 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-aware Quantization through Noise Tempering
Dec 11, 2022



Quantization has become a predominant approach for model compression, enabling deployment of large models trained on GPUs onto smaller form-factor devices for inference. Quantization-aware training (QAT) optimizes model parameters with respect to the end task while simulating quantization error, leading to better performance than post-training quantization. Approximation of gradients through the non-differentiable quantization operator is typically achieved using the straight-through estimator (STE) or additive noise. However, STE-based methods suffer from instability due to biased gradients, whereas existing noise-based methods cannot reduce the resulting variance. In this work, we incorporate exponentially decaying quantization-error-aware noise together with a learnable scale of task loss gradient to approximate the effect of a quantization operator. We show this method combines gradient scale and quantization noise in a better optimized way, providing finer-grained estimation of gradients at each weight and activation layer's quantizer bin size. Our controlled noise also contains an implicit curvature term that could encourage flatter minima, which we show is indeed the case in our experiments. Experiments training ResNet architectures on the CIFAR-10, CIFAR-100 and ImageNet benchmarks show that our method obtains state-of-the-art top-1 classification accuracy for uniform (non mixed-precision) quantization, out-performing previous methods by 0.5-1.2% absolute.
SQuAT: Sharpness- and Quantization-Aware Training for BERT
Oct 13, 2022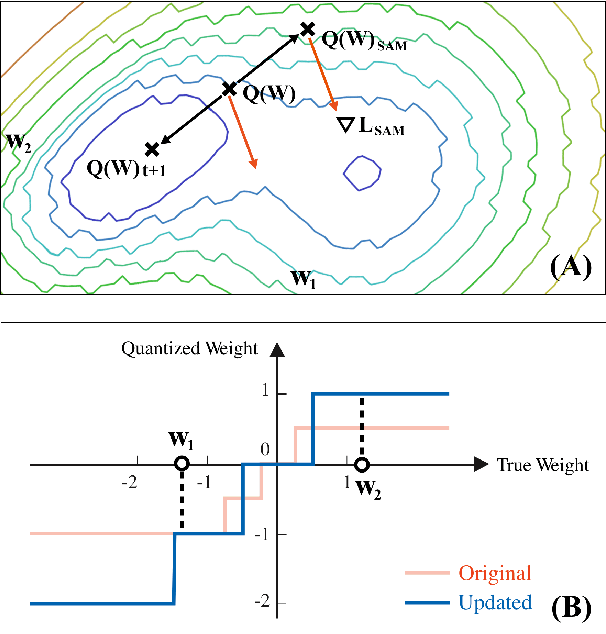
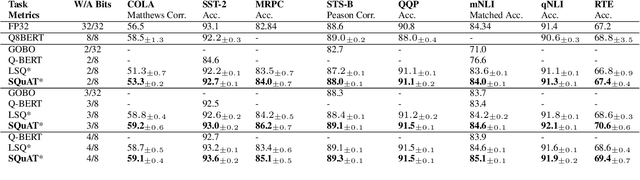
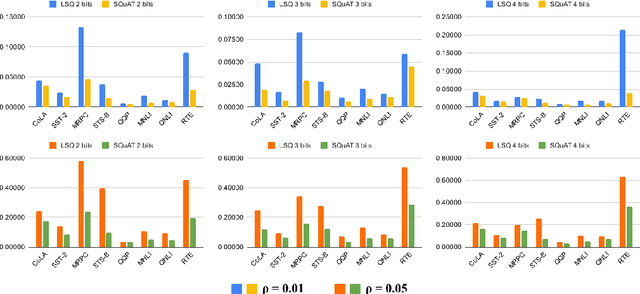
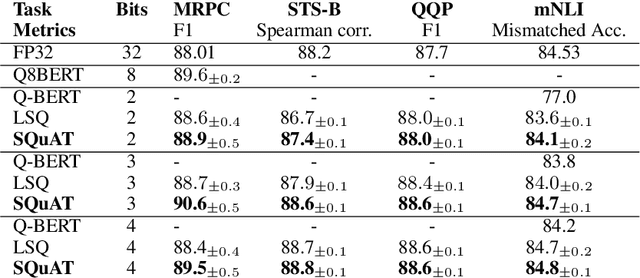
Quantization is an effective technique to reduce memory footprint, inference latency, and power consumption of deep learning models. However, existing quantization methods suffer from accuracy degradation compared to full-precision (FP) models due to the errors introduced by coarse gradient estimation through non-differentiable quantization layers. The existence of sharp local minima in the loss landscapes of overparameterized models (e.g., Transformers) tends to aggravate such performance penalty in low-bit (2, 4 bits) settings. In this work, we propose sharpness- and quantization-aware training (SQuAT), which would encourage the model to converge to flatter minima while performing quantization-aware training. Our proposed method alternates training between sharpness objective and step-size objective, which could potentially let the model learn the most suitable parameter update magnitude to reach convergence near-flat minima. Extensive experiments show that our method can consistently outperform state-of-the-art quantized BERT models under 2, 3, and 4-bit settings on GLUE benchmarks by 1%, and can sometimes even outperform full precision (32-bit) models. Our experiments on empirical measurement of sharpness also suggest that our method would lead to flatter minima compared to other quantization methods.
Robustness of Neural Architectures for Audio Event Detection
May 06, 2022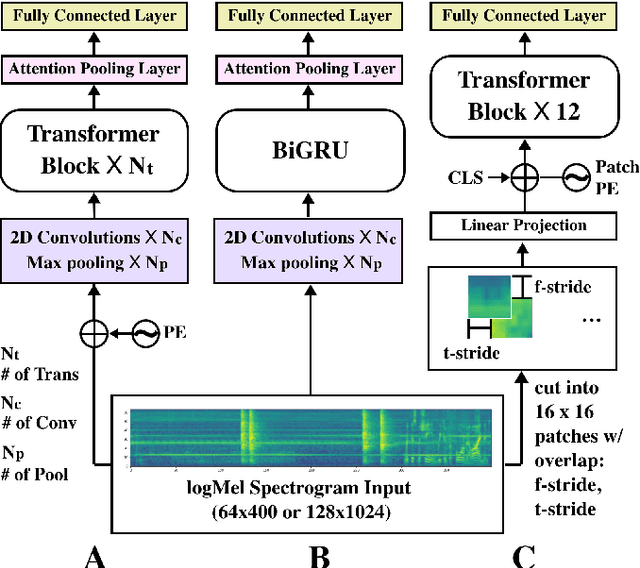
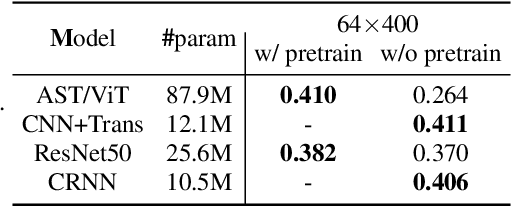
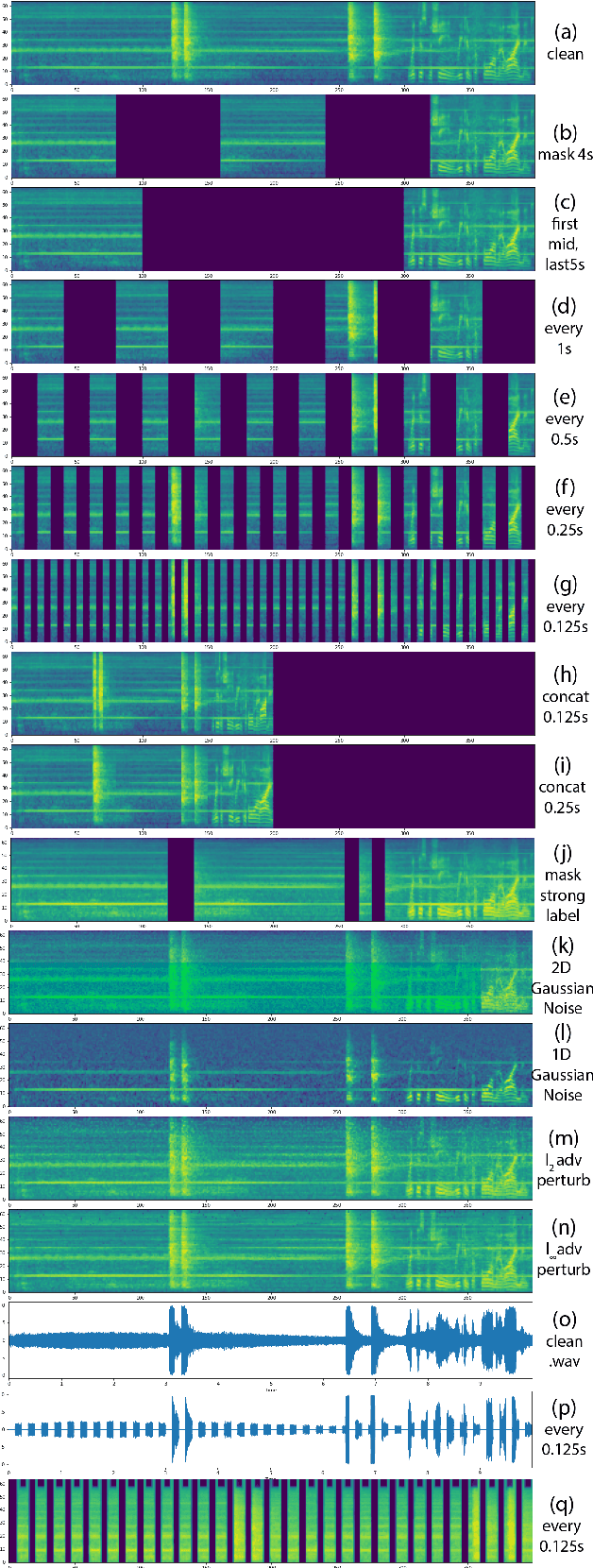
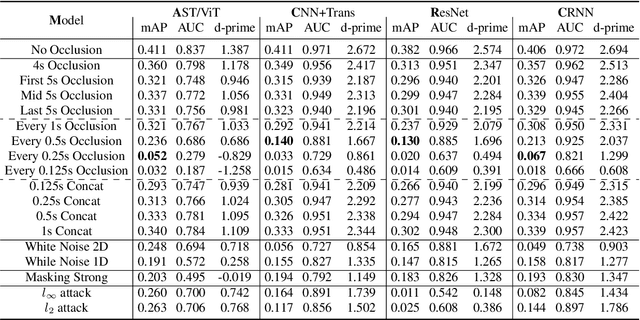
Traditionally, in Audio Recognition pipeline, noise is suppressed by the "frontend", relying on preprocessing techniques such as speech enhancement. However, it is not guaranteed that noise will not cascade into downstream pipelines. To understand the actual influence of noise on the entire audio pipeline, in this paper, we directly investigate the impact of noise on a different types of neural models without the preprocessing step. We measure the recognition performances of 4 different neural network models on the task of environment sound classification under the 3 types of noises: \emph{occlusion} (to emulate intermittent noise), \emph{Gaussian} noise (models continuous noise), and \emph{adversarial perturbations} (worst case scenario). Our intuition is that the different ways in which these models process their input (i.e. CNNs have strong locality inductive biases, which Transformers do not have) should lead to observable differences in performance and/ or robustness, an understanding of which will enable further improvements. We perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available. We also seek to explain the behaviors of different models through output distribution change and weight visualization.
AudioTagging Done Right: 2nd comparison of deep learning methods for environmental sound classification
Apr 03, 2022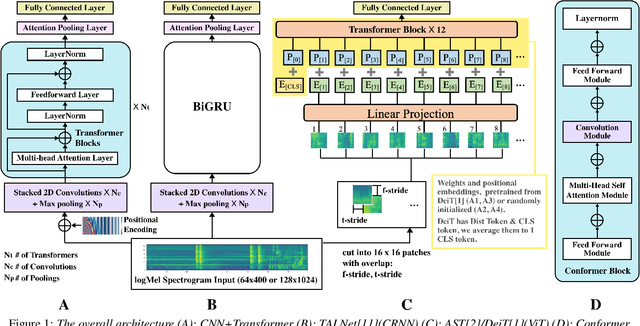
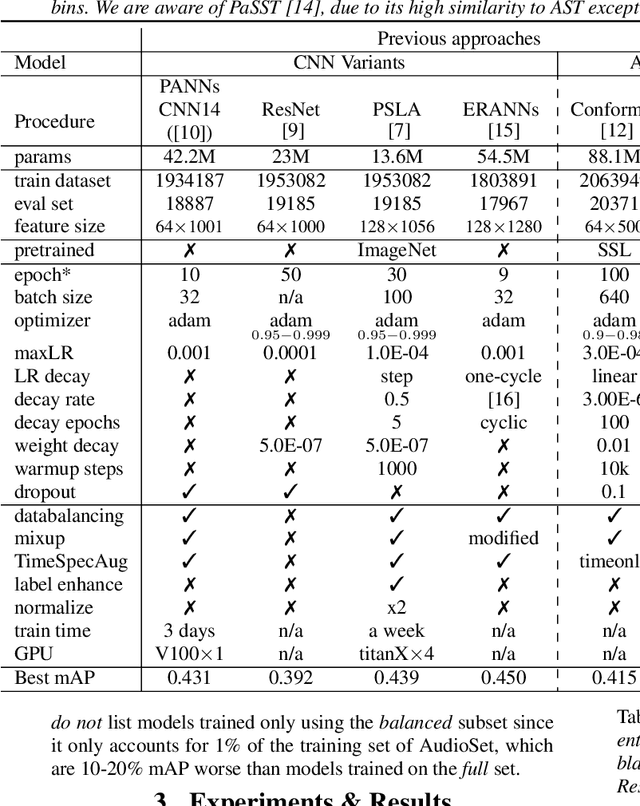
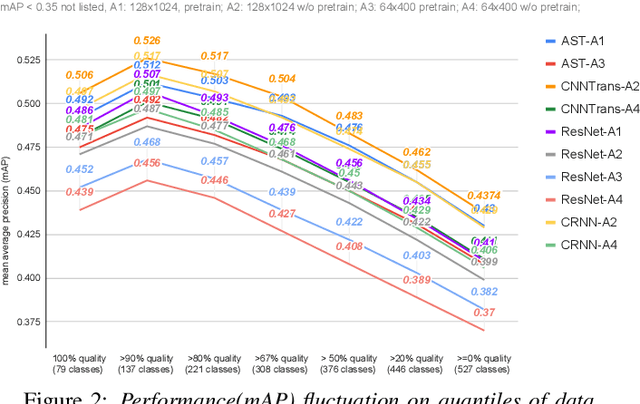

After its sweeping success in vision and language tasks, pure attention-based neural architectures (e.g. DeiT) are emerging to the top of audio tagging (AT) leaderboards, which seemingly obsoletes traditional convolutional neural networks (CNNs), feed-forward networks or recurrent networks. However, taking a closer look, there is great variability in published research, for instance, performances of models initialized with pretrained weights differ drastically from without pretraining, training time for a model varies from hours to weeks, and often, essences are hidden in seemingly trivial details. This urgently calls for a comprehensive study since our 1st comparison is half-decade old. In this work, we perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available, we also did an analysis based on the data quality and efficiency. We compare a few state-of-the-art baselines on the AT task, and study the performance and efficiency of 2 major categories of neural architectures: CNN variants and attention-based variants. We also closely examine their optimization procedures. Our opensourced experimental results provide insights to trade-off between performance, efficiency, optimization process, for both practitioners and researchers. Implementation: https://github.com/lijuncheng16/AudioTaggingDoneRight
On Adversarial Robustness of Large-scale Audio Visual Learning
Mar 23, 2022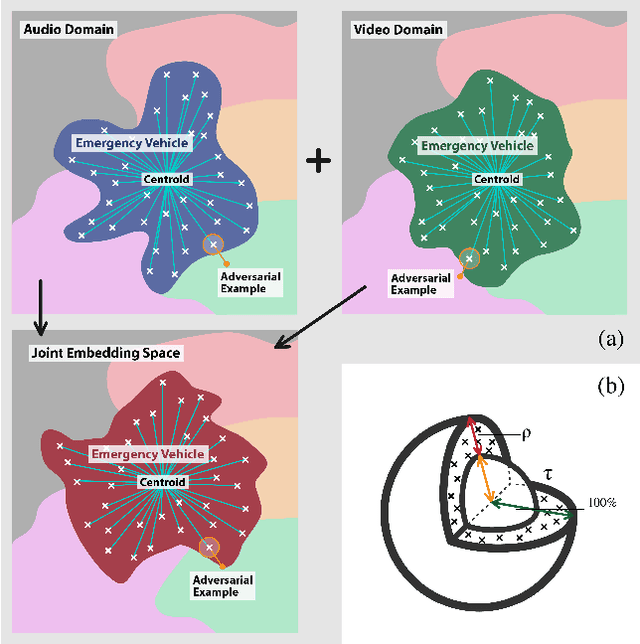
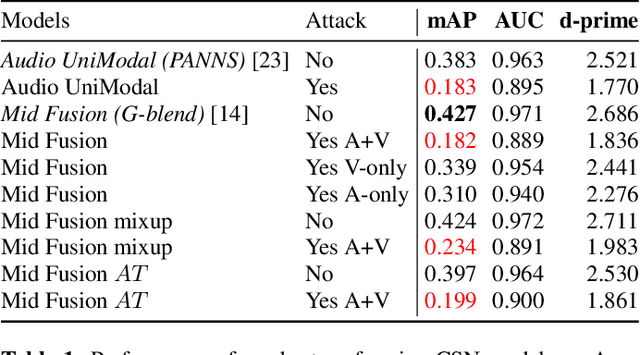
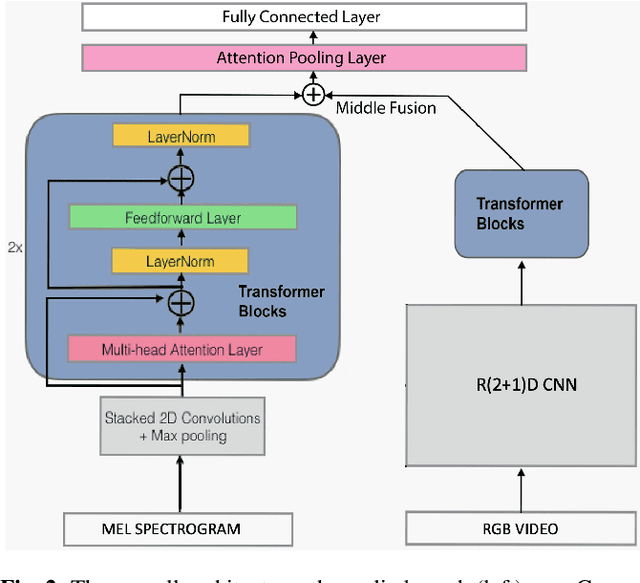
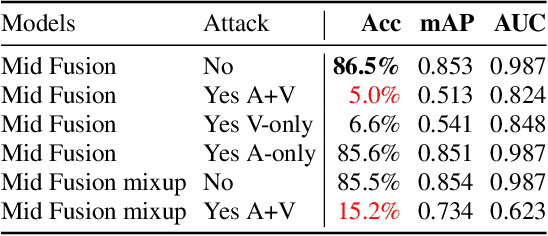
As audio-visual systems are being deployed for safety-critical tasks such as surveillance and malicious content filtering, their robustness remains an under-studied area. Existing published work on robustness either does not scale to large-scale dataset, or does not deal with multiple modalities. This work aims to study several key questions related to multi-modal learning through the lens of robustness: 1) Are multi-modal models necessarily more robust than uni-modal models? 2) How to efficiently measure the robustness of multi-modal learning? 3) How to fuse different modalities to achieve a more robust multi-modal model? To understand the robustness of the multi-modal model in a large-scale setting, we propose a density-based metric, and a convexity metric to efficiently measure the distribution of each modality in high-dimensional latent space. Our work provides a theoretical intuition together with empirical evidence showing how multi-modal fusion affects adversarial robustness through these metrics. We further devise a mix-up strategy based on our metrics to improve the robustness of the trained model. Our experiments on AudioSet and Kinetics-Sounds verify our hypothesis that multi-modal models are not necessarily more robust than their uni-modal counterparts in the face of adversarial examples. We also observe our mix-up trained method could achieve as much protection as traditional adversarial training, offering a computationally cheap alternative. Implementation: https://github.com/lijuncheng16/AudioSetDoneRight
Audio-Visual Event Recognition through the lens of Adversary
Nov 15, 2020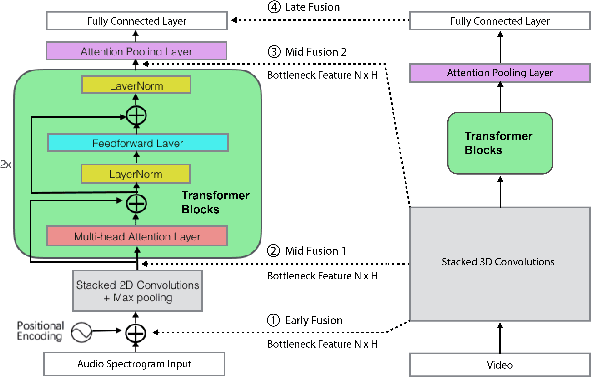
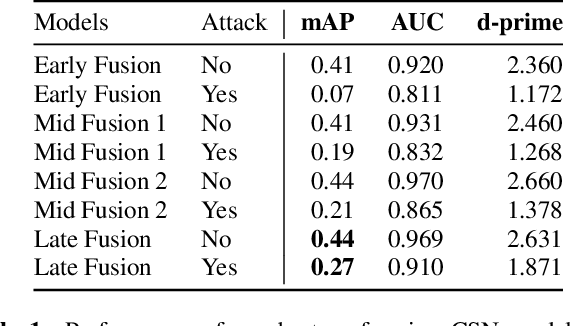
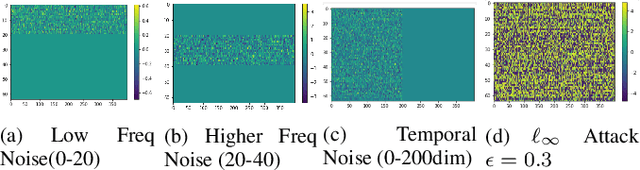
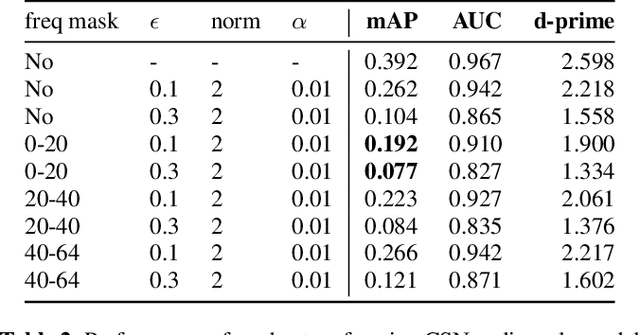
As audio/visual classification models are widely deployed for sensitive tasks like content filtering at scale, it is critical to understand their robustness along with improving the accuracy. This work aims to study several key questions related to multimodal learning through the lens of adversarial noises: 1) The trade-off between early/middle/late fusion affecting its robustness and accuracy 2) How do different frequency/time domain features contribute to the robustness? 3) How do different neural modules contribute to the adversarial noise? In our experiment, we construct adversarial examples to attack state-of-the-art neural models trained on Google AudioSet. We compare how much attack potency in terms of adversarial perturbation of size $\epsilon$ using different $L_p$ norms we would need to "deactivate" the victim model. Using adversarial noise to ablate multimodal models, we are able to provide insights into what is the best potential fusion strategy to balance the model parameters/accuracy and robustness trade-off and distinguish the robust features versus the non-robust features that various neural networks model tend to learn.