 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Emotion Recognition by Text, Speech and Video Using Pretrained Transformers
Feb 11, 2024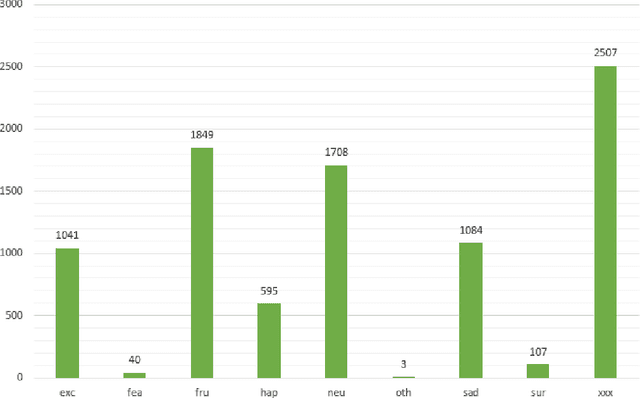
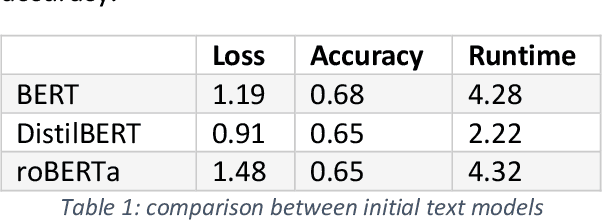
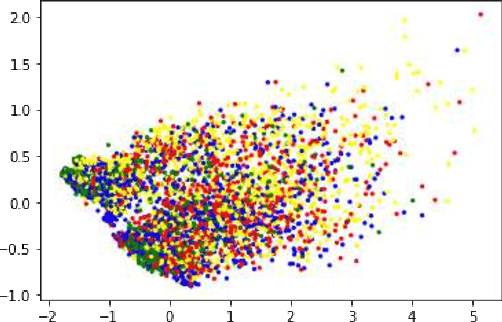
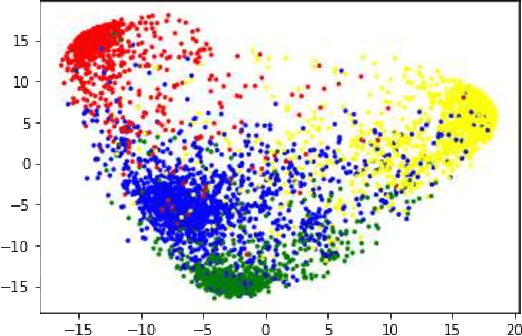
Due to the complex nature of human emotions and the diversity of emotion representation methods in humans, emotion recognition is a challenging field. In this research, three input modalities, namely text, audio (speech), and video, are employed to generate multimodal feature vectors. For generating features for each of these modalities, pre-trained Transformer models with fine-tuning are utilized. In each modality, a Transformer model is used with transfer learning to extract feature and emotional structure. These features are then fused together, and emotion recognition is performed using a classifier. To select an appropriate fusion method and classifier, various feature-level and decision-level fusion techniques have been experimented with, and ultimately, the best model, which combines feature-level fusion by concatenating feature vectors and classification using a Support Vector Machine on the IEMOCAP multimodal dataset, achieves an accuracy of 75.42%. Keywords: Multimodal Emotion Recognition, IEMOCAP, Self-Supervised Learning, Transfer Learning, Transformer.
Persian Speech Emotion Recognition by Fine-Tuning Transformers
Feb 11, 2024


Given the significance of speech emotion recognition, numerous methods have been developed in recent years to create effective and efficient systems in this domain. One of these methods involves the use of pretrained transformers, fine-tuned to address this specific problem, resulting in high accuracy. Despite extensive discussions and global-scale efforts to enhance these systems, the application of this innovative and effective approach has received less attention in the context of Persian speech emotion recognition. In this article, we review the field of speech emotion recognition and its background, with an emphasis on the importance of employing transformers in this context. We present two models, one based on spectrograms and the other on the audio itself, fine-tuned using the shEMO dataset. These models significantly enhance the accuracy of previous systems, increasing it from approximately 65% to 80% on the mentioned dataset. Subsequently, to investigate the effect of multilinguality on the fine-tuning process, these same models are fine-tuned twice. First, they are fine-tuned using the English IEMOCAP dataset, and then they are fine-tuned with the Persian shEMO dataset. This results in an improved accuracy of 82% for the Persian emotion recognition system. Keywords: Persian Speech Emotion Recognition, shEMO, Self-Supervised Learning
Writer Identification and Writer Retrieval Based on NetVLAD with Re-ranking
Dec 20, 2020



This paper addresses writer identification and retrieval which is a challenging problem in the document analysis field. In this work, a novel pipeline is proposed for the problem by employing a unified neural network architecture consisting of the ResNet-20 as a feature extractor and an integrated NetVLAD layer, inspired by the vectors of locally aggregated descriptors (VLAD), in the head of the latter part. Having defined this architecture, triplet semi-hard loss function is used to directly learn an embedding for individual input image patches. Generalised max-pooling is used for the aggregation of embedded descriptors of each handwritten image. In the evaluation part, for identification and retrieval, re-ranking has been done based on query expansion and $k$-reciprocal nearest neighbours, and it is shown that the pipeline can benefit tremendously from this step. Experimental evaluation shows that our writer identification and writer retrieval pipeline is superior compared to the state-of-the-art pipelines, as our results on the publicly available ICDAR13 and CVL datasets set new standards by achieving 96.5% and 98.4% mAP, respectively.
A Multi-Modal Feature Embedding Approach to Diagnose Alzheimer Disease from Spoken Language
Oct 01, 2019
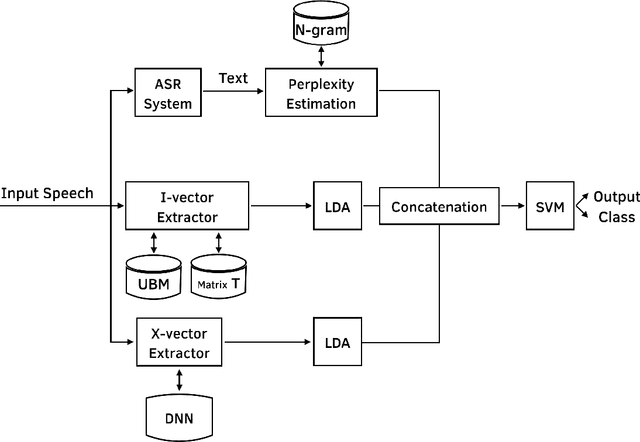


Introduction: Alzheimer's disease is a type of dementia in which early diagnosis plays a major rule in the quality of treatment. Among new works in the diagnosis of Alzheimer's disease, there are many of them analyzing the voice stream acoustically, syntactically or both. The mostly used tools to perform these analysis usually include machine learning techniques. Objective: Designing an automatic machine learning based diagnosis system will help in the procedure of early detection. Also, systems, using noninvasive data are preferable. Methods: We used are classification system based on spoken language. We use three (statistical and neural) approaches to classify audio signals from spoken language into two classes of dementia and control. Result: This work designs a multi-modal feature embedding on the spoken language audio signal using three approaches; N-gram, i-vector, and x-vector. The evaluation of the system is done on the cookie picture description task from Pitt Corpus dementia bank with the accuracy of 83:6
On Usage of Autoencoders and Siamese Networks for Online Handwritten Signature Verification
Dec 29, 2017
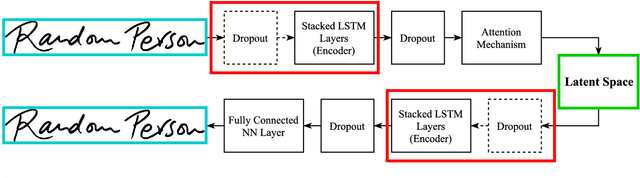


In this paper, we propose a novel writer-independent global feature extraction framework for the task of automatic signature verification which aims to make robust systems for automatically distinguishing negative and positive samples. Our method consists of an autoencoder for modeling the sample space into a fixed length latent space and a Siamese Network for classifying the fixed-length samples obtained from the autoencoder based on the reference samples of a subject as being "Genuine" or "Forged." During our experiments, usage of Attention Mechanism and applying Downsampling significantly improved the accuracy of the proposed framework. We evaluated our proposed framework using SigWiComp2013 Japanese and GPDSsyntheticOnLineOffLineSignature datasets. On the SigWiComp2013 Japanese dataset, we achieved 8.65% EER that means 1.2% relative improvement compared to the best-reported result. Furthermore, on the GPDSsyntheticOnLineOffLineSignature dataset, we achieved average EERs of 0.13%, 0.12%, 0.21% and 0.25% respectively for 150, 300, 1000 and 2000 test subjects which indicates improvement of relative EER on the best-reported result by 95.67%, 95.26%, 92.9% and 91.52% respectively. Apart from the accuracy gain, because of the nature of our proposed framework which is based on neural networks and consequently is as simple as some consecutive matrix multiplications, it has less computational cost than conventional methods such as DTW and could be used concurrently on devices such as GPU, TPU, etc.