Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Influence of Data Pre-processing and Post-processing on Long Document Summarization
Dec 03, 2021

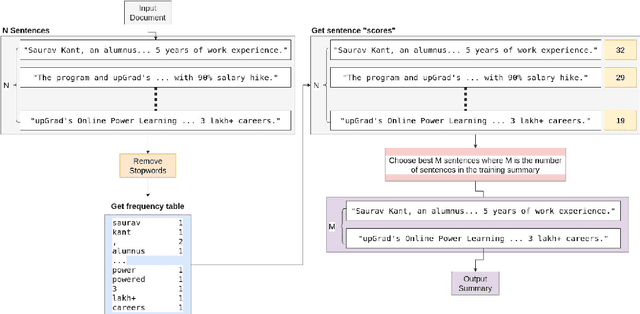
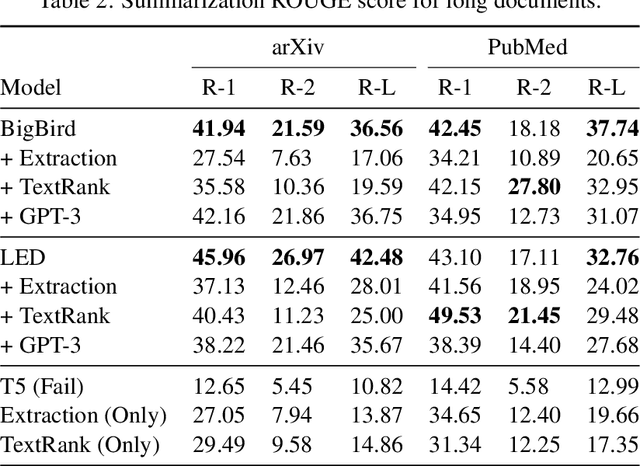
Long document summarization is an important and hard task in the field of natural language processing. A good performance of the long document summarization reveals the model has a decent understanding of the human language. Currently, most researches focus on how to modify the attention mechanism of the transformer to achieve a higher ROUGE score. The study of data pre-processing and post-processing are relatively few. In this paper, we use two pre-processing methods and a post-processing method and analyze the effect of these methods on various long document summarization models.
Via