 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Paper and Code

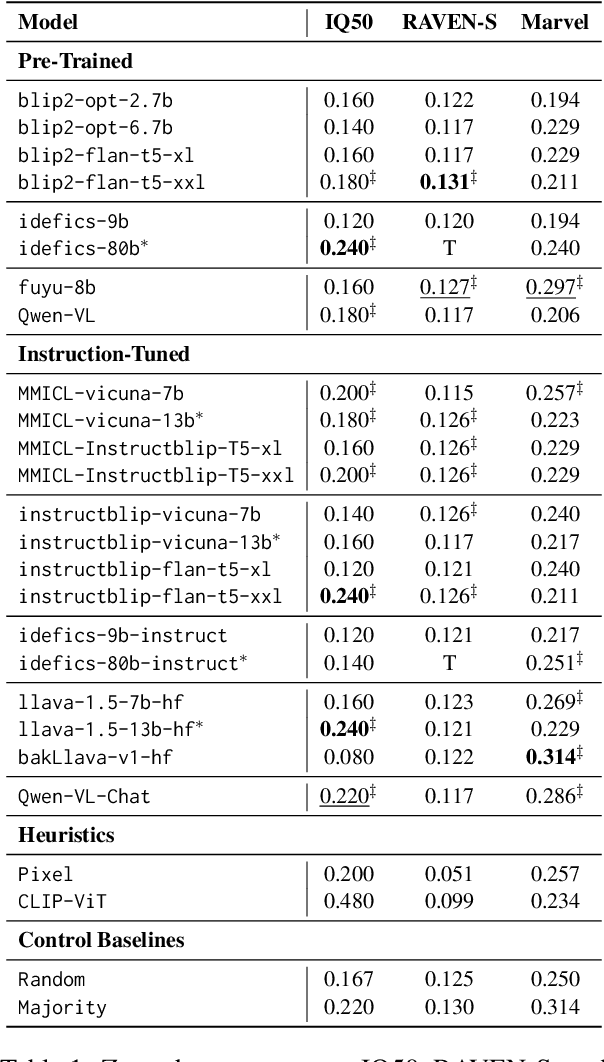


While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments expose the difficulty of solving such problems while showcasing the immense gap between open-source and closed-source models. We also reveal critical shortcomings with individual visual and textual modules, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with various methods, such as Chain-of-Thought prompting, resulting in a significant (up to 100%) boost in performance.