 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Narrative is it Anyway? A KV Cache Manipulation Attack
Nov 16, 2025The Key Value(KV) cache is an important component for efficient inference in autoregressive Large Language Models (LLMs), but its role as a representation of the model's internal state makes it a potential target for integrity attacks. This paper introduces "History Swapping," a novel block-level attack that manipulates the KV cache to steer model generation without altering the user-facing prompt. The attack involves overwriting a contiguous segment of the active generation's cache with a precomputed cache from a different topic. We empirically evaluate this method across 324 configurations on the Qwen 3 family of models, analyzing the impact of timing, magnitude, and layer depth of the cache overwrite. Our findings reveal that only full-layer overwrites can successfully hijack the conversation's topic, leading to three distinct behaviors: immediate and persistent topic shift, partial recovery, or a delayed hijack. Furthermore, we observe that high-level structural plans are encoded early in the generation process and local discourse structure is maintained by the final layers of the model. This work demonstrates that the KV cache is a significant vector for security analysis, as it encodes not just context but also topic trajectory and structural planning, making it a powerful interface for manipulating model behavior.
PubGraph: A Large Scale Scientific Temporal Knowledge Graph
Feb 04, 2023
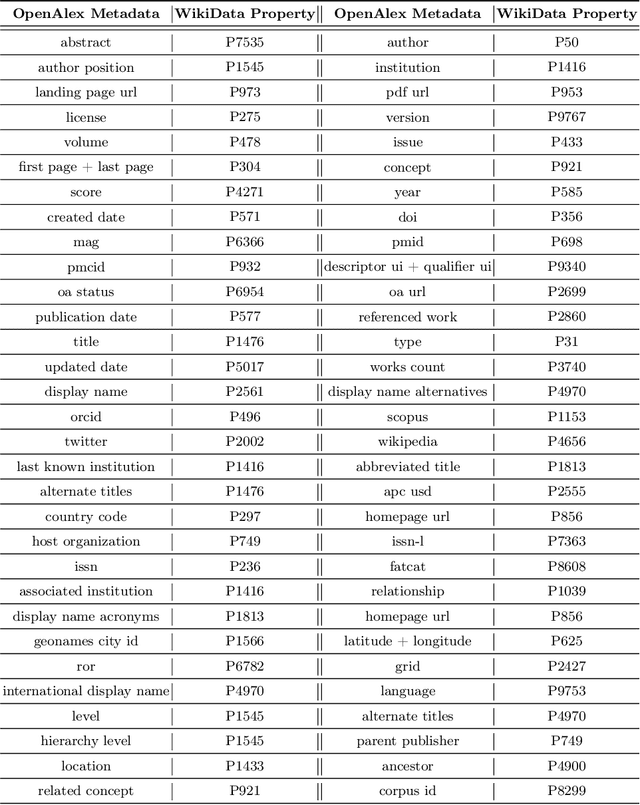


Research publications are the primary vehicle for sharing scientific progress in the form of new discoveries, methods, techniques, and insights. Publications have been studied from the perspectives of both content analysis and bibliometric structure, but a barrier to more comprehensive studies of scientific research is a lack of publicly accessible large-scale data and resources. In this paper, we present PubGraph, a new resource for studying scientific progress that takes the form of a large-scale temporal knowledge graph (KG). It contains more than 432M nodes and 15.49B edges mapped to the popular Wikidata ontology. We extract three KGs with varying sizes from PubGraph to allow experimentation at different scales. Using these KGs, we introduce a new link prediction benchmark for transductive and inductive settings with temporally-aligned training, validation, and testing partitions. Moreover, we develop two new inductive learning methods better suited to PubGraph, operating on unseen nodes without explicit features, scaling to large KGs, and outperforming existing models. Our results demonstrate that structural features of past citations are sufficient to produce high-quality predictions about new publications. We also identify new challenges for KG models, including an adversarial community-based link prediction setting, zero-shot inductive learning, and large-scale learning.