 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025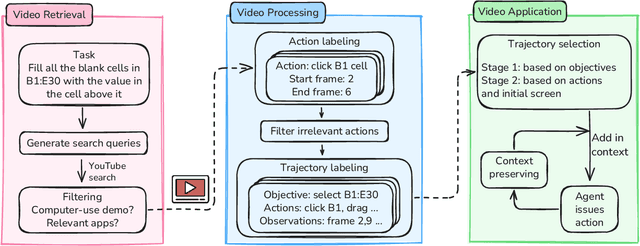



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.
Defending LLM Watermarking Against Spoofing Attacks with Contrastive Representation Learning
Apr 10, 2025Watermarking has emerged as a promising technique for detecting texts generated by LLMs. Current research has primarily focused on three design criteria: high quality of the watermarked text, high detectability, and robustness against removal attack. However, the security against spoofing attacks remains relatively understudied. For example, a piggyback attack can maliciously alter the meaning of watermarked text-transforming it into hate speech-while preserving the original watermark, thereby damaging the reputation of the LLM provider. We identify two core challenges that make defending against spoofing difficult: (1) the need for watermarks to be both sensitive to semantic-distorting changes and insensitive to semantic-preserving edits, and (2) the contradiction between the need to detect global semantic shifts and the local, auto-regressive nature of most watermarking schemes. To address these challenges, we propose a semantic-aware watermarking algorithm that post-hoc embeds watermarks into a given target text while preserving its original meaning. Our method introduces a semantic mapping model, which guides the generation of a green-red token list, contrastively trained to be sensitive to semantic-distorting changes and insensitive to semantic-preserving changes. Experiments on two standard benchmarks demonstrate strong robustness against removal attacks and security against spoofing attacks, including sentiment reversal and toxic content insertion, while maintaining high watermark detectability. Our approach offers a significant step toward more secure and semantically aware watermarking for LLMs. Our code is available at https://github.com/UCSB-NLP-Chang/contrastive-watermark.
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Apr 02, 2025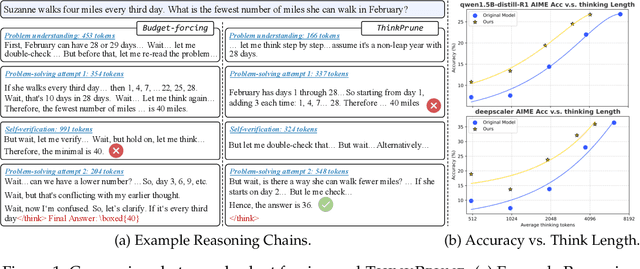
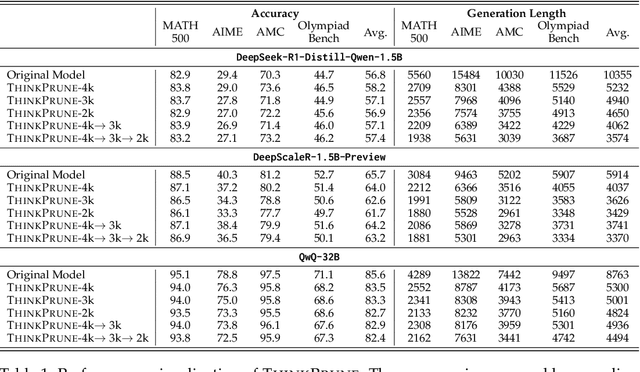
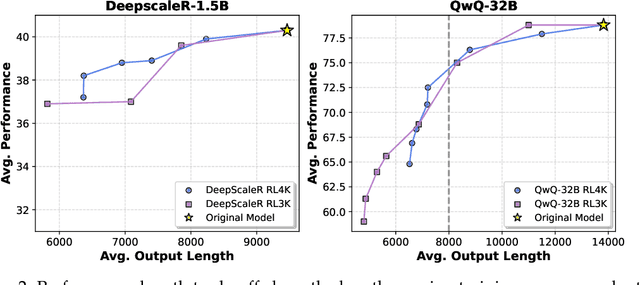
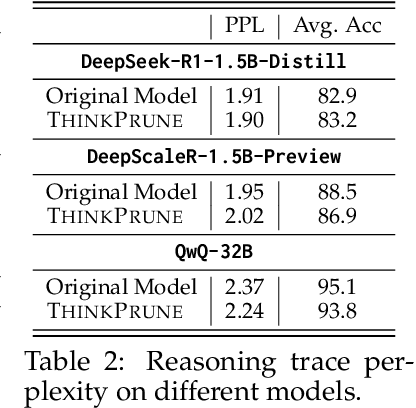
We present ThinkPrune, a simple yet effective method for pruning the thinking length for long-thinking LLMs, which has been found to often produce inefficient and redundant thinking processes. Existing preliminary explorations of reducing thinking length primarily focus on forcing the thinking process to early exit, rather than adapting the LLM to optimize and consolidate the thinking process, and therefore the length-performance tradeoff observed so far is sub-optimal. To fill this gap, ThinkPrune offers a simple solution that continuously trains the long-thinking LLMs via reinforcement learning (RL) with an added token limit, beyond which any unfinished thoughts and answers will be discarded, resulting in a zero reward. To further preserve model performance, we introduce an iterative length pruning approach, where multiple rounds of RL are conducted, each with an increasingly more stringent token limit. We observed that ThinkPrune results in a remarkable performance-length tradeoff -- on the AIME24 dataset, the reasoning length of DeepSeek-R1-Distill-Qwen-1.5B can be reduced by half with only 2% drop in performance. We also observed that after pruning, the LLMs can bypass unnecessary steps while keeping the core reasoning process complete. Code is available at https://github.com/UCSB-NLP-Chang/ThinkPrune.
SyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation
Jan 24, 2025Generating talking avatar driven by audio remains a significant challenge. Existing methods typically require high computational costs and often lack sufficient facial detail and realism, making them unsuitable for applications that demand high real-time performance and visual quality. Additionally, while some methods can synchronize lip movement, they still face issues with consistency between facial expressions and upper body movement, particularly during silent periods. In this paper, we introduce SyncAnimation, the first NeRF-based method that achieves audio-driven, stable, and real-time generation of speaking avatar by combining generalized audio-to-pose matching and audio-to-expression synchronization. By integrating AudioPose Syncer and AudioEmotion Syncer, SyncAnimation achieves high-precision poses and expression generation, progressively producing audio-synchronized upper body, head, and lip shapes. Furthermore, the High-Synchronization Human Renderer ensures seamless integration of the head and upper body, and achieves audio-sync lip. The project page can be found at https://syncanimation.github.io
Fictitious Synthetic Data Can Improve LLM Factuality via Prerequisite Learning
Oct 25, 2024Recent studies have identified one aggravating factor of LLM hallucinations as the knowledge inconsistency between pre-training and fine-tuning, where unfamiliar fine-tuning data mislead the LLM to fabricate plausible but wrong outputs. In this paper, we propose a novel fine-tuning strategy called Prereq-Tune to address this knowledge inconsistency and reduce hallucinations. Fundamentally, Prereq-Tune disentangles the learning of skills and knowledge, so the model learns only the task skills without being impacted by the knowledge inconsistency. To achieve this, Prereq-Tune introduces an additional prerequisite learning stage to learn the necessary knowledge for SFT, allowing subsequent SFT to focus only on task skills. Prereq-Tune can also be combined with fictitious synthetic data to enhance the grounding of LLM outputs to their internal knowledge. Experiments show that Prereq-Tune outperforms existing baselines in improving LLM's factuality across short QA and long-form generation tasks. It also opens new possibilities for knowledge-controlled generation in LLMs. Our code is available at https://github.com/UCSB-NLP-Chang/Prereq_tune.git.
Revisiting Who's Harry Potter: Towards Targeted Unlearning from a Causal Intervention Perspective
Jul 24, 2024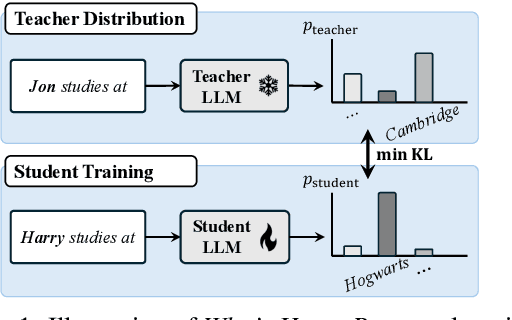

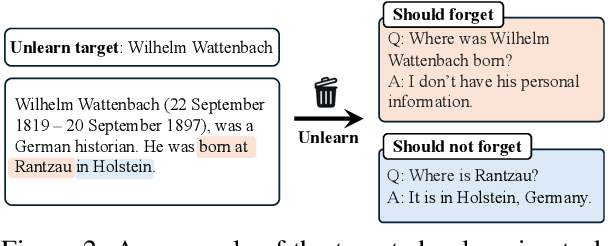

This paper investigates Who's Harry Potter (WHP), a pioneering yet insufficiently understood method for LLM unlearning. We explore it in two steps. First, we introduce a new task of LLM targeted unlearning, where given an unlearning target (e.g., a person) and some unlearning documents, we aim to unlearn only the information about the target, rather than everything in the unlearning documents. We further argue that a successful unlearning should satisfy criteria such as not outputting gibberish, not fabricating facts about the unlearning target, and not releasing factual information under jailbreak attacks. Second, we construct a causal intervention framework for targeted unlearning, where the knowledge of the unlearning target is modeled as a confounder between LLM input and output, and the unlearning process as a deconfounding process. This framework justifies and extends WHP, deriving a simple unlearning algorithm that includes WHP as a special case. Experiments on existing and new datasets show that our approach, without explicitly optimizing for the aforementioned criteria, achieves competitive performance in all of them. Our code is available at https://github.com/UCSB-NLP-Chang/causal_unlearn.git.
Reversing the Forget-Retain Objectives: An Efficient LLM Unlearning Framework from Logit Difference
Jun 12, 2024As Large Language Models (LLMs) demonstrate extensive capability in learning from documents, LLM unlearning becomes an increasingly important research area to address concerns of LLMs in terms of privacy, copyright, etc. A conventional LLM unlearning task typically involves two goals: (1) The target LLM should forget the knowledge in the specified forget documents, and (2) it should retain the other knowledge that the LLM possesses, for which we assume access to a small number of retain documents. To achieve both goals, a mainstream class of LLM unlearning methods introduces an optimization framework with a combination of two objectives - maximizing the prediction loss on the forget documents while minimizing that on the retain documents, which suffers from two challenges, degenerated output and catastrophic forgetting. In this paper, we propose a novel unlearning framework called Unlearning from Logit Difference (ULD), which introduces an assistant LLM that aims to achieve the opposite of the unlearning goals: remembering the forget documents and forgetting the retain knowledge. ULD then derives the unlearned LLM by computing the logit difference between the target and the assistant LLMs. We show that such reversed objectives would naturally resolve both aforementioned challenges while significantly improving the training efficiency. Extensive experiments demonstrate that our method efficiently achieves the intended forgetting while preserving the LLM's overall capabilities, reducing training time by more than threefold. Notably, our method loses 0% of model utility on the ToFU benchmark, whereas baseline methods may sacrifice 17% of utility on average to achieve comparable forget quality. Our code will be publicly available at https://github.com/UCSB-NLP-Chang/ULD.
Towards Efficient Information Fusion: Concentric Dual Fusion Attention Based Multiple Instance Learning for Whole Slide Images
Mar 21, 2024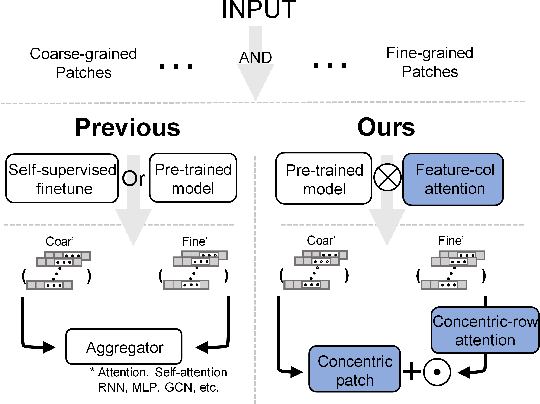
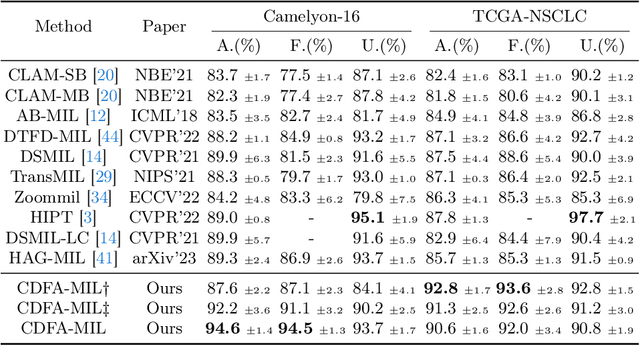
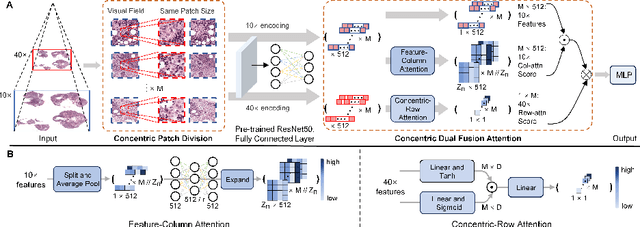

In the realm of digital pathology, multi-magnification Multiple Instance Learning (multi-mag MIL) has proven effective in leveraging the hierarchical structure of Whole Slide Images (WSIs) to reduce information loss and redundant data. However, current methods fall short in bridging the domain gap between pretrained models and medical imaging, and often fail to account for spatial relationships across different magnifications. Addressing these challenges, we introduce the Concentric Dual Fusion Attention-MIL (CDFA-MIL) framework,which innovatively combines point-to-area feature-colum attention and point-to-point concentric-row attention using concentric patch. This approach is designed to effectively fuse correlated information, enhancing feature representation and providing stronger correlation guidance for WSI analysis. CDFA-MIL distinguishes itself by offering a robust fusion strategy that leads to superior WSI recognition. Its application has demonstrated exceptional performance, significantly surpassing existing MIL methods in accuracy and F1 scores on prominent datasets like Camelyon16 and TCGA-NSCLC. Specifically, CDFA-MIL achieved an average accuracy and F1-score of 93.7\% and 94.1\% respectively on these datasets, marking a notable advancement over traditional MIL approaches.
Augment before You Try: Knowledge-Enhanced Table Question Answering via Table Expansion
Jan 28, 2024Table question answering is a popular task that assesses a model's ability to understand and interact with structured data. However, the given table often does not contain sufficient information for answering the question, necessitating the integration of external knowledge. Existing methods either convert both the table and external knowledge into text, which neglects the structured nature of the table; or they embed queries for external sources in the interaction with the table, which complicates the process. In this paper, we propose a simple yet effective method to integrate external information in a given table. Our method first constructs an augmenting table containing the missing information and then generates a SQL query over the two tables to answer the question. Experiments show that our method outperforms strong baselines on three table QA benchmarks. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Augment_tableQA.
Correcting Diffusion Generation through Resampling
Dec 10, 2023Despite diffusion models' superior capabilities in modeling complex distributions, there are still non-trivial distributional discrepancies between generated and ground-truth images, which has resulted in several notable problems in image generation, including missing object errors in text-to-image generation and low image quality. Existing methods that attempt to address these problems mostly do not tend to address the fundamental cause behind these problems, which is the distributional discrepancies, and hence achieve sub-optimal results. In this paper, we propose a particle filtering framework that can effectively address both problems by explicitly reducing the distributional discrepancies. Specifically, our method relies on a set of external guidance, including a small set of real images and a pre-trained object detector, to gauge the distribution gap, and then design the resampling weight accordingly to correct the gap. Experiments show that our methods can effectively correct missing object errors and improve image quality in various image generation tasks. Notably, our method outperforms the existing strongest baseline by 5% in object occurrence and 1.0 in FID on MS-COCO. Our code is publicly available at https://github.com/UCSB-NLP-Chang/diffusion_resampling.git.