 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping the Mode Lottery: Multi-Response Training Improves Language Model Generalization
May 30, 2026Modern language-model fine-tuning typically pairs each prompt with a single response, even though many prompts admit multiple valid completions. This effectively reduces a multi-modal conditional distribution to a one-sample view, a phenomenon we call the "mode lottery," where training emphasizes a subset of plausible modes while leaving others underrepresented. We study multi-response training (MRT), which retains multiple responses per prompt, and develop a principled account of when and why it helps. Our key insight is that prompts and responses are distinct statistical resources: additional prompts reduce uncertainty about the input distribution, while additional responses reduce uncertainty about the conditional output distribution. This yields a variance-budget tradeoff that predicts when retaining multiple responses is worthwhile, shows diminishing returns as prompt-level uncertainty dominates, and explains why large redundant corpora can exhibit an implicit multi-response effect. We further analyze response selection, and show that Random-K-of-N is the unbiased default for distributional fine-tuning, reward-based selection can induce mode collapse, and a submodular quality-diversity objective provides an efficient alternative with theoretical guarantees. Controlled simulations validate the predicted variance and selection effects, including a striking failure mode where reward-only selection produces gradients misaligned with the true objective. Across structured and real-world datasets, including a new multi-prompt, multi-response benchmark, MRT consistently improves distributional generalization, with the largest gains in high response-diversity, low prompt-redundancy regimes. MRT reframes response multiplicity as a data-allocation problem with clear guidance: when responses are cheap and diverse, keeping more than one is not a heuristic, but a statistically grounded choice.
Toward Better Temporal Structures for Geopolitical Events Forecasting
Jan 01, 2026Forecasting on geopolitical temporal knowledge graphs (TKGs) through the lens of large language models (LLMs) has recently gained traction. While TKGs and their generalization, hyper-relational temporal knowledge graphs (HTKGs), offer a straightforward structure to represent simple temporal relationships, they lack the expressive power to convey complex facts efficiently. One of the critical limitations of HTKGs is a lack of support for more than two primary entities in temporal facts, which commonly occur in real-world events. To address this limitation, in this work, we study a generalization of HTKGs, Hyper-Relational Temporal Knowledge Generalized Hypergraphs (HTKGHs). We first derive a formalization for HTKGHs, demonstrating their backward compatibility while supporting two complex types of facts commonly found in geopolitical incidents. Then, utilizing this formalization, we introduce the htkgh-polecat dataset, built upon the global event database POLECAT. Finally, we benchmark and analyze popular LLMs on the relation prediction task, providing insights into their adaptability and capabilities in complex forecasting scenarios.
A Systematic Analysis of Base Model Choice for Reward Modeling
May 16, 2025Reinforcement learning from human feedback (RLHF) and, at its core, reward modeling have become a crucial part of training powerful large language models (LLMs). One commonly overlooked factor in training high-quality reward models (RMs) is the effect of the base model, which is becoming more challenging to choose given the rapidly growing pool of LLMs. In this work, we present a systematic analysis of the effect of base model selection on reward modeling performance. Our results show that the performance can be improved by up to 14% compared to the most common (i.e., default) choice. Moreover, we showcase the strong statistical relation between some existing benchmarks and downstream performances. We also demonstrate that the results from a small set of benchmarks could be combined to boost the model selection ($+$18% on average in the top 5-10). Lastly, we illustrate the impact of different post-training steps on the final performance and explore using estimated data distributions to reduce performance prediction error.
On The Adaptation of Unlimiformer for Decoder-Only Transformers
Oct 02, 2024
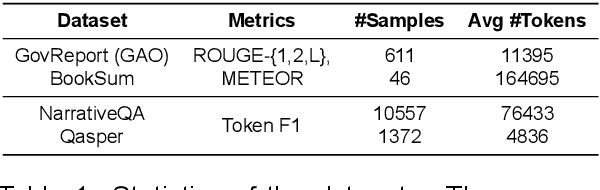

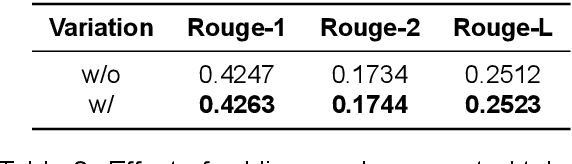
One of the prominent issues stifling the current generation of large language models is their limited context length. Recent proprietary models such as GPT-4 and Claude 2 have introduced longer context lengths, 8k/32k and 100k, respectively; however, despite the efforts in the community, most common models, such as LLama-2, have a context length of 4k or less. Unlimiformer (Bertsch et al., 2023) is a recently popular vector-retrieval augmentation method that offloads cross-attention computations to a kNN index. However, its main limitation is incompatibility with decoder-only transformers out of the box. In this work, we explore practical considerations of adapting Unlimiformer to decoder-only transformers and introduce a series of modifications to overcome this limitation. Moreover, we expand the original experimental setup on summarization to include a new task (i.e., free-form Q&A) and an instruction-tuned model (i.e., a custom 6.7B GPT model). Our results showcase the effectiveness of these modifications on summarization, performing on par with a model with 2x the context length. Moreover, we discuss limitations and future directions for free-form Q&A and instruction-tuned models.
The Hitchhiker's Guide to Human Alignment with *PO
Jul 21, 2024With the growing utilization of large language models (LLMs) across domains, alignment towards human preferences has become one of the most critical aspects of training models. At the forefront of state-of-the-art human alignment methods are preference optimization methods (*PO). However, prior research has often concentrated on identifying the best-performing method, typically involving a grid search over hyperparameters, which can be impractical for general practitioners. In this paper, we aim to identify the algorithm that, while being performant, is simultaneously more robust to varying hyperparameters, thereby increasing the likelihood of achieving better results. We focus on a realistic out-of-distribution (OOD) scenario that mirrors real-world applications of human alignment, offering practical insights into the strengths and weaknesses of these methods. Furthermore, to better understand the shortcomings of generations from the different methods, we analyze the model generations through the lens of KL divergence of the SFT model and the response length statistics. Our analysis reveals that the widely adopted DPO method consistently produces lengthy responses of inferior quality that are very close to the SFT responses. Motivated by these findings, we propose an embarrassingly simple extension to the DPO algorithm, LN-DPO, resulting in more concise responses without sacrificing quality compared to the policy obtained by vanilla DPO.
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
Apr 24, 2024



While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Jan 22, 2024
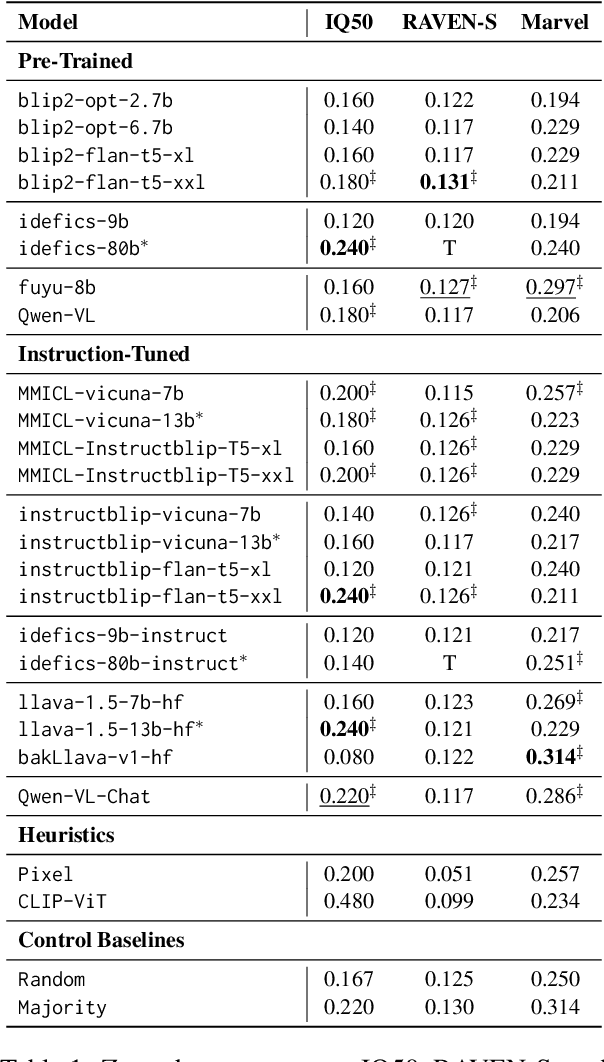


While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments expose the difficulty of solving such problems while showcasing the immense gap between open-source and closed-source models. We also reveal critical shortcomings with individual visual and textual modules, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with various methods, such as Chain-of-Thought prompting, resulting in a significant (up to 100%) boost in performance.
Temporal Knowledge Graph Forecasting Without Knowledge Using In-Context Learning
May 17, 2023Temporal knowledge graph (TKG) forecasting benchmarks challenge models to predict future facts using knowledge of past facts. In this paper, we apply large language models (LLMs) to these benchmarks using in-context learning (ICL). We investigate whether and to what extent LLMs can be used for TKG forecasting, especially without any fine-tuning or explicit modules for capturing structural and temporal information. For our experiments, we present a framework that converts relevant historical facts into prompts and generates ranked predictions using token probabilities. Surprisingly, we observe that LLMs, out-of-the-box, perform on par with state-of-the-art TKG models carefully designed and trained for TKG forecasting. Our extensive evaluation presents performances across several models and datasets with different characteristics, compares alternative heuristics for preparing contextual information, and contrasts to prominent TKG methods and simple frequency and recency baselines. We also discover that using numerical indices instead of entity/relation names, i.e., hiding semantic information, does not significantly affect the performance ($\pm$0.4\% Hit@1). This shows that prior semantic knowledge is unnecessary; instead, LLMs can leverage the existing patterns in the context to achieve such performance. Our analysis also reveals that ICL enables LLMs to learn irregular patterns from the historical context, going beyond simple predictions based on common or recent information.
PubGraph: A Large Scale Scientific Temporal Knowledge Graph
Feb 04, 2023


Research publications are the primary vehicle for sharing scientific progress in the form of new discoveries, methods, techniques, and insights. Publications have been studied from the perspectives of both content analysis and bibliometric structure, but a barrier to more comprehensive studies of scientific research is a lack of publicly accessible large-scale data and resources. In this paper, we present PubGraph, a new resource for studying scientific progress that takes the form of a large-scale temporal knowledge graph (KG). It contains more than 432M nodes and 15.49B edges mapped to the popular Wikidata ontology. We extract three KGs with varying sizes from PubGraph to allow experimentation at different scales. Using these KGs, we introduce a new link prediction benchmark for transductive and inductive settings with temporally-aligned training, validation, and testing partitions. Moreover, we develop two new inductive learning methods better suited to PubGraph, operating on unseen nodes without explicit features, scaling to large KGs, and outperforming existing models. Our results demonstrate that structural features of past citations are sufficient to produce high-quality predictions about new publications. We also identify new challenges for KG models, including an adversarial community-based link prediction setting, zero-shot inductive learning, and large-scale learning.
Structure Aware Negative Sampling in Knowledge Graphs
Oct 07, 2020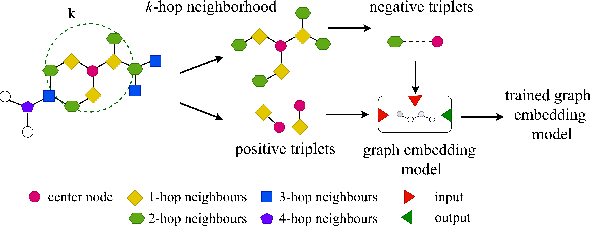
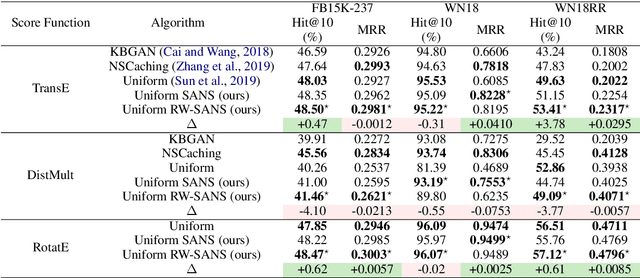
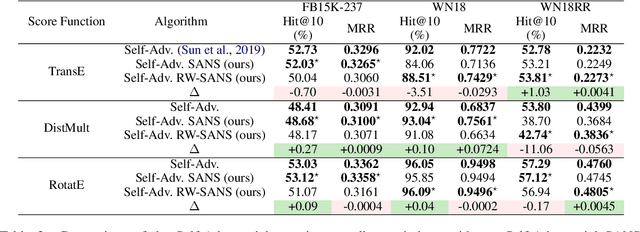
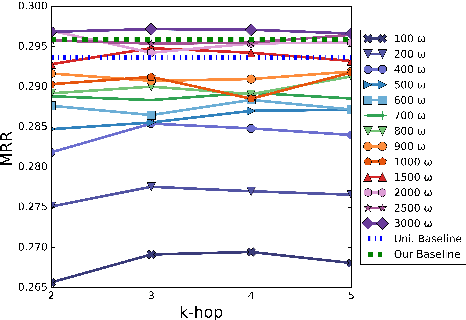
Learning low-dimensional representations for entities and relations in knowledge graphs using contrastive estimation represents a scalable and effective method for inferring connectivity patterns. A crucial aspect of contrastive learning approaches is the choice of corruption distribution that generates hard negative samples, which force the embedding model to learn discriminative representations and find critical characteristics of observed data. While earlier methods either employ too simple corruption distributions, i.e. uniform, yielding easy uninformative negatives or sophisticated adversarial distributions with challenging optimization schemes, they do not explicitly incorporate known graph structure resulting in suboptimal negatives. In this paper, we propose Structure Aware Negative Sampling (SANS), an inexpensive negative sampling strategy that utilizes the rich graph structure by selecting negative samples from a node's k-hop neighborhood. Empirically, we demonstrate that SANS finds semantically meaningful negatives and is competitive with SOTA approaches while requires no additional parameters nor difficult adversarial optimization.