 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Feature Embedding Approach to Diagnose Alzheimer Disease from Spoken Language
Oct 01, 2019
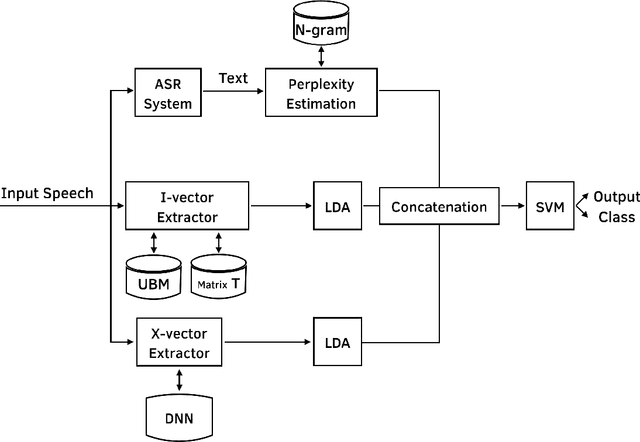


Introduction: Alzheimer's disease is a type of dementia in which early diagnosis plays a major rule in the quality of treatment. Among new works in the diagnosis of Alzheimer's disease, there are many of them analyzing the voice stream acoustically, syntactically or both. The mostly used tools to perform these analysis usually include machine learning techniques. Objective: Designing an automatic machine learning based diagnosis system will help in the procedure of early detection. Also, systems, using noninvasive data are preferable. Methods: We used are classification system based on spoken language. We use three (statistical and neural) approaches to classify audio signals from spoken language into two classes of dementia and control. Result: This work designs a multi-modal feature embedding on the spoken language audio signal using three approaches; N-gram, i-vector, and x-vector. The evaluation of the system is done on the cookie picture description task from Pitt Corpus dementia bank with the accuracy of 83:6