 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
On The Adaptation of Unlimiformer for Decoder-Only Transformers
Oct 02, 2024
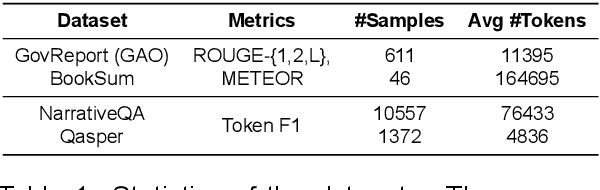

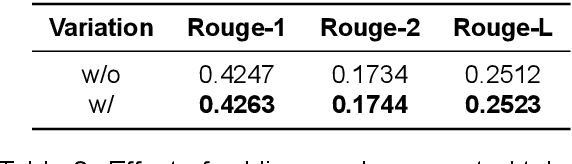
One of the prominent issues stifling the current generation of large language models is their limited context length. Recent proprietary models such as GPT-4 and Claude 2 have introduced longer context lengths, 8k/32k and 100k, respectively; however, despite the efforts in the community, most common models, such as LLama-2, have a context length of 4k or less. Unlimiformer (Bertsch et al., 2023) is a recently popular vector-retrieval augmentation method that offloads cross-attention computations to a kNN index. However, its main limitation is incompatibility with decoder-only transformers out of the box. In this work, we explore practical considerations of adapting Unlimiformer to decoder-only transformers and introduce a series of modifications to overcome this limitation. Moreover, we expand the original experimental setup on summarization to include a new task (i.e., free-form Q&A) and an instruction-tuned model (i.e., a custom 6.7B GPT model). Our results showcase the effectiveness of these modifications on summarization, performing on par with a model with 2x the context length. Moreover, we discuss limitations and future directions for free-form Q&A and instruction-tuned models.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023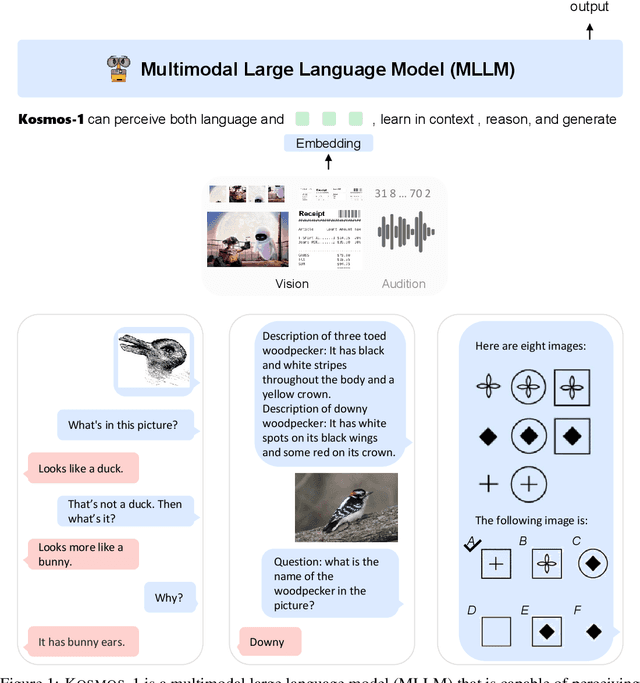
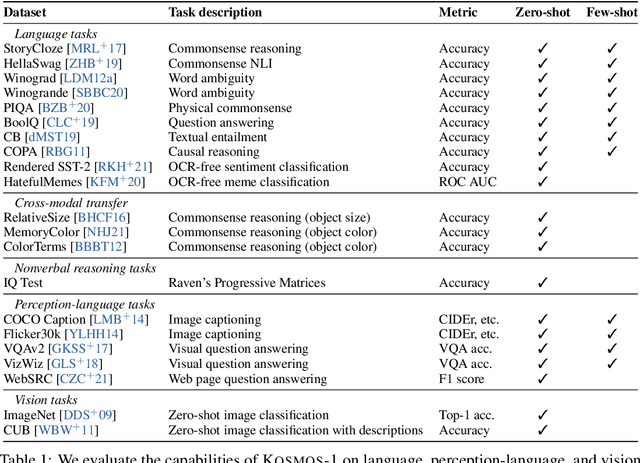

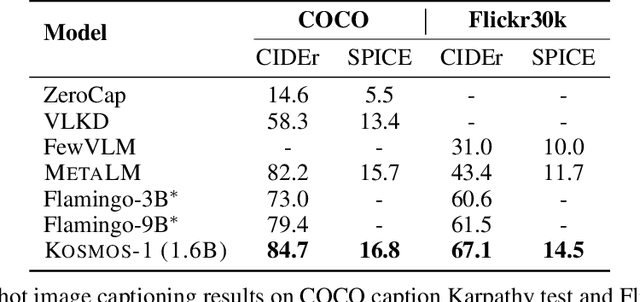
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Beyond English-Centric Bitexts for Better Multilingual Language Representation Learning
Oct 26, 2022


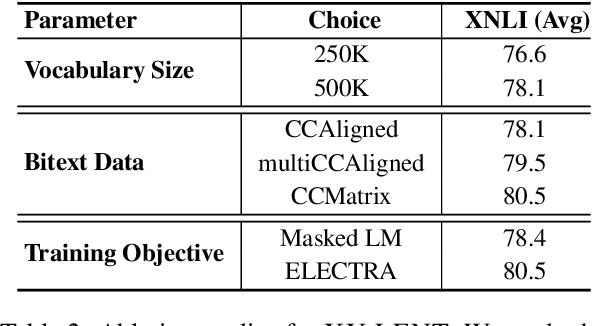
In this paper, we elaborate upon recipes for building multilingual representation models that are not only competitive with existing state-of-the-art models but are also more parameter efficient, thereby promoting better adoption in resource-constrained scenarios and practical applications. We show that going beyond English-centric bitexts, coupled with a novel sampling strategy aimed at reducing under-utilization of training data, substantially boosts performance across model sizes for both Electra and MLM pre-training objectives. We introduce XY-LENT: X-Y bitext enhanced Language ENcodings using Transformers which not only achieves state-of-the-art performance over 5 cross-lingual tasks within all model size bands, is also competitive across bands. Our XY-LENT XL variant outperforms XLM-RXXL and exhibits competitive performance with mT5 XXL while being 5x and 6x smaller respectively. We then show that our proposed method helps ameliorate the curse of multilinguality, with the XY-LENT XL achieving 99.3% GLUE performance and 98.5% SQuAD 2.0 performance compared to a SoTA English only model in the same size band. We then analyze our models performance on extremely low resource languages and posit that scaling alone may not be sufficient for improving the performance in this scenario
Foundation Transformers
Oct 19, 2022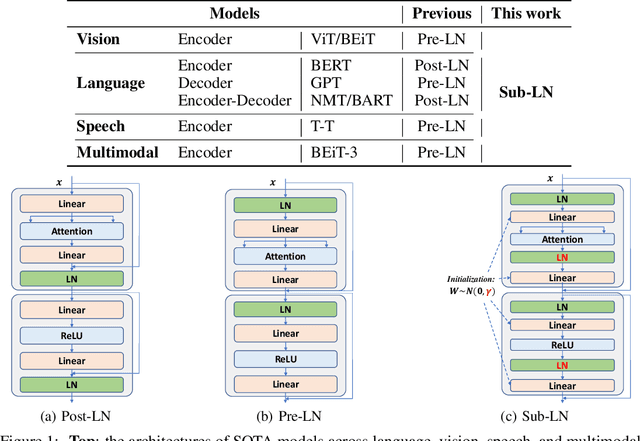
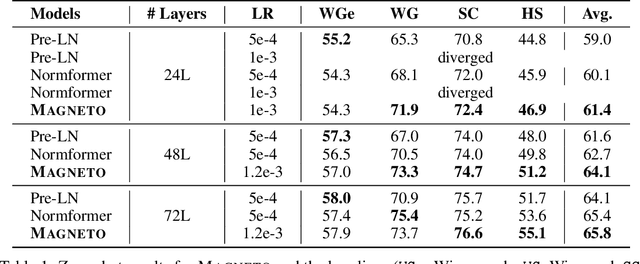
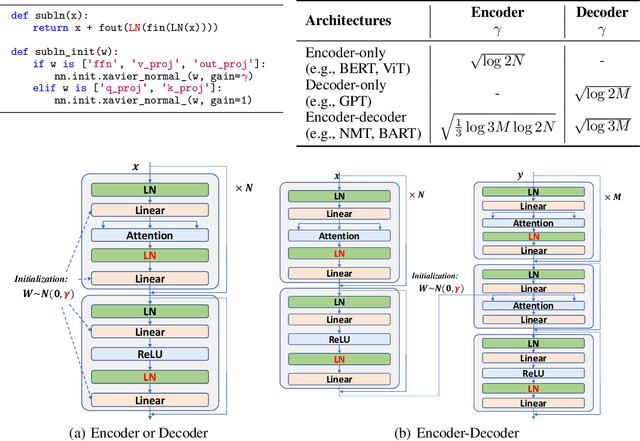
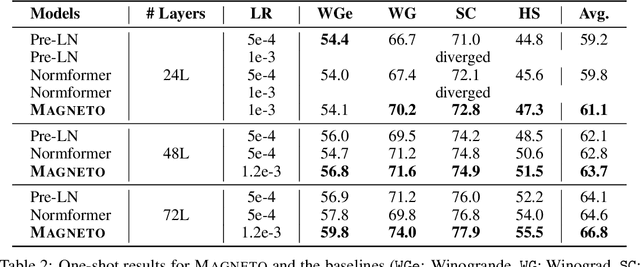
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Aug 31, 2022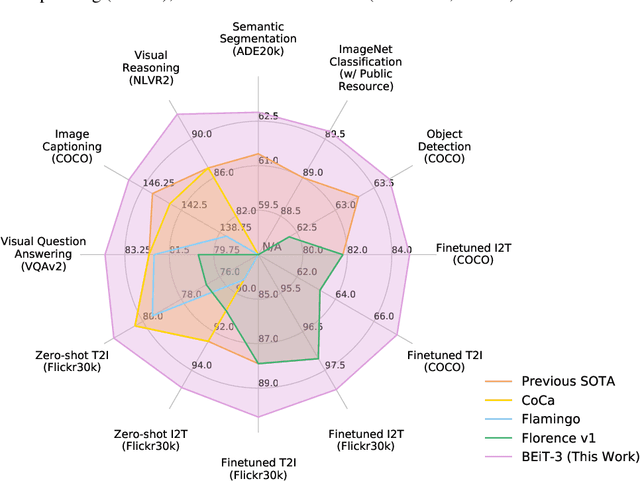
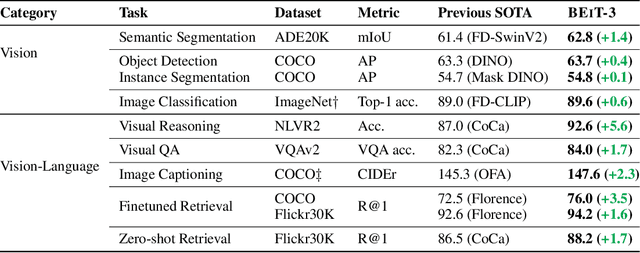
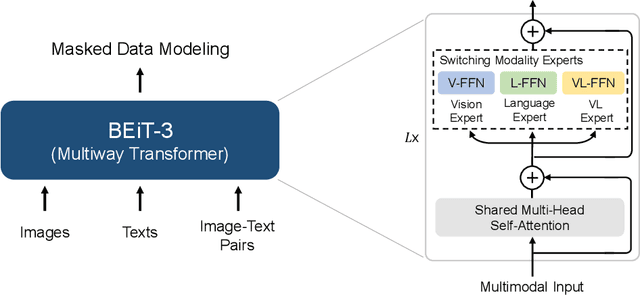

A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner. Experimental results show that BEiT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
On the Representation Collapse of Sparse Mixture of Experts
Apr 20, 2022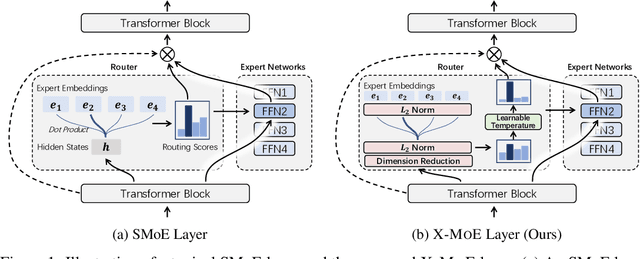
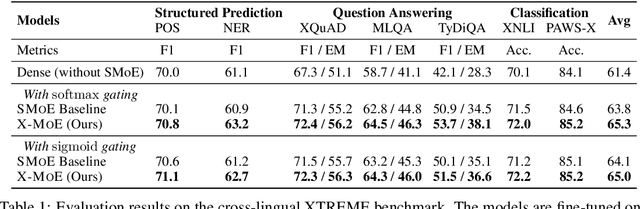
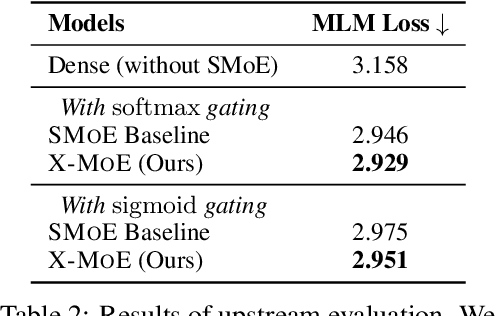
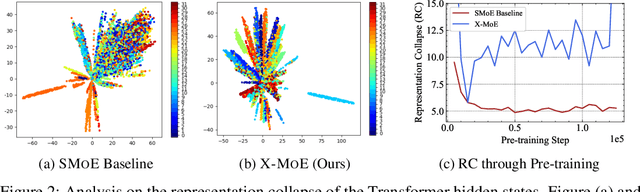
Sparse mixture of experts provides larger model capacity while requiring a constant computational overhead. It employs the routing mechanism to distribute input tokens to the best-matched experts according to their hidden representations. However, learning such a routing mechanism encourages token clustering around expert centroids, implying a trend toward representation collapse. In this work, we propose to estimate the routing scores between tokens and experts on a low-dimensional hypersphere. We conduct extensive experiments on cross-lingual language model pre-training and fine-tuning on downstream tasks. Experimental results across seven multilingual benchmarks show that our method achieves consistent gains. We also present a comprehensive analysis on the representation and routing behaviors of our models. Our method alleviates the representation collapse issue and achieves more consistent routing than the baseline mixture-of-experts methods.
Multilingual Machine Translation Systems from Microsoft for WMT21 Shared Task
Nov 03, 2021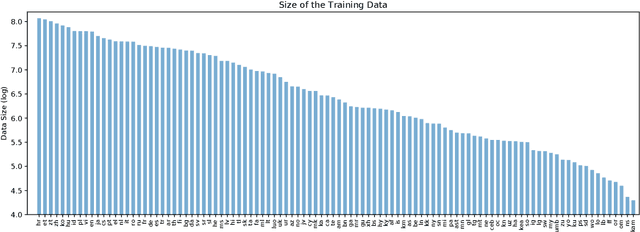
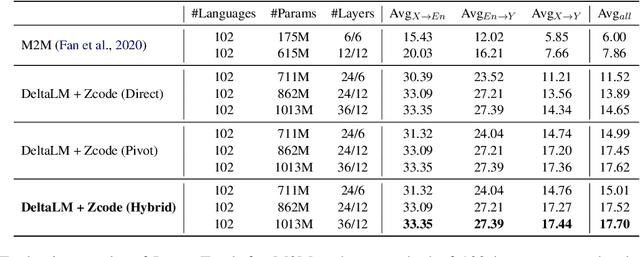

This report describes Microsoft's machine translation systems for the WMT21 shared task on large-scale multilingual machine translation. We participated in all three evaluation tracks including Large Track and two Small Tracks where the former one is unconstrained and the latter two are fully constrained. Our model submissions to the shared task were initialized with DeltaLM\footnote{\url{https://aka.ms/deltalm}}, a generic pre-trained multilingual encoder-decoder model, and fine-tuned correspondingly with the vast collected parallel data and allowed data sources according to track settings, together with applying progressive learning and iterative back-translation approaches to further improve the performance. Our final submissions ranked first on three tracks in terms of the automatic evaluation metric.
Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training
Sep 15, 2021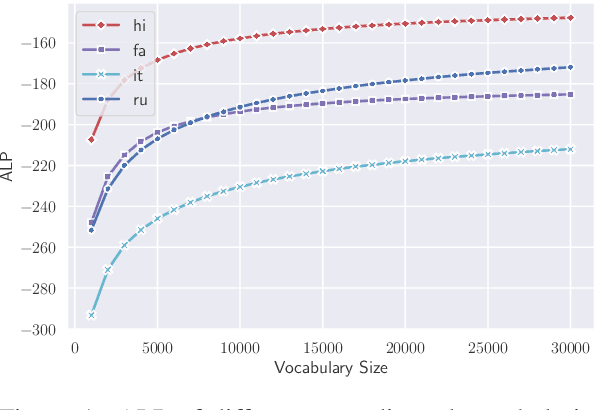
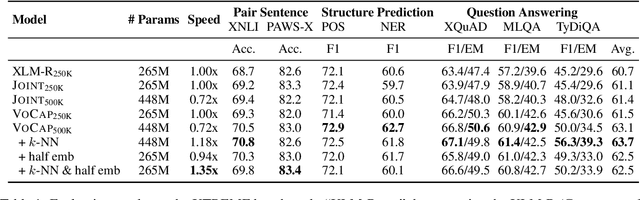
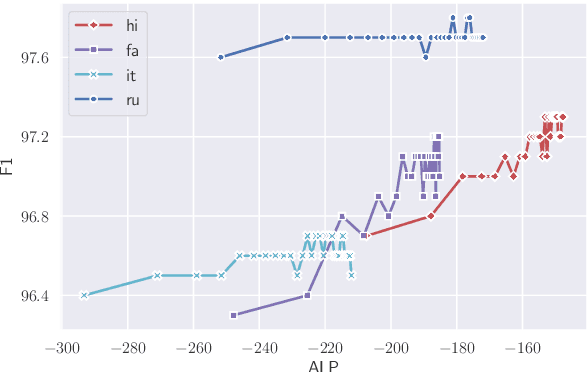
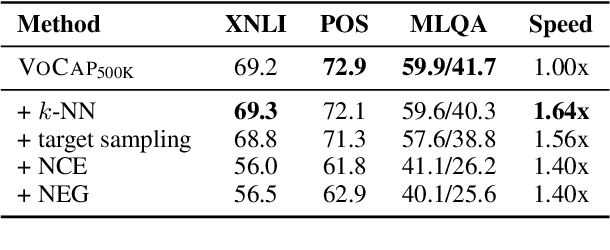
Compared to monolingual models, cross-lingual models usually require a more expressive vocabulary to represent all languages adequately. We find that many languages are under-represented in recent cross-lingual language models due to the limited vocabulary capacity. To this end, we propose an algorithm VoCap to determine the desired vocabulary capacity of each language. However, increasing the vocabulary size significantly slows down the pre-training speed. In order to address the issues, we propose k-NN-based target sampling to accelerate the expensive softmax. Our experiments show that the multilingual vocabulary learned with VoCap benefits cross-lingual language model pre-training. Moreover, k-NN-based target sampling mitigates the side-effects of increasing the vocabulary size while achieving comparable performance and faster pre-training speed. The code and the pretrained multilingual vocabularies are available at https://github.com/bozheng-hit/VoCapXLM.
XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
Jun 30, 2021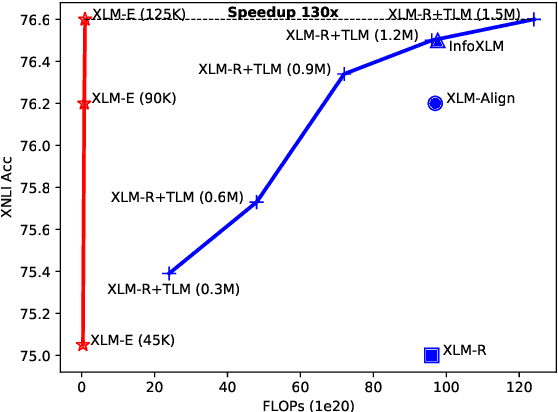
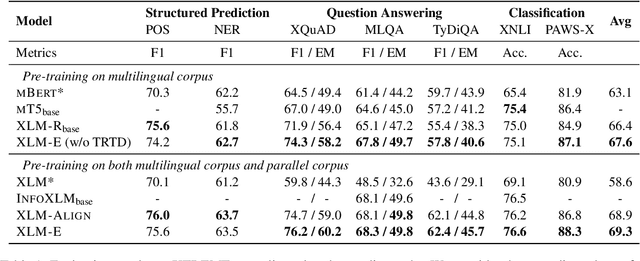
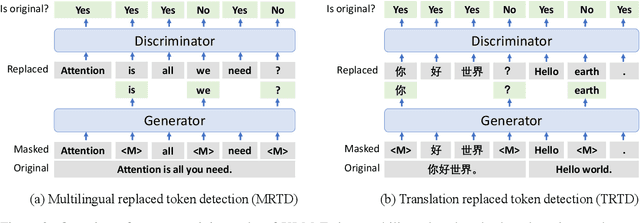
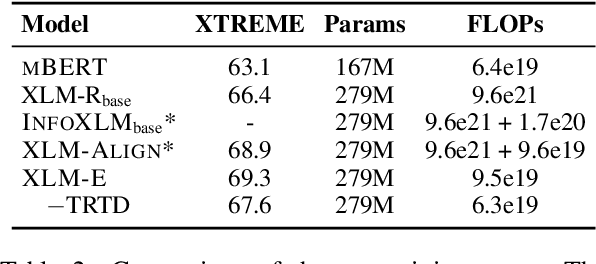
In this paper, we introduce ELECTRA-style tasks to cross-lingual language model pre-training. Specifically, we present two pre-training tasks, namely multilingual replaced token detection, and translation replaced token detection. Besides, we pretrain the model, named as XLM-E, on both multilingual and parallel corpora. Our model outperforms the baseline models on various cross-lingual understanding tasks with much less computation cost. Moreover, analysis shows that XLM-E tends to obtain better cross-lingual transferability.