 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
Progress and Opportunities of Foundation Models in Bioinformatics
Feb 06, 2024



Bioinformatics has witnessed a paradigm shift with the increasing integration of artificial intelligence (AI), particularly through the adoption of foundation models (FMs). These AI techniques have rapidly advanced, addressing historical challenges in bioinformatics such as the scarcity of annotated data and the presence of data noise. FMs are particularly adept at handling large-scale, unlabeled data, a common scenario in biological contexts due to the time-consuming and costly nature of experimentally determining labeled data. This characteristic has allowed FMs to excel and achieve notable results in various downstream validation tasks, demonstrating their ability to represent diverse biological entities effectively. Undoubtedly, FMs have ushered in a new era in computational biology, especially in the realm of deep learning. The primary goal of this survey is to conduct a systematic investigation and summary of FMs in bioinformatics, tracing their evolution, current research status, and the methodologies employed. Central to our focus is the application of FMs to specific biological problems, aiming to guide the research community in choosing appropriate FMs for their research needs. We delve into the specifics of the problem at hand including sequence analysis, structure prediction, function annotation, and multimodal integration, comparing the structures and advancements against traditional methods. Furthermore, the review analyses challenges and limitations faced by FMs in biology, such as data noise, model explainability, and potential biases. Finally, we outline potential development paths and strategies for FMs in future biological research, setting the stage for continued innovation and application in this rapidly evolving field. This comprehensive review serves not only as an academic resource but also as a roadmap for future explorations and applications of FMs in biology.
Evaluating Neuron Interpretation Methods of NLP Models
Jan 30, 2023Neuron Interpretation has gained traction in the field of interpretability, and have provided fine-grained insights into what a model learns and how language knowledge is distributed amongst its different components. However, the lack of evaluation benchmark and metrics have led to siloed progress within these various methods, with very little work comparing them and highlighting their strengths and weaknesses. The reason for this discrepancy is the difficulty of creating ground truth datasets, for example, many neurons within a given model may learn the same phenomena, and hence there may not be one correct answer. Moreover, a learned phenomenon may spread across several neurons that work together -- surfacing these to create a gold standard challenging. In this work, we propose an evaluation framework that measures the compatibility of a neuron analysis method with other methods. We hypothesize that the more compatible a method is with the majority of the methods, the more confident one can be about its performance. We systematically evaluate our proposed framework and present a comparative analysis of a large set of neuron interpretation methods. We make the evaluation framework available to the community. It enables the evaluation of any new method using 20 concepts and across three pre-trained models.The code is released at https://github.com/fdalvi/neuron-comparative-analysis
Discovering Representation Sprachbund For Multilingual Pre-Training
Sep 01, 2021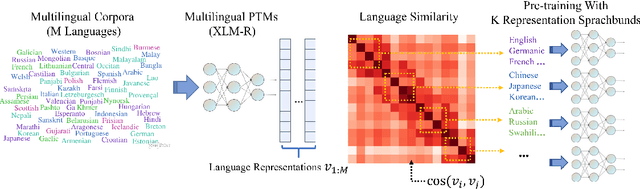

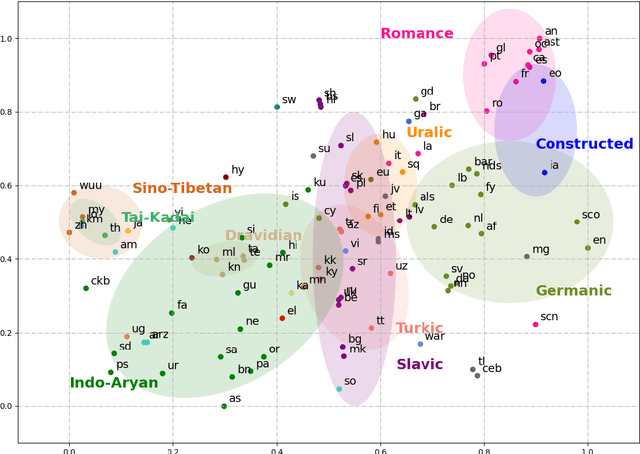

Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
Enhance the performance of navigation: A two-stage machine learning approach
Apr 02, 2020
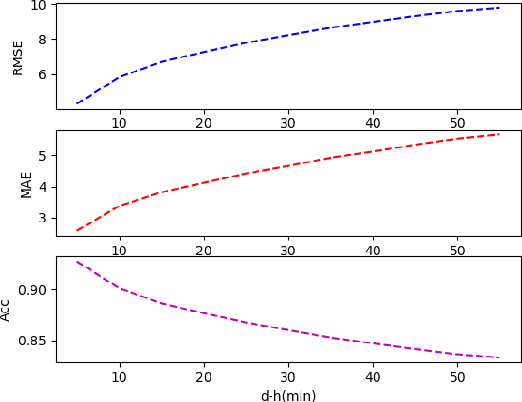
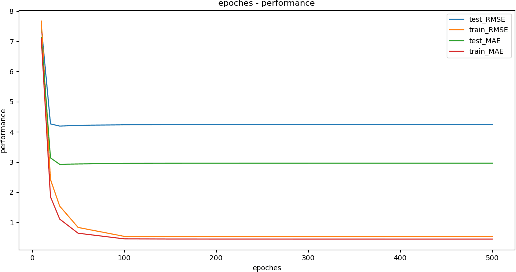
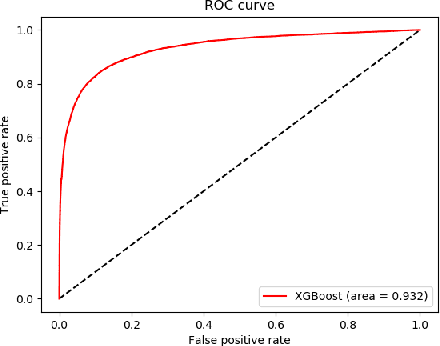
Real time traffic navigation is an important capability in smart transportation technologies, which has been extensively studied these years. Due to the vast development of edge devices, collecting real time traffic data is no longer a problem. However, real traffic navigation is still considered to be a particularly challenging problem because of the time-varying patterns of the traffic flow and unpredictable accidents/congestion. To give accurate and reliable navigation results, predicting the future traffic flow(speed,congestion,volume,etc) in a fast and accurate way is of great importance. In this paper, we adopt the ideas of ensemble learning and develop a two-stage machine learning model to give accurate navigation results. We model the traffic flow as a time series and apply XGBoost algorithm to get accurate predictions on future traffic conditions(1st stage). We then apply the Top K Dijkstra algorithm to find a set of shortest paths from the give start point to the destination as the candidates of the output optimal path. With the prediction results in the 1st stage, we find one optimal path from the candidates as the output of the navigation algorithm. We show that our navigation algorithm can be greatly improved via EOPF(Enhanced Optimal Path Finding), which is based on neural network(2nd stage). We show that our method can be over 7% better than the method without EOPF in many situations, which indicates the effectiveness of our model.