 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Speech Representation Learning for Thousands of Languages
Jul 02, 2024Self-supervised learning (SSL) has helped extend speech technologies to more languages by reducing the need for labeled data. However, models are still far from supporting the world's 7000+ languages. We propose XEUS, a Cross-lingual Encoder for Universal Speech, trained on over 1 million hours of data across 4057 languages, extending the language coverage of SSL models 4-fold. We combine 1 million hours of speech from existing publicly accessible corpora with a newly created corpus of 7400+ hours from 4057 languages, which will be publicly released. To handle the diverse conditions of multilingual speech data, we augment the typical SSL masked prediction approach with a novel dereverberation objective, increasing robustness. We evaluate XEUS on several benchmarks, and show that it consistently outperforms or achieves comparable results to state-of-the-art (SOTA) SSL models across a variety of tasks. XEUS sets a new SOTA on the ML-SUPERB benchmark: it outperforms MMS 1B and w2v-BERT 2.0 v2 by 0.8% and 4.4% respectively, despite having less parameters or pre-training data. Checkpoints, code, and data are found in https://www.wavlab.org/activities/2024/xeus/.
YODAS: Youtube-Oriented Dataset for Audio and Speech
Jun 02, 2024



In this study, we introduce YODAS (YouTube-Oriented Dataset for Audio and Speech), a large-scale, multilingual dataset comprising currently over 500k hours of speech data in more than 100 languages, sourced from both labeled and unlabeled YouTube speech datasets. The labeled subsets, including manual or automatic subtitles, facilitate supervised model training. Conversely, the unlabeled subsets are apt for self-supervised learning applications. YODAS is distinctive as the first publicly available dataset of its scale, and it is distributed under a Creative Commons license. We introduce the collection methodology utilized for YODAS, which contributes to the large-scale speech dataset construction. Subsequently, we provide a comprehensive analysis of speech, text contained within the dataset. Finally, we describe the speech recognition baselines over the top-15 languages.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Learning to Speak from Text: Zero-Shot Multilingual Text-to-Speech with Unsupervised Text Pretraining
Feb 05, 2023



While neural text-to-speech (TTS) has achieved human-like natural synthetic speech, multilingual TTS systems are limited to resource-rich languages due to the need for paired text and studio-quality audio data. This paper proposes a method for zero-shot multilingual TTS using text-only data for the target language. The use of text-only data allows the development of TTS systems for low-resource languages for which only textual resources are available, making TTS accessible to thousands of languages. Inspired by the strong cross-lingual transferability of multilingual language models, our framework first performs masked language model pretraining with multilingual text-only data. Then we train this model with a paired data in a supervised manner, while freezing a language-aware embedding layer. This allows inference even for languages not included in the paired data but present in the text-only data. Evaluation results demonstrate highly intelligible zero-shot TTS with a character error rate of less than 12% for an unseen language. All experiments were conducted using public datasets and the implementation will be made available for reproducibility.
Textless Direct Speech-to-Speech Translation with Discrete Speech Representation
Oct 31, 2022



Research on speech-to-speech translation (S2ST) has progressed rapidly in recent years. Many end-to-end systems have been proposed and show advantages over conventional cascade systems, which are often composed of recognition, translation and synthesis sub-systems. However, most of the end-to-end systems still rely on intermediate textual supervision during training, which makes it infeasible to work for languages without written forms. In this work, we propose a novel model, Textless Translatotron, which is based on Translatotron 2, for training an end-to-end direct S2ST model without any textual supervision. Instead of jointly training with an auxiliary task predicting target phonemes as in Translatotron 2, the proposed model uses an auxiliary task predicting discrete speech representations which are obtained from learned or random speech quantizers. When a speech encoder pre-trained with unsupervised speech data is used for both models, the proposed model obtains translation quality nearly on-par with Translatotron 2 on the multilingual CVSS-C corpus as well as the bilingual Fisher Spanish-English corpus. On the latter, it outperforms the prior state-of-the-art textless model by +18.5 BLEU.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
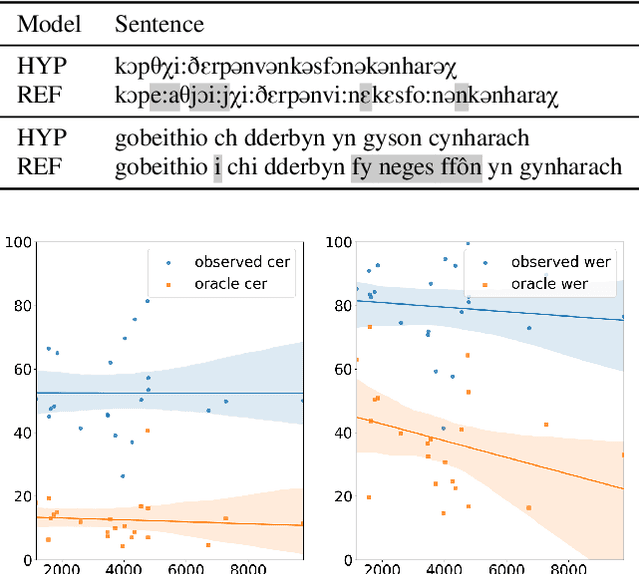
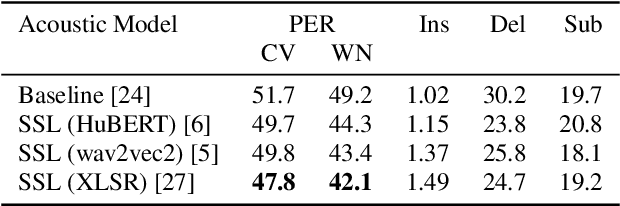
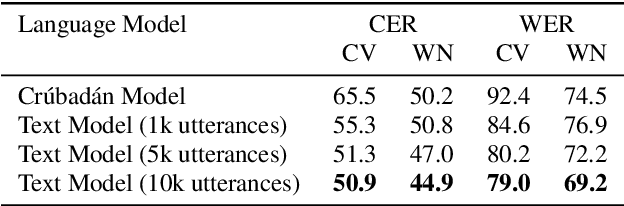
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
On Adversarial Robustness of Large-scale Audio Visual Learning
Mar 23, 2022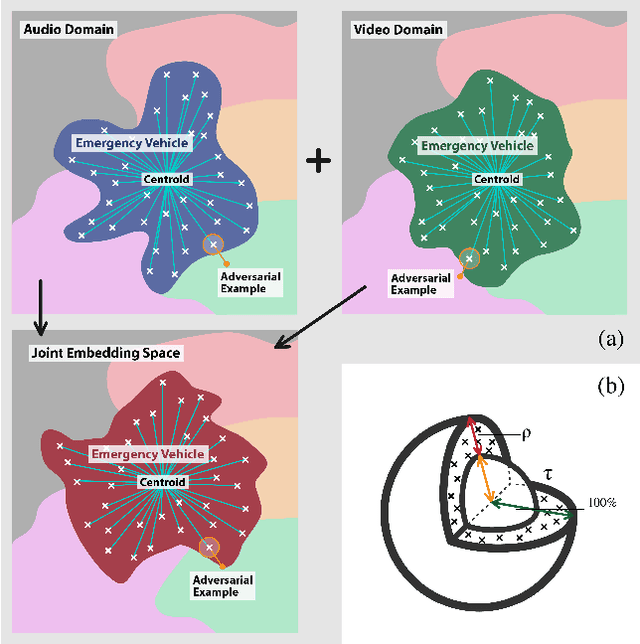
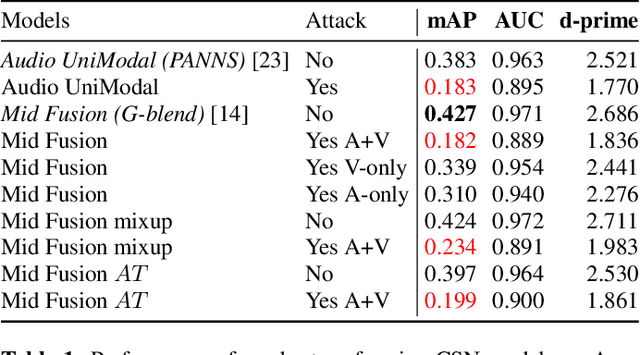
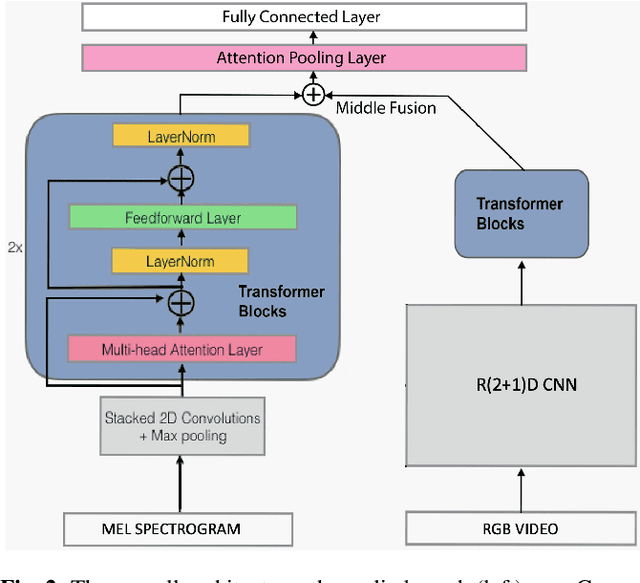
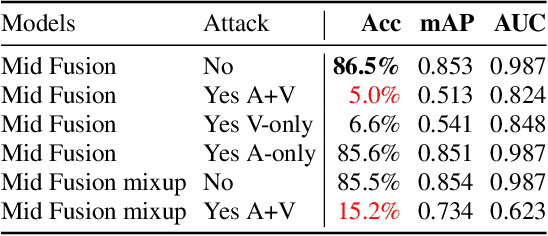
As audio-visual systems are being deployed for safety-critical tasks such as surveillance and malicious content filtering, their robustness remains an under-studied area. Existing published work on robustness either does not scale to large-scale dataset, or does not deal with multiple modalities. This work aims to study several key questions related to multi-modal learning through the lens of robustness: 1) Are multi-modal models necessarily more robust than uni-modal models? 2) How to efficiently measure the robustness of multi-modal learning? 3) How to fuse different modalities to achieve a more robust multi-modal model? To understand the robustness of the multi-modal model in a large-scale setting, we propose a density-based metric, and a convexity metric to efficiently measure the distribution of each modality in high-dimensional latent space. Our work provides a theoretical intuition together with empirical evidence showing how multi-modal fusion affects adversarial robustness through these metrics. We further devise a mix-up strategy based on our metrics to improve the robustness of the trained model. Our experiments on AudioSet and Kinetics-Sounds verify our hypothesis that multi-modal models are not necessarily more robust than their uni-modal counterparts in the face of adversarial examples. We also observe our mix-up trained method could achieve as much protection as traditional adversarial training, offering a computationally cheap alternative. Implementation: https://github.com/lijuncheng16/AudioSetDoneRight
Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations
Oct 26, 2021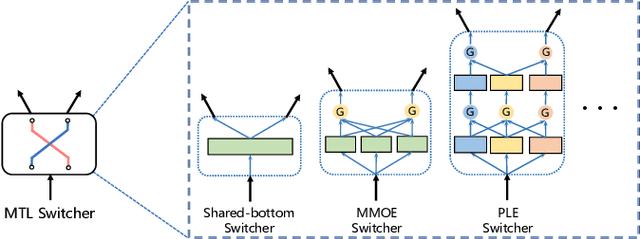
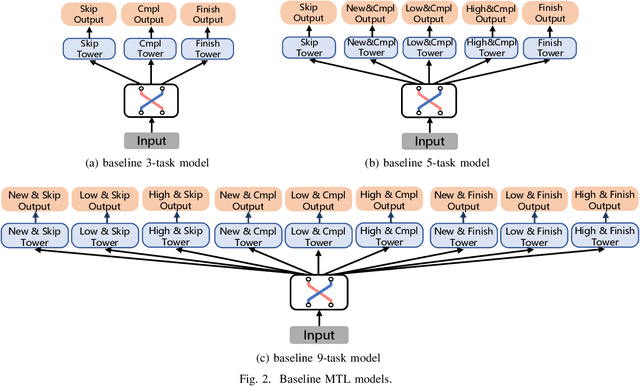
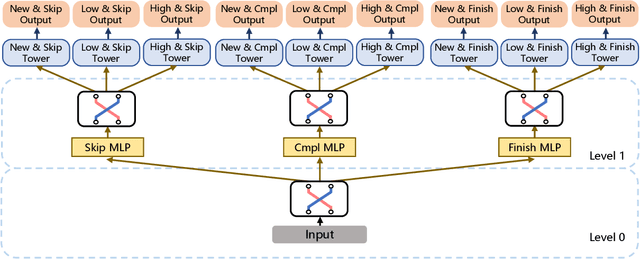
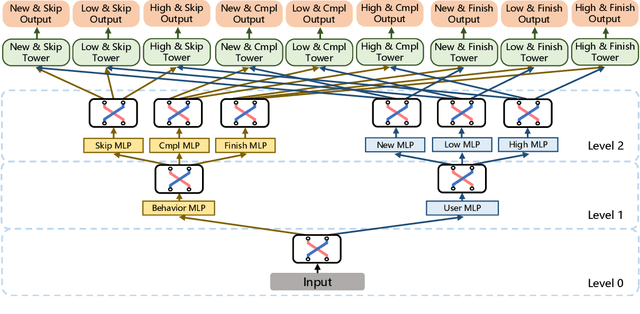
There has been many studies on improving the efficiency of shared learning in Multi-Task Learning(MTL). Previous work focused on the "micro" sharing perspective for a small number of tasks, while in Recommender Systems(RS) and other AI applications, there are often demands to model a large number of tasks with multi-dimensional task relations. For example, when using MTL to model various user behaviors in RS, if we differentiate new users and new items from old ones, there will be a cartesian product style increase of tasks with multi-dimensional relations. This work studies the "macro" perspective of shared learning network design and proposes a Multi-Faceted Hierarchical MTL model(MFH). MFH exploits the multi-dimension task relations with a nested hierarchical tree structure which maximizes the shared learning. We evaluate MFH and SOTA models in a large industry video platform of 10 billion samples and results show that MFH outperforms SOTA MTL models significantly in both offline and online evaluations across all user groups, especially remarkable for new users with an online increase of 9.1\% in app time per user and 1.85\% in next-day retention rate. MFH now has been deployed in a large scale online video recommender system. MFH is especially beneficial to the cold-start problems in RS where new users and new items often suffer from a "local overfitting" phenomenon. However, the idea is actually generic and widely applicable to other MTL scenarios.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021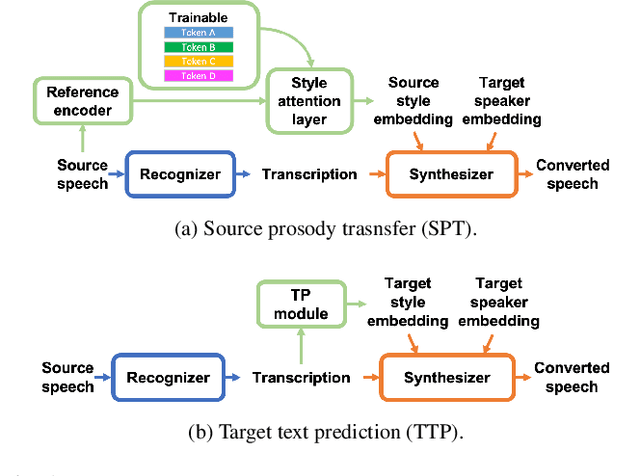

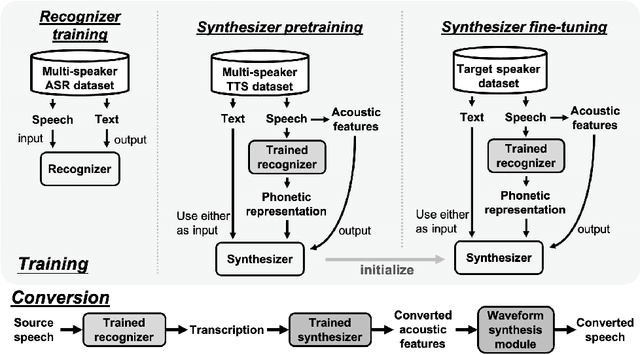

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
Phoneme Recognition through Fine Tuning of Phonetic Representations: a Case Study on Luhya Language Varieties
Apr 04, 2021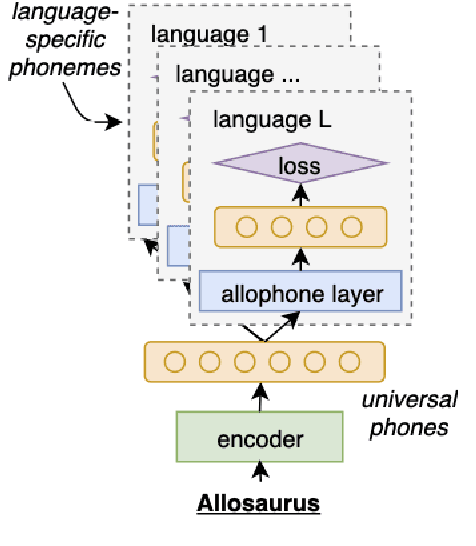
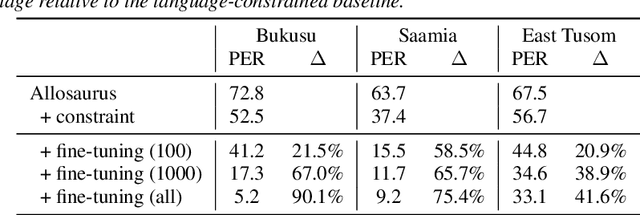
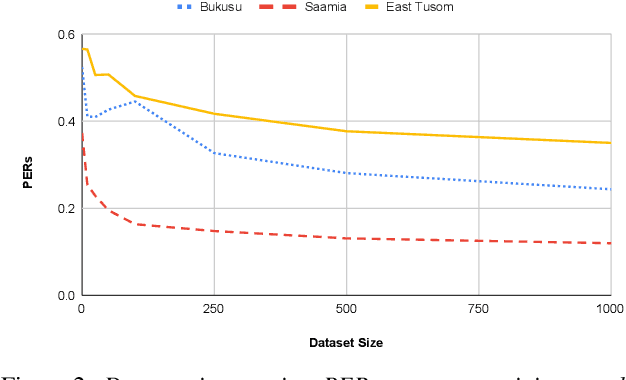
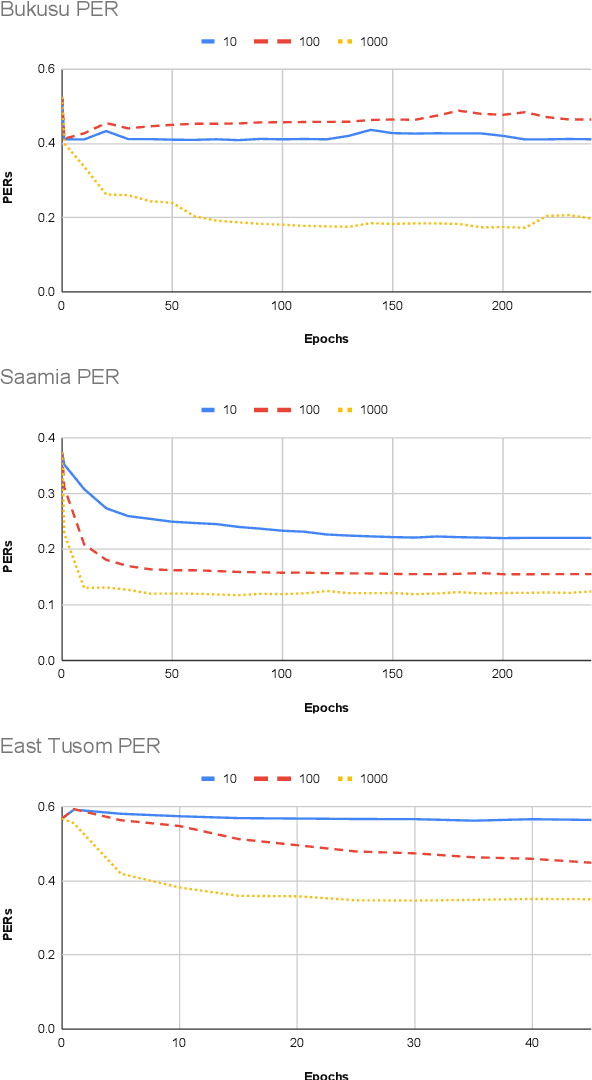
Models pre-trained on multiple languages have shown significant promise for improving speech recognition, particularly for low-resource languages. In this work, we focus on phoneme recognition using Allosaurus, a method for multilingual recognition based on phonetic annotation, which incorporates phonological knowledge through a language-dependent allophone layer that associates a universal narrow phone-set with the phonemes that appear in each language. To evaluate in a challenging real-world scenario, we curate phone recognition datasets for Bukusu and Saamia, two varieties of the Luhya language cluster of western Kenya and eastern Uganda. To our knowledge, these datasets are the first of their kind. We carry out similar experiments on the dataset of an endangered Tangkhulic language, East Tusom, a Tibeto-Burman language variety spoken mostly in India. We explore both zero-shot and few-shot recognition by fine-tuning using datasets of varying sizes (10 to 1000 utterances). We find that fine-tuning of Allosaurus, even with just 100 utterances, leads to significant improvements in phone error rates.