 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrativeTrack: Evaluating Video Language Models Beyond the Frame
Jan 03, 2026Multimodal large language models (MLLMs) have achieved impressive progress in vision-language reasoning, yet their ability to understand temporally unfolding narratives in videos remains underexplored. True narrative understanding requires grounding who is doing what, when, and where, maintaining coherent entity representations across dynamic visual and temporal contexts. We introduce NarrativeTrack, the first benchmark to evaluate narrative understanding in MLLMs through fine-grained entity-centric reasoning. Unlike existing benchmarks limited to short clips or coarse scene-level semantics, we decompose videos into constituent entities and examine their continuity via a Compositional Reasoning Progression (CRP), a structured evaluation framework that progressively increases narrative complexity across three dimensions: entity existence, entity changes, and entity ambiguity. CRP challenges models to advance from temporal persistence to contextual evolution and fine-grained perceptual reasoning. A fully automated entity-centric pipeline enables scalable extraction of temporally grounded entity representations, providing the foundation for CRP. Evaluations of state-of-the-art MLLMs reveal that models fail to robustly track entities across visual transitions and temporal dynamics, often hallucinating identity under context shifts. Open-source general-purpose MLLMs exhibit strong perceptual grounding but weak temporal coherence, while video-specific MLLMs capture temporal context yet hallucinate entity's contexts. These findings uncover a fundamental trade-off between perceptual grounding and temporal reasoning, indicating that narrative understanding emerges only from their integration. NarrativeTrack provides the first systematic framework to diagnose and advance temporally grounded narrative comprehension in MLLMs.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models
May 28, 2025Recent Large Vision-Language Models (LVLMs) have advanced multi-modal understanding by incorporating finer-grained visual perception and encoding. However, such methods incur significant computational costs due to longer visual token sequences, posing challenges for real-time deployment. To mitigate this, prior studies have explored pruning unimportant visual tokens either at the output layer of the visual encoder or at the early layers of the language model. In this work, we revisit these design choices and reassess their effectiveness through comprehensive empirical studies of how visual tokens are processed throughout the visual encoding and language decoding stages. Guided by these insights, we propose VScan, a two-stage visual token reduction framework that addresses token redundancy by: (1) integrating complementary global and local scans with token merging during visual encoding, and (2) introducing pruning at intermediate layers of the language model. Extensive experimental results across four LVLMs validate the effectiveness of VScan in accelerating inference and demonstrate its superior performance over current state-of-the-arts on sixteen benchmarks. Notably, when applied to LLaVA-NeXT-7B, VScan achieves a 2.91$\times$ speedup in prefilling and a 10$\times$ reduction in FLOPs, while retaining 95.4% of the original performance.
WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model
Apr 23, 2025Agent self-improvement, where the backbone Large Language Model (LLM) of the agent are trained on trajectories sampled autonomously based on their own policies, has emerged as a promising approach for enhancing performance. Recent advancements, particularly in web environments, face a critical limitation: their performance will reach a stagnation point during autonomous learning cycles, hindering further improvement. We argue that this stems from limited exploration of the web environment and insufficient exploitation of pre-trained web knowledge in LLMs. To improve the performance of self-improvement, we propose a novel framework that introduces a co-evolving World Model LLM. This world model predicts the next observation based on the current observation and action within the web environment. Leveraging LLMs' pretrained knowledge of abundant web content, the World Model serves dual roles: (1) as a virtual web server generating self-instructed training data to continuously refine the agent's policy, and (2) as an imagination engine during inference, enabling look-ahead simulation to guide action selection for the agent LLM. Experiments in real-world web environments (Mind2Web-Live, WebVoyager, and GAIA-web) show a 10% performance gain over existing self-evolving agents, demonstrating the efficacy and generalizability of our approach, without using any distillation from more powerful close-sourced models. Our work establishes the necessity of integrating world models into autonomous agent frameworks to unlock sustained adaptability.
Enhancing Web Agents with Explicit Rollback Mechanisms
Apr 16, 2025With recent advancements in large language models, web agents have been greatly improved. However, dealing with complex and dynamic web environments requires more advanced planning and search abilities. Previous studies usually adopt a greedy one-way search strategy, which may struggle to recover from erroneous states. In this work, we enhance web agents with an explicit rollback mechanism, enabling the agent to revert back to a previous state in its navigation trajectory. This mechanism gives the model the flexibility to directly control the search process, leading to an effective and efficient web navigation method. We conduct experiments on two live web navigation benchmarks with zero-shot and fine-tuning settings. The results demonstrate the effectiveness of our proposed approach.
OpenWebVoyager: Building Multimodal Web Agents via Iterative Real-World Exploration, Feedback and Optimization
Oct 25, 2024



The rapid development of large language and multimodal models has sparked significant interest in using proprietary models, such as GPT-4o, to develop autonomous agents capable of handling real-world scenarios like web navigation. Although recent open-source efforts have tried to equip agents with the ability to explore environments and continuously improve over time, they are building text-only agents in synthetic environments where the reward signals are clearly defined. Such agents struggle to generalize to realistic settings that require multimodal perception abilities and lack ground-truth signals. In this paper, we introduce an open-source framework designed to facilitate the development of multimodal web agent that can autonomously conduct real-world exploration and improve itself. We first train the base model with imitation learning to gain the basic abilities. We then let the agent explore the open web and collect feedback on its trajectories. After that, it further improves its policy by learning from well-performing trajectories judged by another general-purpose model. This exploration-feedback-optimization cycle can continue for several iterations. Experimental results show that our web agent successfully improves itself after each iteration, demonstrating strong performance across multiple test sets.
DivScene: Benchmarking LVLMs for Object Navigation with Diverse Scenes and Objects
Oct 03, 2024

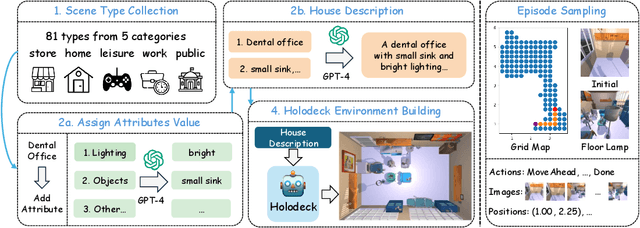

Object navigation in unknown environments is crucial for deploying embodied agents in real-world applications. While we have witnessed huge progress due to large-scale scene datasets, faster simulators, and stronger models, previous studies mainly focus on limited scene types and target objects. In this paper, we study a new task of navigating to diverse target objects in a large number of scene types. To benchmark the problem, we present a large-scale scene dataset, DivScene, which contains 4,614 scenes across 81 different types. With the dataset, we build an end-to-end embodied agent, NatVLM, by fine-tuning a Large Vision Language Model (LVLM) through imitation learning. The LVLM is trained to take previous observations from the environment and generate the next actions. We also introduce CoT explanation traces of the action prediction for better performance when tuning LVLMs. Our extensive experiments find that we can build a performant LVLM-based agent through imitation learning on the shortest paths constructed by a BFS planner without any human supervision. Our agent achieves a success rate that surpasses GPT-4o by over 20%. Meanwhile, we carry out various analyses showing the generalization ability of our agent.
LEOPARD : A Vision Language Model For Text-Rich Multi-Image Tasks
Oct 02, 2024Text-rich images, where text serves as the central visual element guiding the overall understanding, are prevalent in real-world applications, such as presentation slides, scanned documents, and webpage snapshots. Tasks involving multiple text-rich images are especially challenging, as they require not only understanding the content of individual images but reasoning about inter-relationships and logical flows across multiple visual inputs. Despite the importance of these scenarios, current multimodal large language models (MLLMs) struggle to handle such tasks due to two key challenges: (1) the scarcity of high-quality instruction tuning datasets for text-rich multi-image scenarios, and (2) the difficulty in balancing image resolution with visual feature sequence length. To address these challenges, we propose \OurMethod, a MLLM designed specifically for handling vision-language tasks involving multiple text-rich images. First, we curated about one million high-quality multimodal instruction-tuning data, tailored to text-rich, multi-image scenarios. Second, we developed an adaptive high-resolution multi-image encoding module to dynamically optimize the allocation of visual sequence length based on the original aspect ratios and resolutions of the input images. Experiments across a wide range of benchmarks demonstrate our model's superior capabilities in text-rich, multi-image evaluations and competitive performance in general domain evaluations.
Cognitive Kernel: An Open-source Agent System towards Generalist Autopilots
Sep 16, 2024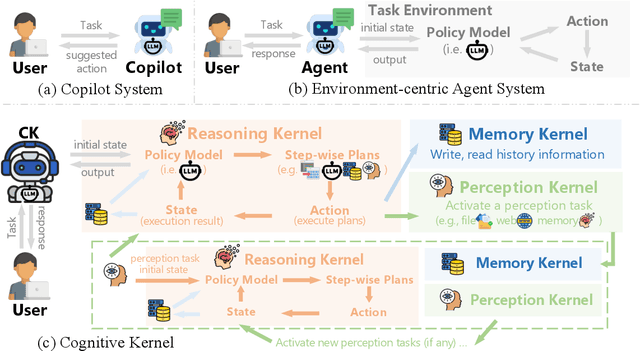



We introduce Cognitive Kernel, an open-source agent system towards the goal of generalist autopilots. Unlike copilot systems, which primarily rely on users to provide essential state information (e.g., task descriptions) and assist users by answering questions or auto-completing contents, autopilot systems must complete tasks from start to finish independently, which requires the system to acquire the state information from the environments actively. To achieve this, an autopilot system should be capable of understanding user intents, actively gathering necessary information from various real-world sources, and making wise decisions. Cognitive Kernel adopts a model-centric design. In our implementation, the central policy model (a fine-tuned LLM) initiates interactions with the environment using a combination of atomic actions, such as opening files, clicking buttons, saving intermediate results to memory, or calling the LLM itself. This differs from the widely used environment-centric design, where a task-specific environment with predefined actions is fixed, and the policy model is limited to selecting the correct action from a given set of options. Our design facilitates seamless information flow across various sources and provides greater flexibility. We evaluate our system in three use cases: real-time information management, private information management, and long-term memory management. The results demonstrate that Cognitive Kernel achieves better or comparable performance to other closed-source systems in these scenarios. Cognitive Kernel is fully dockerized, ensuring everyone can deploy it privately and securely. We open-source the system and the backbone model to encourage further research on LLM-driven autopilot systems.
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?
Sep 12, 2024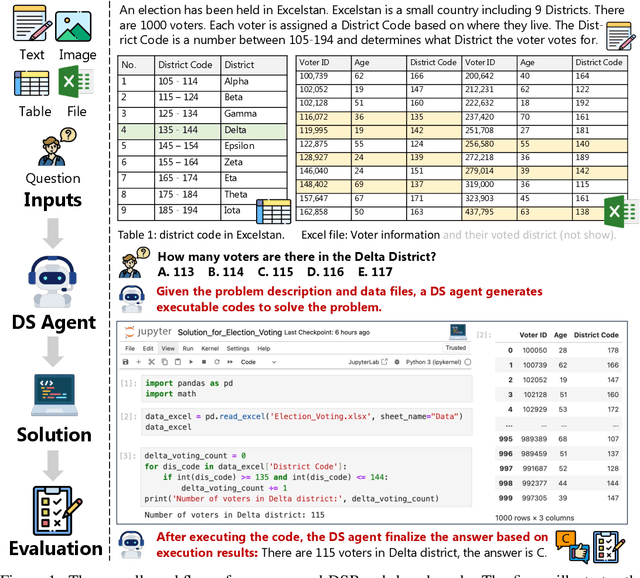
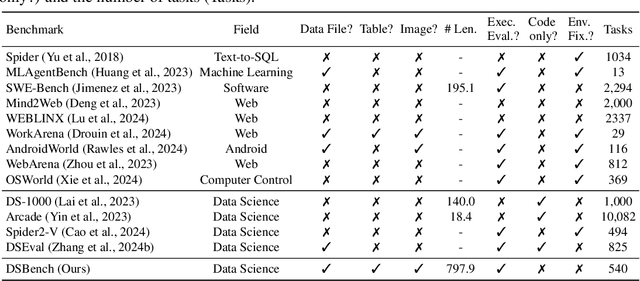
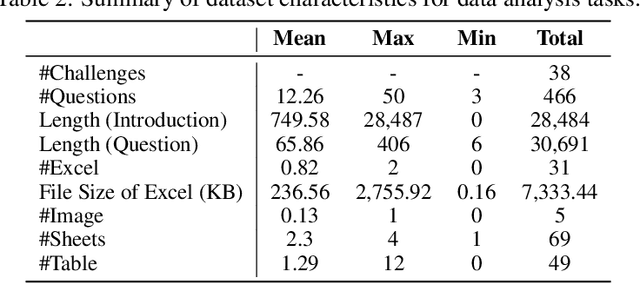
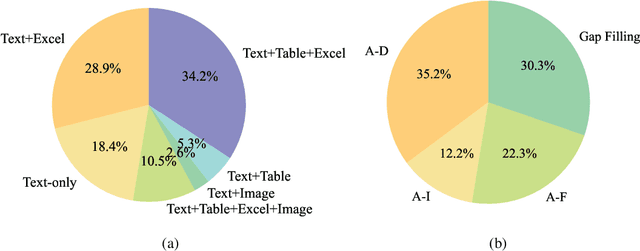
Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers. Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings. To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks. Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.