 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts
Apr 07, 2024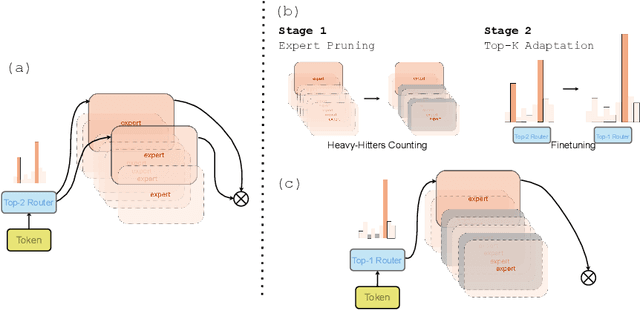
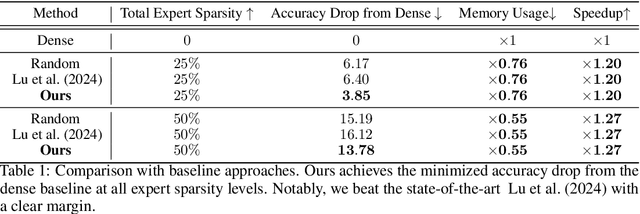
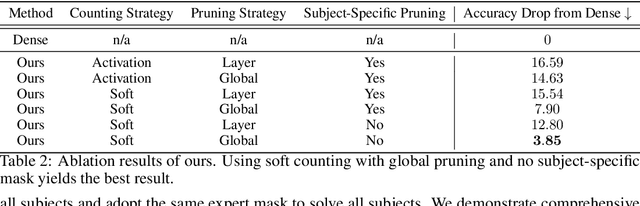
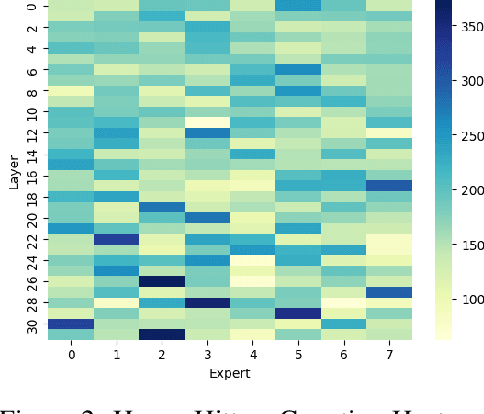
The advancement of deep learning has led to the emergence of Mixture-of-Experts (MoEs) models, known for their dynamic allocation of computational resources based on input. Despite their promise, MoEs face challenges, particularly in terms of memory requirements. To address this, our work introduces SEER-MoE, a novel two-stage framework for reducing both the memory footprint and compute requirements of pre-trained MoE models. The first stage involves pruning the total number of experts using a heavy-hitters counting guidance, while the second stage employs a regularization-based fine-tuning strategy to recover accuracy loss and reduce the number of activated experts during inference. Our empirical studies demonstrate the effectiveness of our method, resulting in a sparse MoEs model optimized for inference efficiency with minimal accuracy trade-offs.
Gating Dropout: Communication-efficient Regularization for Sparsely Activated Transformers
May 28, 2022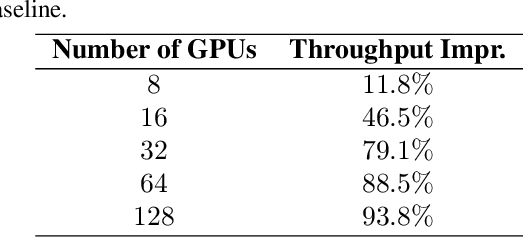
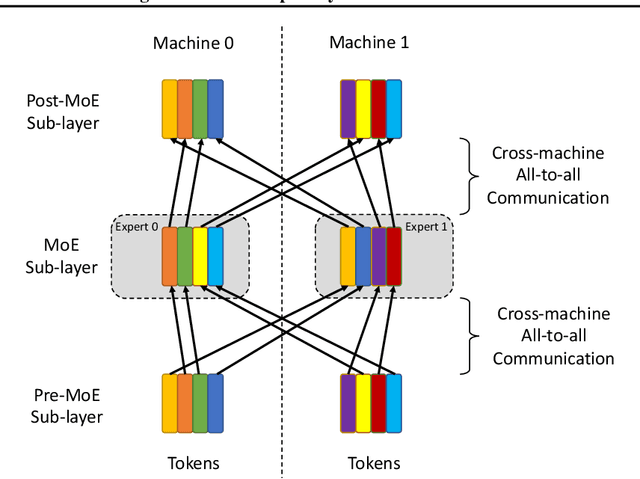

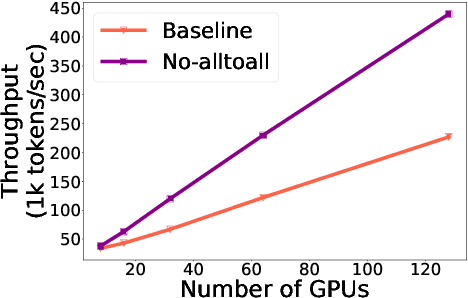
Sparsely activated transformers, such as Mixture of Experts (MoE), have received great interest due to their outrageous scaling capability which enables dramatical increases in model size without significant increases in computational cost. To achieve this, MoE models replace the feedforward sub-layer with Mixture-of-Experts sub-layer in transformers and use a gating network to route each token to its assigned experts. Since the common practice for efficient training of such models requires distributing experts and tokens across different machines, this routing strategy often incurs huge cross-machine communication cost because tokens and their assigned experts likely reside in different machines. In this paper, we propose \emph{Gating Dropout}, which allows tokens to ignore the gating network and stay at their local machines, thus reducing the cross-machine communication. Similar to traditional dropout, we also show that Gating Dropout has a regularization effect during training, resulting in improved generalization performance. We validate the effectiveness of Gating Dropout on multilingual machine translation tasks. Our results demonstrate that Gating Dropout improves a state-of-the-art MoE model with faster wall-clock time convergence rates and better BLEU scores for a variety of model sizes and datasets.
Multilingual Machine Translation Systems from Microsoft for WMT21 Shared Task
Nov 03, 2021
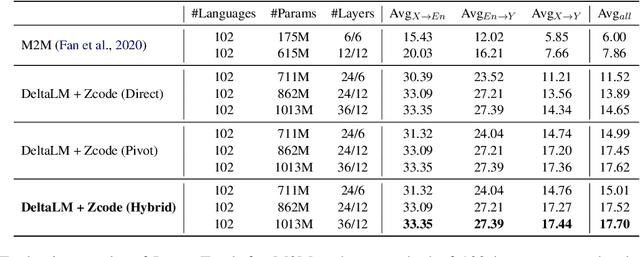

This report describes Microsoft's machine translation systems for the WMT21 shared task on large-scale multilingual machine translation. We participated in all three evaluation tracks including Large Track and two Small Tracks where the former one is unconstrained and the latter two are fully constrained. Our model submissions to the shared task were initialized with DeltaLM\footnote{\url{https://aka.ms/deltalm}}, a generic pre-trained multilingual encoder-decoder model, and fine-tuned correspondingly with the vast collected parallel data and allowed data sources according to track settings, together with applying progressive learning and iterative back-translation approaches to further improve the performance. Our final submissions ranked first on three tracks in terms of the automatic evaluation metric.
Scalable and Efficient MoE Training for Multitask Multilingual Models
Sep 22, 2021
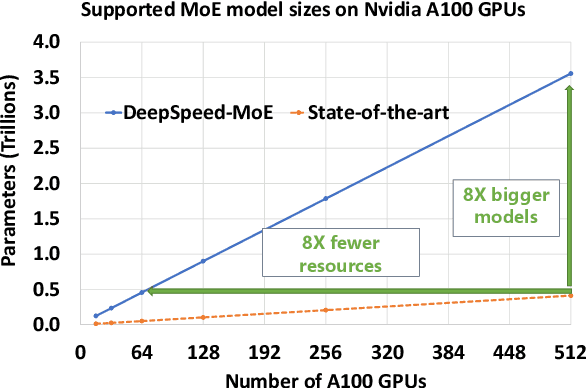
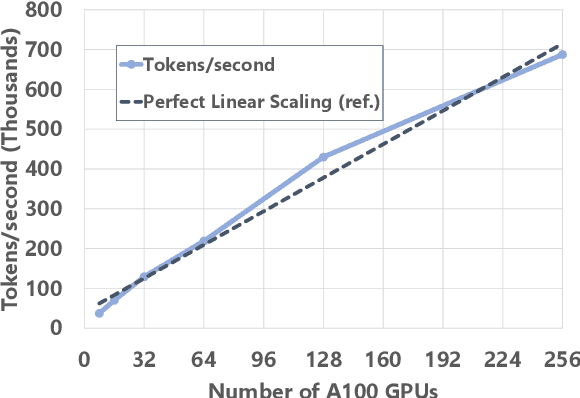
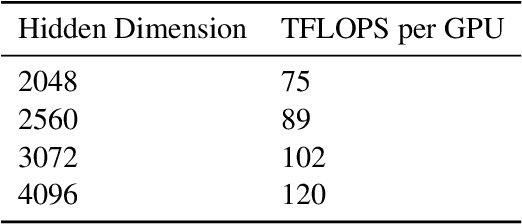
The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In contrast with dense models, the sparse architecture of MoE offers opportunities for drastically growing model size with significant accuracy gain while consuming much lower compute budget. However, supporting large scale MoE training also has its own set of system and modeling challenges. To overcome the challenges and embrace the opportunities of MoE, we first develop a system capable of scaling MoE models efficiently to trillions of parameters. It combines multi-dimensional parallelism and heterogeneous memory technologies harmoniously with MoE to empower 8x larger models on the same hardware compared with existing work. Besides boosting system efficiency, we also present new training methods to improve MoE sample efficiency and leverage expert pruning strategy to improve inference time efficiency. By combining the efficient system and training methods, we are able to significantly scale up large multitask multilingual models for language generation which results in a great improvement in model accuracy. A model trained with 10 billion parameters on 50 languages can achieve state-of-the-art performance in Machine Translation (MT) and multilingual natural language generation tasks. The system support of efficient MoE training has been implemented and open-sourced with the DeepSpeed library.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021


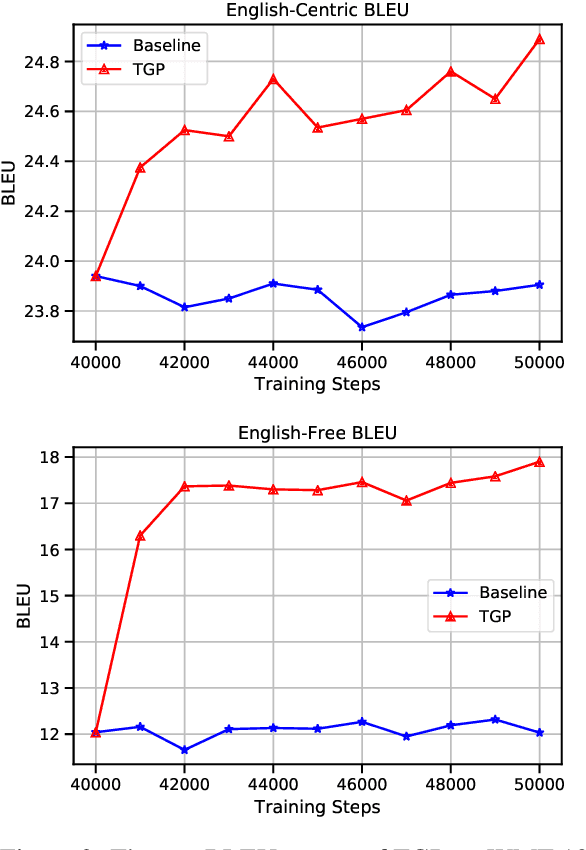
Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
Discovering Representation Sprachbund For Multilingual Pre-Training
Sep 01, 2021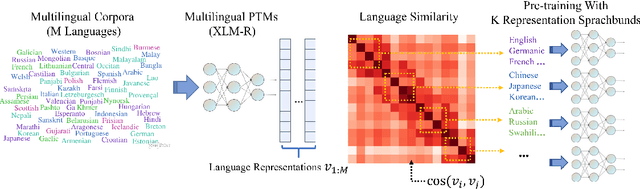

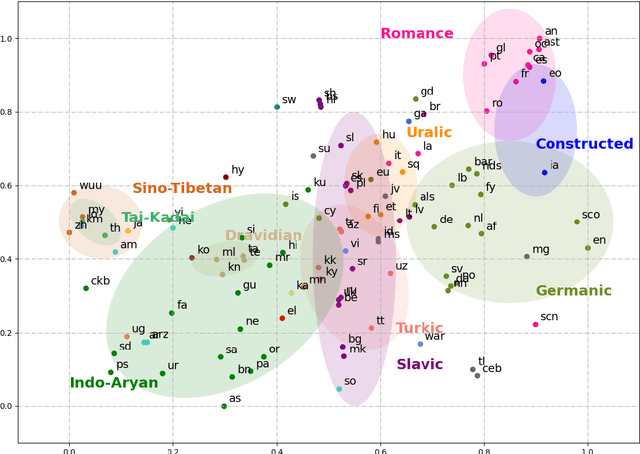

Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders
Jun 25, 2021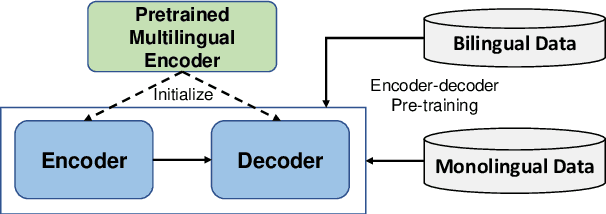

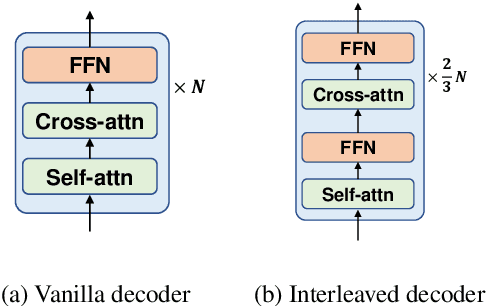
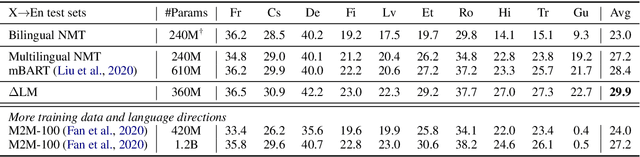
While pretrained encoders have achieved success in various natural language understanding (NLU) tasks, there is a gap between these pretrained encoders and natural language generation (NLG). NLG tasks are often based on the encoder-decoder framework, where the pretrained encoders can only benefit part of it. To reduce this gap, we introduce DeltaLM, a pretrained multilingual encoder-decoder model that regards the decoder as the task layer of off-the-shelf pretrained encoders. Specifically, we augment the pretrained multilingual encoder with a decoder and pre-train it in a self-supervised way. To take advantage of both the large-scale monolingual data and bilingual data, we adopt the span corruption and translation span corruption as the pre-training tasks. Experiments show that DeltaLM outperforms various strong baselines on both natural language generation and translation tasks, including machine translation, abstractive text summarization, data-to-text, and question generation.
XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders
Dec 31, 2020

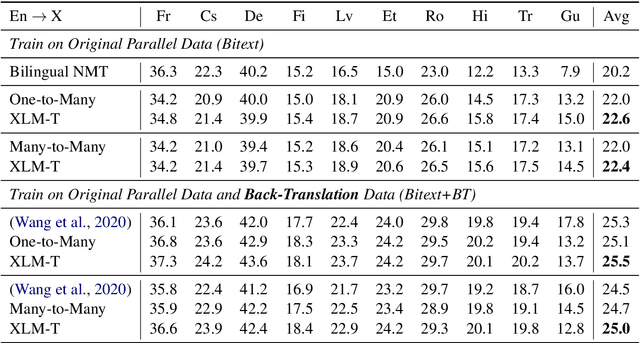

Multilingual machine translation enables a single model to translate between different languages. Most existing multilingual machine translation systems adopt a randomly initialized Transformer backbone. In this work, inspired by the recent success of language model pre-training, we present XLM-T, which initializes the model with an off-the-shelf pretrained cross-lingual Transformer encoder and fine-tunes it with multilingual parallel data. This simple method achieves significant improvements on a WMT dataset with 10 language pairs and the OPUS-100 corpus with 94 pairs. Surprisingly, the method is also effective even upon the strong baseline with back-translation. Moreover, extensive analysis of XLM-T on unsupervised syntactic parsing, word alignment, and multilingual classification explains its effectiveness for machine translation. The code will be at https://aka.ms/xlm-t.