 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Exploring Language Models: Active Preference Elicitation for Online Alignment
May 29, 2024



Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023



Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
Taming Sparsely Activated Transformer with Stochastic Experts
Oct 12, 2021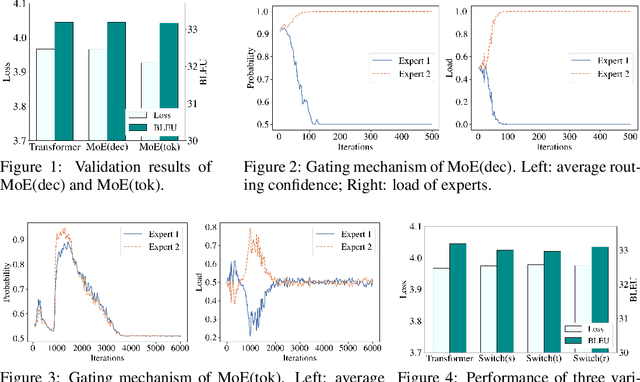
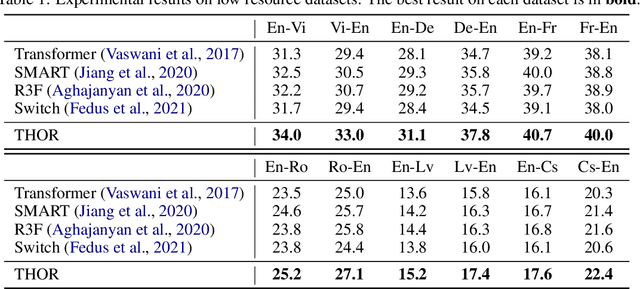
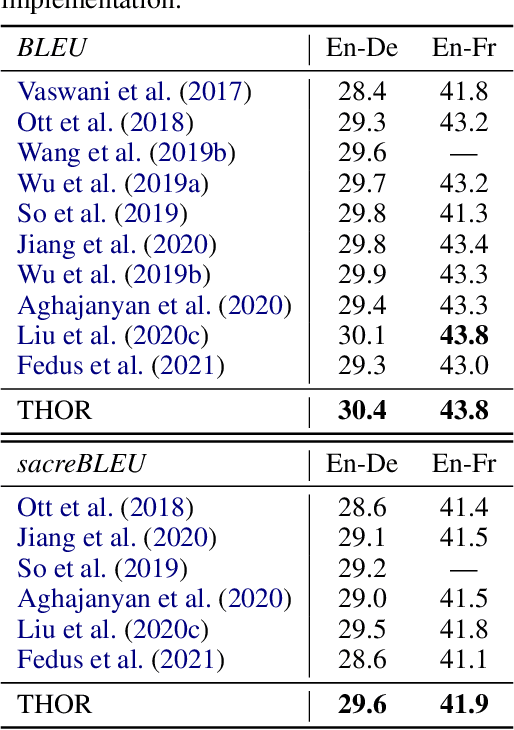

Sparsely activated models (SAMs), such as Mixture-of-Experts (MoE), can easily scale to have outrageously large amounts of parameters without significant increase in computational cost. However, SAMs are reported to be parameter inefficient such that larger models do not always lead to better performance. While most on-going research focuses on improving SAMs models by exploring methods of routing inputs to experts, our analysis reveals that such research might not lead to the solution we expect, i.e., the commonly-used routing methods based on gating mechanisms do not work better than randomly routing inputs to experts. In this paper, we propose a new expert-based model, THOR (Transformer witH StOchastic ExpeRts). Unlike classic expert-based models, such as the Switch Transformer, experts in THOR are randomly activated for each input during training and inference. THOR models are trained using a consistency regularized loss, where experts learn not only from training data but also from other experts as teachers, such that all the experts make consistent predictions. We validate the effectiveness of THOR on machine translation tasks. Results show that THOR models are more parameter efficient in that they significantly outperform the Transformer and MoE models across various settings. For example, in multilingual translation, THOR outperforms the Switch Transformer by 2 BLEU scores, and obtains the same BLEU score as that of a state-of-the-art MoE model that is 18 times larger. Our code is publicly available at: https://github.com/microsoft/Stochastic-Mixture-of-Experts.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021


Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
Discovering Representation Sprachbund For Multilingual Pre-Training
Sep 01, 2021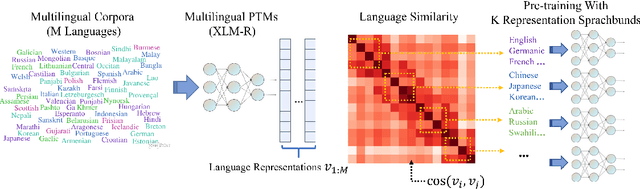

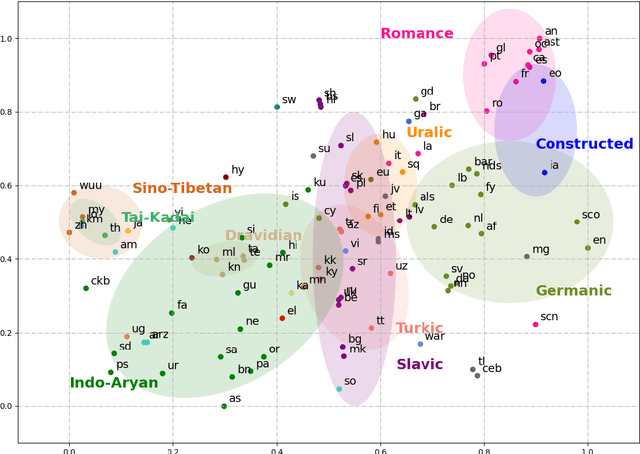

Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
Meta-Learning for Few-Shot NMT Adaptation
Apr 06, 2020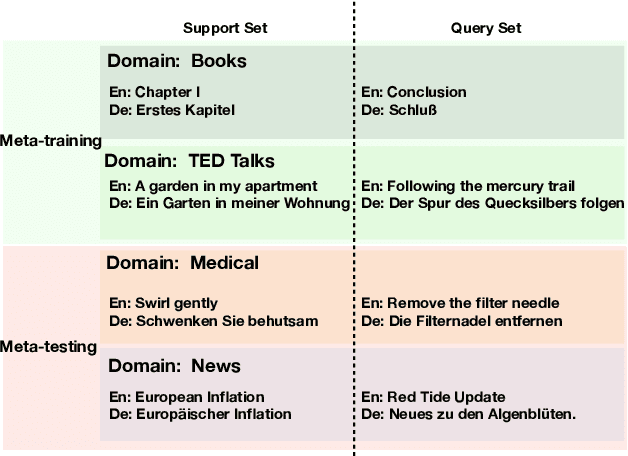
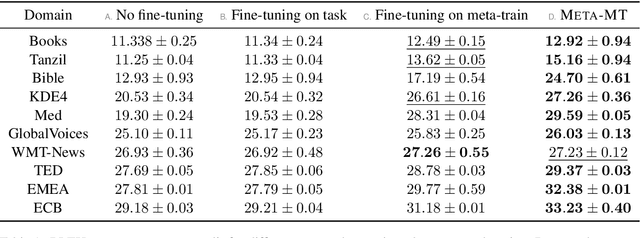

We present META-MT, a meta-learning approach to adapt Neural Machine Translation (NMT) systems in a few-shot setting. META-MT provides a new approach to make NMT models easily adaptable to many target domains with the minimal amount of in-domain data. We frame the adaptation of NMT systems as a meta-learning problem, where we learn to adapt to new unseen domains based on simulated offline meta-training domain adaptation tasks. We evaluate the proposed meta-learning strategy on ten domains with general large scale NMT systems. We show that META-MT significantly outperforms classical domain adaptation when very few in-domain examples are available. Our experiments shows that META-MT can outperform classical fine-tuning by up to 2.5 BLEU points after seeing only 4, 000 translated words (300 parallel sentences).
Zero-Resource Multilingual Model Transfer: Learning What to Share
Oct 08, 2018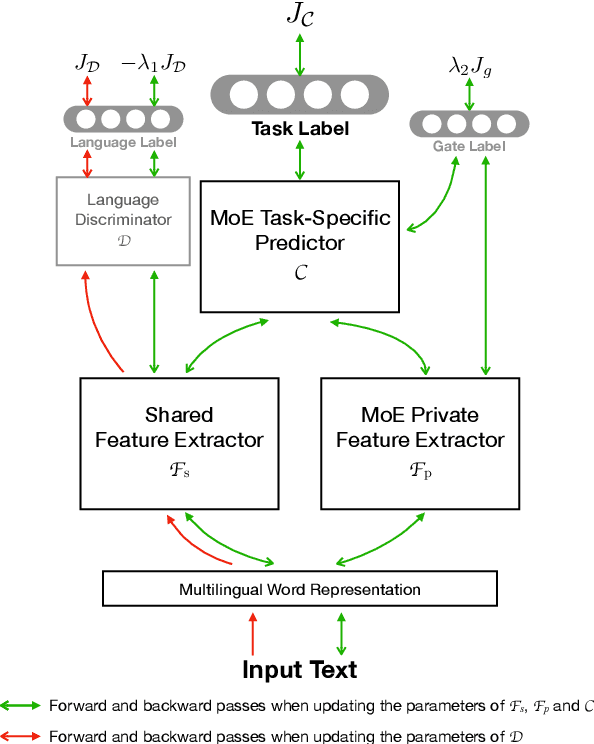

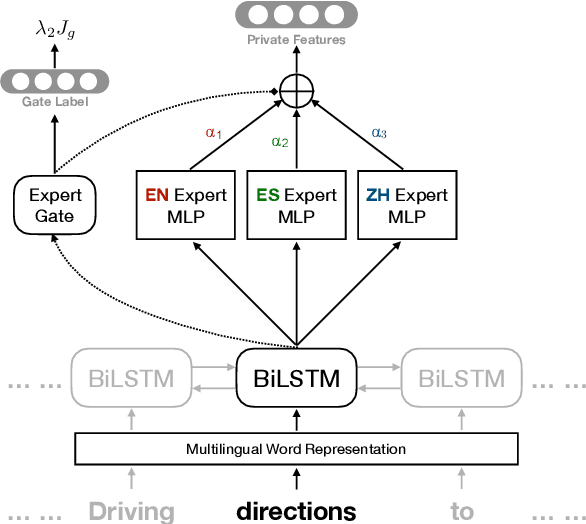

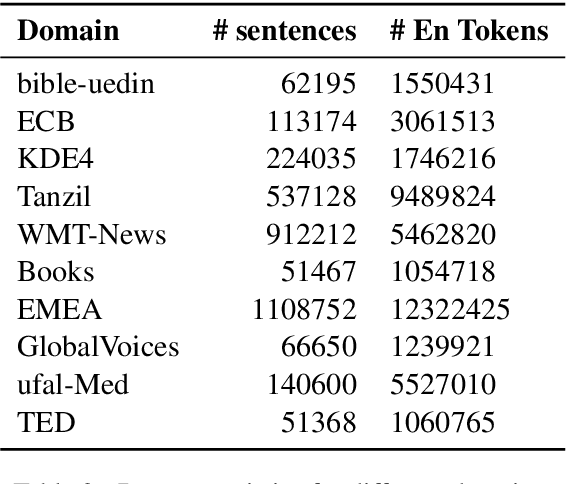
Modern natural language processing and understanding applications have enjoyed a great boost utilizing neural networks models. However, this is not the case for most languages especially low-resource ones with insufficient annotated training data. Cross-lingual transfer learning methods improve the performance on a low-resource target language by leveraging labeled data from other (source) languages, typically with the help of cross-lingual resources such as parallel corpora. In this work, we propose the first zero-resource multilingual transfer learning model that can utilize training data in multiple source languages, while not requiring target language training data nor cross-lingual supervision. Unlike existing methods that only rely on language-invariant features for cross-lingual transfer, our approach utilizes both language-invariant and language-specific features in a coherent way. Our model leverages adversarial networks to learn language-invariant features and mixture-of-experts models to dynamically exploit the relation between the target language and each individual source language. This enables our model to learn effectively what to share between various languages in the multilingual setup. It results in significant performance gains over prior art, as shown in an extensive set of experiments over multiple text classification and sequence tagging tasks including a large-scale real-world industry dataset.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018


Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
Universal Neural Machine Translation for Extremely Low Resource Languages
Apr 17, 2018


In this paper, we propose a new universal machine translation approach focusing on languages with a limited amount of parallel data. Our proposed approach utilizes a transfer-learning approach to share lexical and sentence level representations across multiple source languages into one target language. The lexical part is shared through a Universal Lexical Representation to support multilingual word-level sharing. The sentence-level sharing is represented by a model of experts from all source languages that share the source encoders with all other languages. This enables the low-resource language to utilize the lexical and sentence representations of the higher resource languages. Our approach is able to achieve 23 BLEU on Romanian-English WMT2016 using a tiny parallel corpus of 6k sentences, compared to the 18 BLEU of strong baseline system which uses multilingual training and back-translation. Furthermore, we show that the proposed approach can achieve almost 20 BLEU on the same dataset through fine-tuning a pre-trained multi-lingual system in a zero-shot setting.
Gender Aware Spoken Language Translation Applied to English-Arabic
Feb 26, 2018
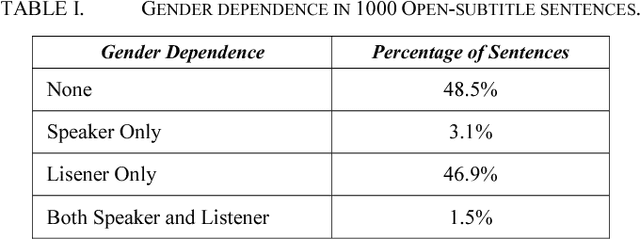
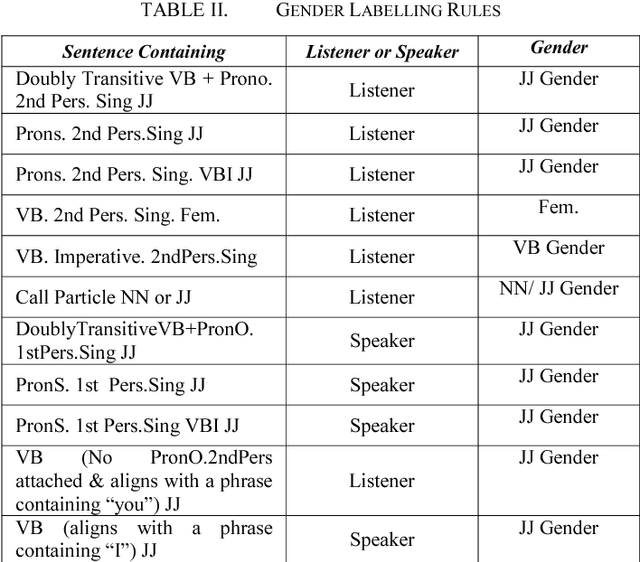
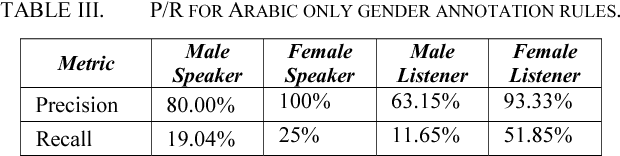
Spoken Language Translation (SLT) is becoming more widely used and becoming a communication tool that helps in crossing language barriers. One of the challenges of SLT is the translation from a language without gender agreement to a language with gender agreement such as English to Arabic. In this paper, we introduce an approach to tackle such limitation by enabling a Neural Machine Translation system to produce gender-aware translation. We show that NMT system can model the speaker/listener gender information to produce gender-aware translation. We propose a method to generate data used in adapting a NMT system to produce gender-aware. The proposed approach can achieve significant improvement of the translation quality by 2 BLEU points.