been hindered by the extensive cost of fine-grained human annotation and the difficulty of synthesizing realistic agent violations. In this paper, we introduce CompliBench, a novel benchmark designed to evaluate the ability of LLM judges to detect and localize guideline violations in multi-turn dialogues. To overcome data scarcity, we develop a scalable, automated data generation pipeline that simulates user-agent interactions. Our controllable flaw injection process automatically yields precise ground-truth labels for the violated guideline and the exact conversation turn, while an adversarial search method ensures these introduced perturbations are highly challenging. Our comprehensive evaluation reveals that current state-of-the-art proprietary LLMs struggle significantly with this task. In addition, we demonstrate that a small-scale judge model fine-tuned on our synthesized data outperforms leading LLMs and generalizes well to unseen business domains, highlighting our pipeline as an effective foundation for training robust generative reward models.
How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
Apr 06, 2026Agent skills, which are reusable, domain-specific knowledge artifacts, have become a popular mechanism for extending LLM-based agents, yet formally benchmarking skill usage performance remains scarce. Existing skill benchmarking efforts focus on overly idealized conditions, where LLMs are directly provided with hand-crafted, narrowly-tailored task-specific skills for each task, whereas in many realistic settings, the LLM agent may have to search for and select relevant skills on its own, and even the closest matching skills may not be well-tailored for the task. In this paper, we conduct the first comprehensive study of skill utility under progressively challenging realistic settings, where agents must retrieve skills from a large collection of 34k real-world skills and may not have access to any hand-curated skills. Our findings reveal that the benefits of skills are fragile: performance gains degrade consistently as settings become more realistic, with pass rates approaching no-skill baselines in the most challenging scenarios. To narrow this gap, we study skill refinement strategies, including query-specific and query-agnostic approaches, and we show that query-specific refinement substantially recovers lost performance when the initial skills are of reasonable relevance and quality. We further demonstrate the generality of retrieval and refinement on Terminal-Bench 2.0, where they improve the pass rate of Claude Opus 4.6 from 57.7% to 65.5%. Our results, consistent across multiple models, highlight both the promise and the current limitations of skills for LLM-based agents. Our code is available at https://github.com/UCSB-NLP-Chang/Skill-Usage.
Chimera: Latency- and Performance-Aware Multi-agent Serving for Heterogeneous LLMs
Mar 23, 2026Multi-agent applications often execute complex tasks as multi-stage workflows, where each stage is an LLM call whose output becomes part of context for subsequent steps. Existing LLM serving systems largely assume homogeneous clusters with identical model replicas. This design overlooks the potential of heterogeneous deployments, where models of different sizes and capabilities enable finer trade-offs between latency and performance. However, heterogeneity introduces new challenges in scheduling across models with diverse throughput and performance. We present Chimera, a predictive scheduling system for multi-agent workflow serving on heterogeneous LLM clusters that jointly improves end-to-end latency and task performance. Chimera applies semantic routing to estimate per-model confidence scores for each request, predicts the total remaining output length of the workflow, and estimates per-model congestion using in-flight predicted token volumes for load balancing. We evaluate Chimera on representative agentic workflows for code generation and math reasoning using multiple heterogeneous LLM configurations. Across comparable settings, Chimera traces the best latency-performance frontier, reducing end-to-end latency by 1.2--2.4$\times$ and improving task performance by 8.0-9.5 percentage points on average over competitive baselines including vLLM.
Ares: Adaptive Reasoning Effort Selection for Efficient LLM Agents
Mar 09, 2026Modern agents powered by thinking LLMs achieve high accuracy through long chain-of-thought reasoning but incur substantial inference costs. While many LLMs now support configurable reasoning levels (e.g., high/medium/low), static strategies are often ineffective: using low-effort modes at every step leads to significant performance degradation, while random selection fails to preserve accuracy or provide meaningful cost reduction. However, agents should reserve high reasoning effort for difficult steps like navigating complex website structures, while using lower-effort modes for simpler steps like opening a target URL. In this paper, we propose Ares, a framework for per-step dynamic reasoning effort selection tailored for multi-step agent tasks. Ares employs a lightweight router to predict the lowest appropriate reasoning level for each step based on the interaction history. To train this router, we develop a data generation pipeline that identifies the minimum reasoning effort required for successful step completion. We then fine-tune the router to predict these levels, enabling plug-and-play integration for any LLM agents. We evaluate Ares on a diverse set of agent tasks, including TAU-Bench for tool use agents, BrowseComp-Plus for deep-research agents, and WebArena for web agents. Experimental results show that Ares reduces reasoning token usage by up to 52.7% compared to fixed high-effort reasoning, while introducing minimal degradation in task success rates.
RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward
Feb 19, 2026Recent advances in multimodal large language models (MLLMs) have shown great potential for extending vision-language reasoning to professional tool-based image editing, enabling intuitive and creative editing. A promising direction is to use reinforcement learning (RL) to enable MLLMs to reason about and execute optimal tool-use plans within professional image-editing software. However, training remains challenging due to the lack of reliable, verifiable reward signals that can reflect the inherently subjective nature of creative editing. In this work, we introduce RetouchIQ, a framework that performs instruction-based executable image editing through MLLM agents guided by a generalist reward model. RetouchIQ interprets user-specified editing intentions and generates corresponding, executable image adjustments, bridging high-level aesthetic goals with precise parameter control. To move beyond conventional, rule-based rewards that compute similarity against a fixed reference image using handcrafted metrics, we propose a generalist reward model, an RL fine-tuned MLLM that evaluates edited results through a set of generated metrics on a case-by-case basis. Then, the reward model provides scalar feedback through multimodal reasoning, enabling reinforcement learning with high-quality, instruction-consistent gradients. We curate an extended dataset with 190k instruction-reasoning pairs and establish a new benchmark for instruction-based image editing. Experiments show that RetouchIQ substantially improves both semantic consistency and perceptual quality over previous MLLM-based and diffusion-based editing systems. Our findings demonstrate the potential of generalist reward-driven MLLM agents as flexible, explainable, and executable assistants for professional image editing.
Learning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025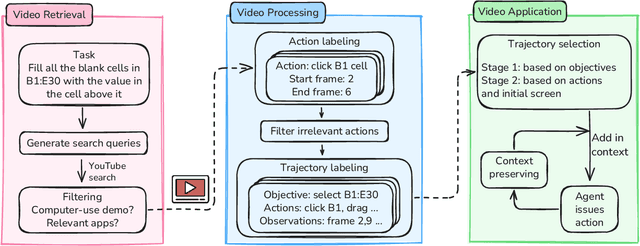



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.