 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation
Jan 24, 2025Generating talking avatar driven by audio remains a significant challenge. Existing methods typically require high computational costs and often lack sufficient facial detail and realism, making them unsuitable for applications that demand high real-time performance and visual quality. Additionally, while some methods can synchronize lip movement, they still face issues with consistency between facial expressions and upper body movement, particularly during silent periods. In this paper, we introduce SyncAnimation, the first NeRF-based method that achieves audio-driven, stable, and real-time generation of speaking avatar by combining generalized audio-to-pose matching and audio-to-expression synchronization. By integrating AudioPose Syncer and AudioEmotion Syncer, SyncAnimation achieves high-precision poses and expression generation, progressively producing audio-synchronized upper body, head, and lip shapes. Furthermore, the High-Synchronization Human Renderer ensures seamless integration of the head and upper body, and achieves audio-sync lip. The project page can be found at https://syncanimation.github.io
RAGDiffusion: Faithful Cloth Generation via External Knowledge Assimilation
Nov 29, 2024



Standard clothing asset generation involves creating forward-facing flat-lay garment images displayed on a clear background by extracting clothing information from diverse real-world contexts, which presents significant challenges due to highly standardized sampling distributions and precise structural requirements in the generated images. Existing models have limited spatial perception and often exhibit structural hallucinations in this high-specification generative task. To address this issue, we propose a novel Retrieval-Augmented Generation (RAG) framework, termed RAGDiffusion, to enhance structure determinacy and mitigate hallucinations by assimilating external knowledge from LLM and databases. RAGDiffusion consists of two core processes: (1) Retrieval-based structure aggregation, which employs contrastive learning and a Structure Locally Linear Embedding (SLLE) to derive global structure and spatial landmarks, providing both soft and hard guidance to counteract structural ambiguities; and (2) Omni-level faithful garment generation, which introduces a three-level alignment that ensures fidelity in structural, pattern, and decoding components within the diffusing. Extensive experiments on challenging real-world datasets demonstrate that RAGDiffusion synthesizes structurally and detail-faithful clothing assets with significant performance improvements, representing a pioneering effort in high-specification faithful generation with RAG to confront intrinsic hallucinations and enhance fidelity.
Cold & Warm Net: Addressing Cold-Start Users in Recommender Systems
Sep 27, 2023Cold-start recommendation is one of the major challenges faced by recommender systems (RS). Herein, we focus on the user cold-start problem. Recently, methods utilizing side information or meta-learning have been used to model cold-start users. However, it is difficult to deploy these methods to industrial RS. There has not been much research that pays attention to the user cold-start problem in the matching stage. In this paper, we propose Cold & Warm Net based on expert models who are responsible for modeling cold-start and warm-up users respectively. A gate network is applied to incorporate the results from two experts. Furthermore, dynamic knowledge distillation acting as a teacher selector is introduced to assist experts in better learning user representation. With comprehensive mutual information, features highly relevant to user behavior are selected for the bias net which explicitly models user behavior bias. Finally, we evaluate our Cold & Warm Net on public datasets in comparison to models commonly applied in the matching stage and it outperforms other models on all user types. The proposed model has also been deployed on an industrial short video platform and achieves a significant increase in app dwell time and user retention rate.
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Aug 10, 2022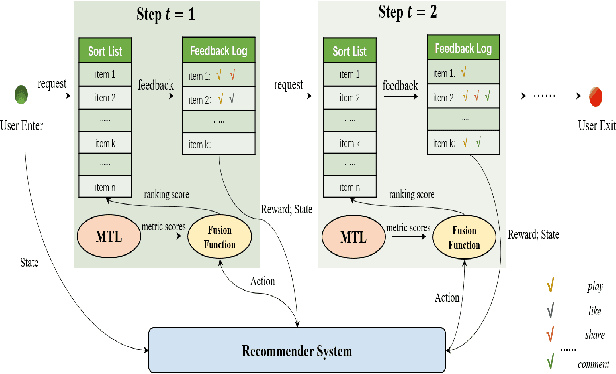
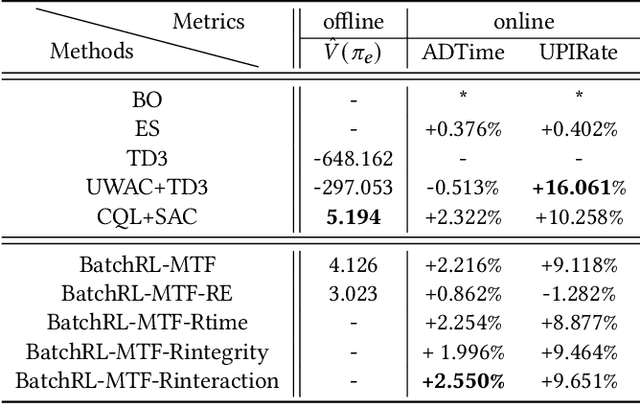
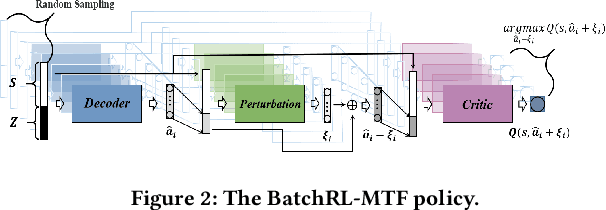
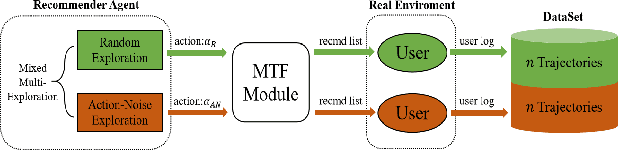
Recommender System (RS) is an important online application that affects billions of users every day. The mainstream RS ranking framework is composed of two parts: a Multi-Task Learning model (MTL) that predicts various user feedback, i.e., clicks, likes, sharings, and a Multi-Task Fusion model (MTF) that combines the multi-task outputs into one final ranking score with respect to user satisfaction. There has not been much research on the fusion model while it has great impact on the final recommendation as the last crucial process of the ranking. To optimize long-term user satisfaction rather than obtain instant returns greedily, we formulate MTF task as Markov Decision Process (MDP) within a recommendation session and propose a Batch Reinforcement Learning (RL) based Multi-Task Fusion framework (BatchRL-MTF) that includes a Batch RL framework and an online exploration. The former exploits Batch RL to learn an optimal recommendation policy from the fixed batch data offline for long-term user satisfaction, while the latter explores potential high-value actions online to break through the local optimal dilemma. With a comprehensive investigation on user behaviors, we model the user satisfaction reward with subtle heuristics from two aspects of user stickiness and user activeness. Finally, we conduct extensive experiments on a billion-sample level real-world dataset to show the effectiveness of our model. We propose a conservative offline policy estimator (Conservative-OPEstimator) to test our model offline. Furthermore, we take online experiments in a real recommendation environment to compare performance of different models. As one of few Batch RL researches applied in MTF task successfully, our model has also been deployed on a large-scale industrial short video platform, serving hundreds of millions of users.
Multi-Tasking Evolutionary Algorithm (MTEA) for Single-Objective Continuous Optimization
Dec 15, 2018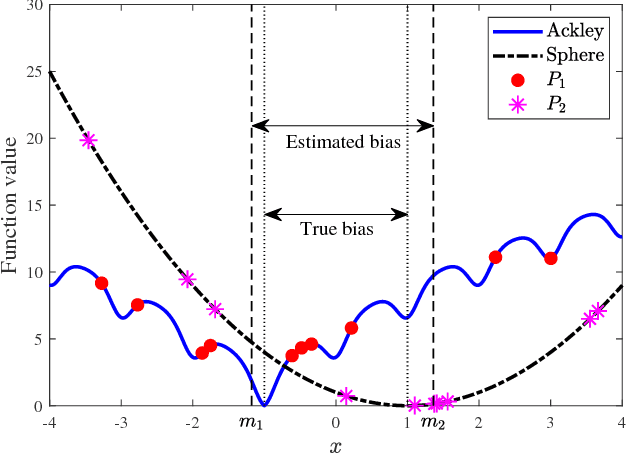
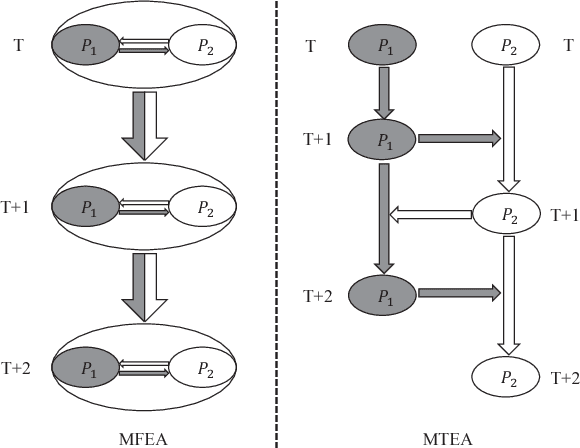
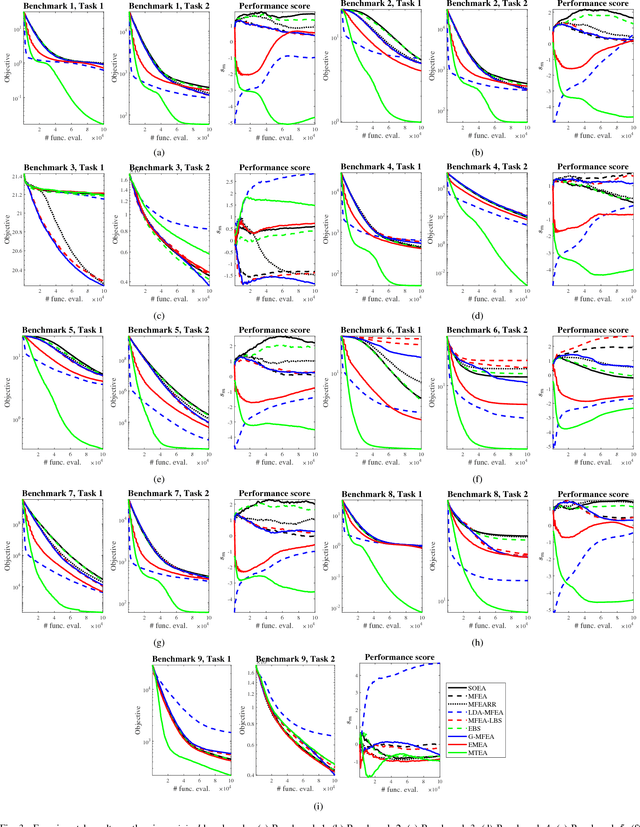
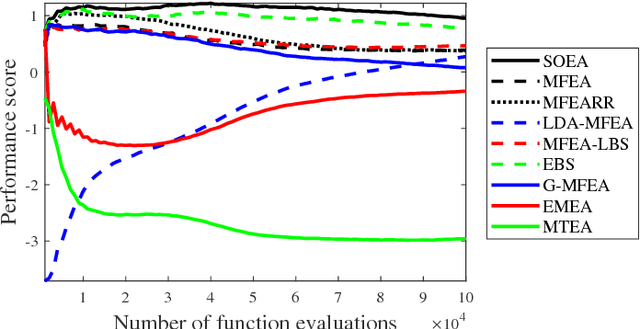
Multi-task learning uses auxiliary data or knowledge from relevant tasks to facilitate the learning in a new task. Multi-task optimization applies multi-task learning to optimization to study how to effectively and efficiently tackle multiple optimization problems simultaneously. Evolutionary multi-tasking, or multi-factorial optimization, is an emerging subfield of multi-task optimization, which integrates evolutionary computation and multi-task learning. This paper proposes a novel easy-to-implement multi-tasking evolutionary algorithm (MTEA), which copes well with significantly different optimization tasks by estimating and using the bias among them. Comparative studies with eight state-of-the-art single- and multi-task approaches in the literature on nine benchmarks demonstrated that on average the MTEA outperformed all of them, and has lower computational cost than six of them. Particularly, unlike other multi-task algorithms, the performance of the MTEA is consistently good whether the tasks are similar or significantly different, making it ideal for real-world applications.