 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubGraph: A Large Scale Scientific Temporal Knowledge Graph
Feb 04, 2023
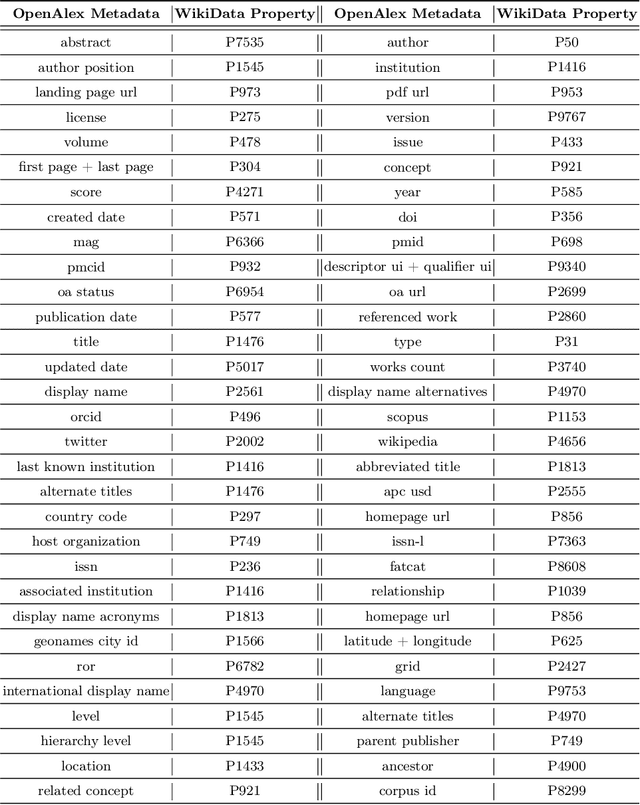


Research publications are the primary vehicle for sharing scientific progress in the form of new discoveries, methods, techniques, and insights. Publications have been studied from the perspectives of both content analysis and bibliometric structure, but a barrier to more comprehensive studies of scientific research is a lack of publicly accessible large-scale data and resources. In this paper, we present PubGraph, a new resource for studying scientific progress that takes the form of a large-scale temporal knowledge graph (KG). It contains more than 432M nodes and 15.49B edges mapped to the popular Wikidata ontology. We extract three KGs with varying sizes from PubGraph to allow experimentation at different scales. Using these KGs, we introduce a new link prediction benchmark for transductive and inductive settings with temporally-aligned training, validation, and testing partitions. Moreover, we develop two new inductive learning methods better suited to PubGraph, operating on unseen nodes without explicit features, scaling to large KGs, and outperforming existing models. Our results demonstrate that structural features of past citations are sufficient to produce high-quality predictions about new publications. We also identify new challenges for KG models, including an adversarial community-based link prediction setting, zero-shot inductive learning, and large-scale learning.
The Influence of Data Pre-processing and Post-processing on Long Document Summarization
Dec 03, 2021

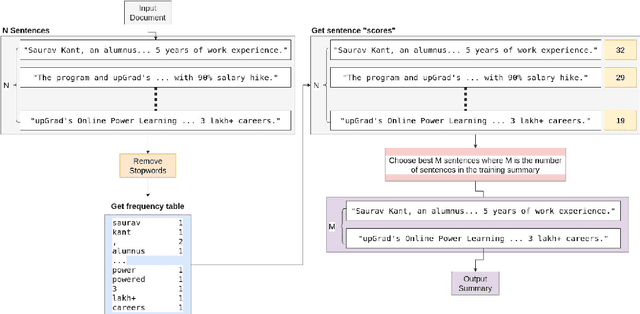
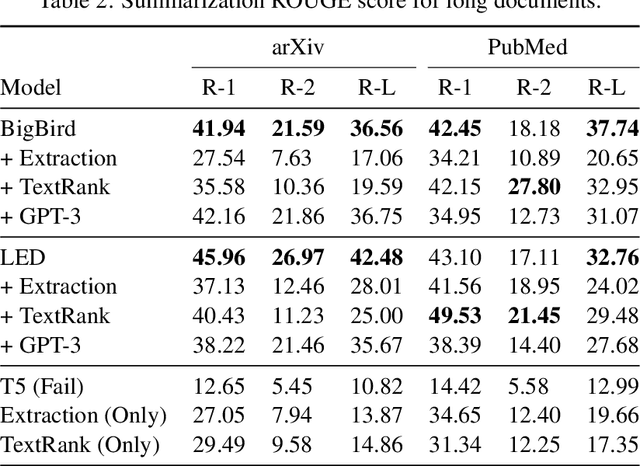
Long document summarization is an important and hard task in the field of natural language processing. A good performance of the long document summarization reveals the model has a decent understanding of the human language. Currently, most researches focus on how to modify the attention mechanism of the transformer to achieve a higher ROUGE score. The study of data pre-processing and post-processing are relatively few. In this paper, we use two pre-processing methods and a post-processing method and analyze the effect of these methods on various long document summarization models.