 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven Approach to Geometric Modeling of Systems with Low-Bandwidth Actuator Dynamics
Jul 03, 2023It is challenging to perform identification on soft robots due to their underactuated, high dimensional dynamics. In this work, we present a data-driven modeling framework, based on geometric mechanics (also known as gauge theory), that can be applied to systems with low-bandwidth actuation of the shape space. By exploiting temporal asymmetries in actuator dynamics, our approach enables the design of robots that can be driven by a single control input. We present a method for constructing a series connected model comprising actuator and locomotor dynamics based on data points from stochastically perturbed, repeated behaviors around the observed limit cycle. We demonstrate our methods on a real-world example of a soft crawler made by stimuli-responsive hydrogels that locomotes on merely one cycling control signal by utilizing its geometric and temporal asymmetry. For systems with first-order, low-pass actuator dynamics, such as swelling-driven actuators used in hydrogel crawlers, we show that first order Taylor approximations can well capture the dynamics of the system shape as well as its movements. Finally, we propose an approach of numerically optimizing control signals by iteratively refining models and optimizing the input waveform.
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Aug 10, 2022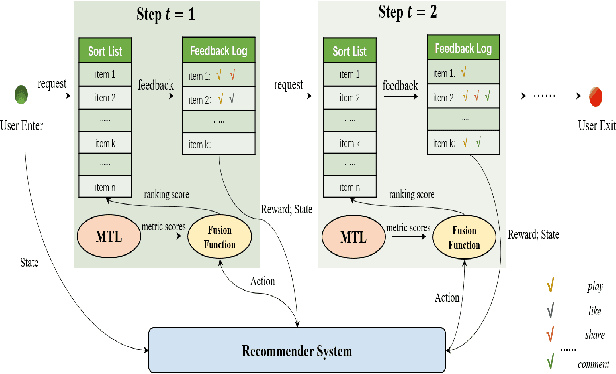
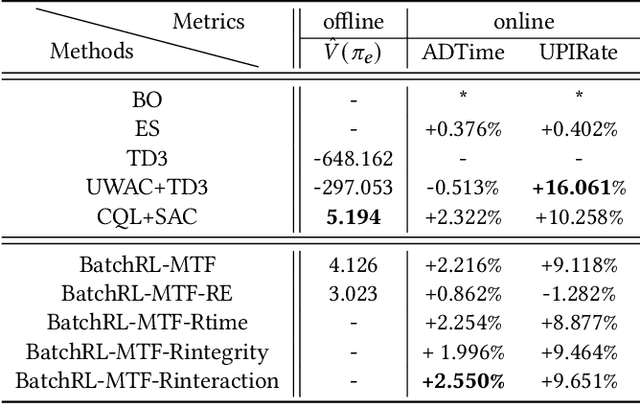
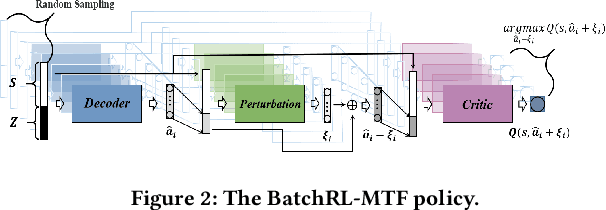
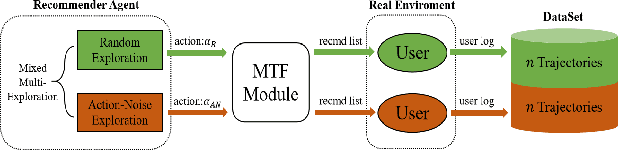
Recommender System (RS) is an important online application that affects billions of users every day. The mainstream RS ranking framework is composed of two parts: a Multi-Task Learning model (MTL) that predicts various user feedback, i.e., clicks, likes, sharings, and a Multi-Task Fusion model (MTF) that combines the multi-task outputs into one final ranking score with respect to user satisfaction. There has not been much research on the fusion model while it has great impact on the final recommendation as the last crucial process of the ranking. To optimize long-term user satisfaction rather than obtain instant returns greedily, we formulate MTF task as Markov Decision Process (MDP) within a recommendation session and propose a Batch Reinforcement Learning (RL) based Multi-Task Fusion framework (BatchRL-MTF) that includes a Batch RL framework and an online exploration. The former exploits Batch RL to learn an optimal recommendation policy from the fixed batch data offline for long-term user satisfaction, while the latter explores potential high-value actions online to break through the local optimal dilemma. With a comprehensive investigation on user behaviors, we model the user satisfaction reward with subtle heuristics from two aspects of user stickiness and user activeness. Finally, we conduct extensive experiments on a billion-sample level real-world dataset to show the effectiveness of our model. We propose a conservative offline policy estimator (Conservative-OPEstimator) to test our model offline. Furthermore, we take online experiments in a real recommendation environment to compare performance of different models. As one of few Batch RL researches applied in MTF task successfully, our model has also been deployed on a large-scale industrial short video platform, serving hundreds of millions of users.
Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations
Oct 26, 2021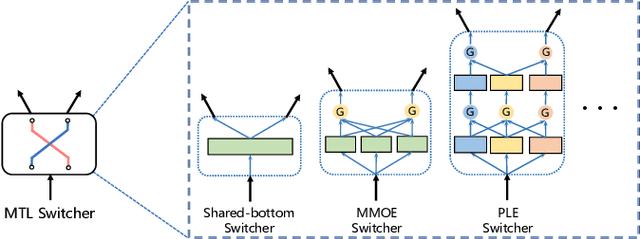
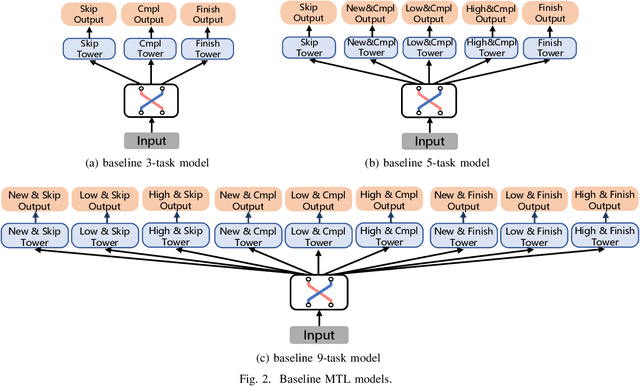
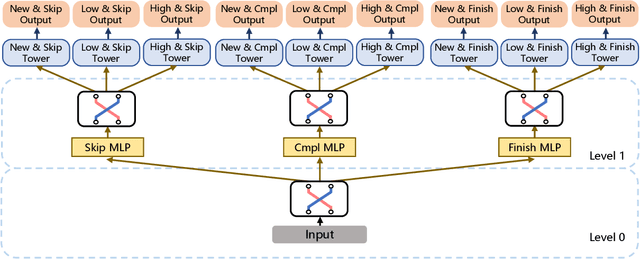
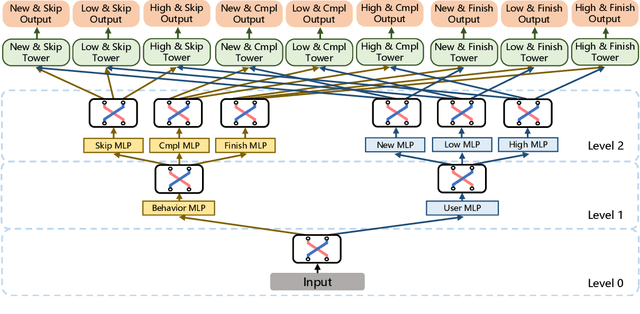
There has been many studies on improving the efficiency of shared learning in Multi-Task Learning(MTL). Previous work focused on the "micro" sharing perspective for a small number of tasks, while in Recommender Systems(RS) and other AI applications, there are often demands to model a large number of tasks with multi-dimensional task relations. For example, when using MTL to model various user behaviors in RS, if we differentiate new users and new items from old ones, there will be a cartesian product style increase of tasks with multi-dimensional relations. This work studies the "macro" perspective of shared learning network design and proposes a Multi-Faceted Hierarchical MTL model(MFH). MFH exploits the multi-dimension task relations with a nested hierarchical tree structure which maximizes the shared learning. We evaluate MFH and SOTA models in a large industry video platform of 10 billion samples and results show that MFH outperforms SOTA MTL models significantly in both offline and online evaluations across all user groups, especially remarkable for new users with an online increase of 9.1\% in app time per user and 1.85\% in next-day retention rate. MFH now has been deployed in a large scale online video recommender system. MFH is especially beneficial to the cold-start problems in RS where new users and new items often suffer from a "local overfitting" phenomenon. However, the idea is actually generic and widely applicable to other MTL scenarios.