 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaKritika: Building Synthetic Pretraining Data at Scale for Indic Languages
Nov 16, 2025In the context of pretraining of Large Language Models (LLMs), synthetic data has emerged as an alternative for generating high-quality pretraining data at scale. This is particularly beneficial in low-resource language settings where the benefits of recent LLMs have been unevenly distributed across languages. In this work, we present a systematic study on the generation and evaluation of synthetic multilingual pretraining data for Indic languages, where we construct a large-scale synthetic dataset BhashaKritika, comprising 540B tokens using 5 different techniques for 10 languages. We explore the impact of grounding generation in documents, personas, and topics. We analyze how language choice, both in the prompt instructions and document grounding, affects data quality, and we compare translations of English content with native generation in Indic languages. To support scalable and language-sensitive evaluation, we introduce a modular quality evaluation pipeline that integrates script and language detection, metadata consistency checks, n-gram repetition analysis, and perplexity-based filtering using KenLM models. Our framework enables robust quality control across diverse scripts and linguistic contexts. Empirical results through model runs reveal key trade-offs in generation strategies and highlight best practices for constructing effective multilingual corpora.
Dissecting In-Context Learning of Translations in GPTs
Oct 24, 2023



Most of the recent work in leveraging Large Language Models (LLMs) such as GPT-3 for Machine Translation (MT) has focused on selecting the few-shot samples for prompting. In this work, we try to better understand the role of demonstration attributes for the in-context learning of translations through perturbations of high-quality, in-domain demonstrations. We find that asymmetric perturbation of the source-target mappings yield vastly different results. We show that the perturbation of the source side has surprisingly little impact, while target perturbation can drastically reduce translation quality, suggesting that it is the output text distribution that provides the most important learning signal during in-context learning of translations. We propose a method named Zero-Shot-Context to add this signal automatically in Zero-Shot prompting. We demonstrate that it improves upon the zero-shot translation performance of GPT-3, even making it competitive with few-shot prompted translations.
Do GPTs Produce Less Literal Translations?
Jun 06, 2023



Large Language Models (LLMs) such as GPT-3 have emerged as general-purpose language models capable of addressing many natural language generation or understanding tasks. On the task of Machine Translation (MT), multiple works have investigated few-shot prompting mechanisms to elicit better translations from LLMs. However, there has been relatively little investigation on how such translations differ qualitatively from the translations generated by standard Neural Machine Translation (NMT) models. In this work, we investigate these differences in terms of the literalness of translations produced by the two systems. Using literalness measures involving word alignment and monotonicity, we find that translations out of English (E-X) from GPTs tend to be less literal, while exhibiting similar or better scores on MT quality metrics. We demonstrate that this finding is borne out in human evaluations as well. We then show that these differences are especially pronounced when translating sentences that contain idiomatic expressions.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023



Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
Leveraging GPT-4 for Automatic Translation Post-Editing
May 24, 2023
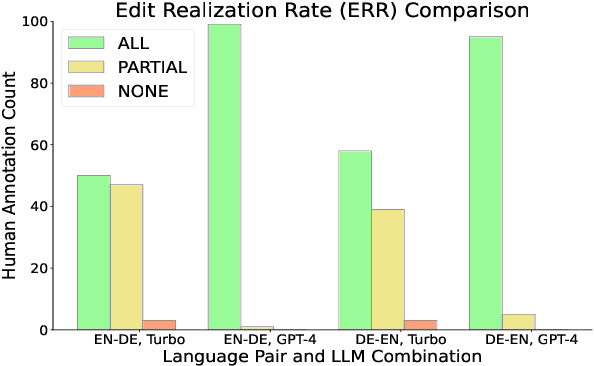

While Neural Machine Translation (NMT) represents the leading approach to Machine Translation (MT), the outputs of NMT models still require translation post-editing to rectify errors and enhance quality, particularly under critical settings. In this work, we formalize the task of translation post-editing with Large Language Models (LLMs) and explore the use of GPT-4 to automatically post-edit NMT outputs across several language pairs. Our results demonstrate that GPT-4 is adept at translation post-editing and produces meaningful edits even when the target language is not English. Notably, we achieve state-of-the-art performance on WMT-22 English-Chinese, English-German, Chinese-English and German-English language pairs using GPT-4 based post-editing, as evaluated by state-of-the-art MT quality metrics.
ResiDual: Transformer with Dual Residual Connections
Apr 28, 2023



Transformer networks have become the preferred architecture for many tasks due to their state-of-the-art performance. However, the optimal way to implement residual connections in Transformer, which are essential for effective training, is still debated. Two widely used variants are the Post-Layer-Normalization (Post-LN) and Pre-Layer-Normalization (Pre-LN) Transformers, which apply layer normalization after each residual block's output or before each residual block's input, respectively. While both variants enjoy their advantages, they also suffer from severe limitations: Post-LN causes gradient vanishing issue that hinders training deep Transformers, and Pre-LN causes representation collapse issue that limits model capacity. In this paper, we propose ResiDual, a novel Transformer architecture with Pre-Post-LN (PPLN), which fuses the connections in Post-LN and Pre-LN together and inherits their advantages while avoids their limitations. We conduct both theoretical analyses and empirical experiments to verify the effectiveness of ResiDual. Theoretically, we prove that ResiDual has a lower bound on the gradient to avoid the vanishing issue due to the residual connection from Pre-LN. Moreover, ResiDual also has diverse model representations to avoid the collapse issue due to the residual connection from Post-LN. Empirically, ResiDual outperforms both Post-LN and Pre-LN on several machine translation benchmarks across different network depths and data sizes. Thanks to the good theoretical and empirical performance, ResiDual Transformer can serve as a foundation architecture for different AI models (e.g., large language models). Our code is available at https://github.com/microsoft/ResiDual.
VideoDubber: Machine Translation with Speech-Aware Length Control for Video Dubbing
Nov 30, 2022



Video dubbing aims to translate the original speech in a film or television program into the speech in a target language, which can be achieved with a cascaded system consisting of speech recognition, machine translation and speech synthesis. To ensure the translated speech to be well aligned with the corresponding video, the length/duration of the translated speech should be as close as possible to that of the original speech, which requires strict length control. Previous works usually control the number of words or characters generated by the machine translation model to be similar to the source sentence, without considering the isochronicity of speech as the speech duration of words/characters in different languages varies. In this paper, we propose a machine translation system tailored for the task of video dubbing, which directly considers the speech duration of each token in translation, to match the length of source and target speech. Specifically, we control the speech length of generated sentence by guiding the prediction of each word with the duration information, including the speech duration of itself as well as how much duration is left for the remaining words. We design experiments on four language directions (German -> English, Spanish -> English, Chinese <-> English), and the results show that the proposed method achieves better length control ability on the generated speech than baseline methods. To make up the lack of real-world datasets, we also construct a real-world test set collected from films to provide comprehensive evaluations on the video dubbing task.
Rank-One Editing of Encoder-Decoder Models
Nov 23, 2022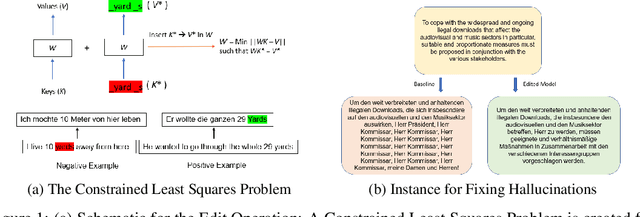

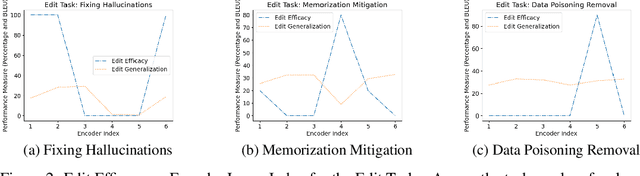

Large sequence to sequence models for tasks such as Neural Machine Translation (NMT) are usually trained over hundreds of millions of samples. However, training is just the origin of a model's life-cycle. Real-world deployments of models require further behavioral adaptations as new requirements emerge or shortcomings become known. Typically, in the space of model behaviors, behavior deletion requests are addressed through model retrainings whereas model finetuning is done to address behavior addition requests, both procedures being instances of data-based model intervention. In this work, we present a preliminary study investigating rank-one editing as a direct intervention method for behavior deletion requests in encoder-decoder transformer models. We propose four editing tasks for NMT and show that the proposed editing algorithm achieves high efficacy, while requiring only a single instance of positive example to fix an erroneous (negative) model behavior.
Operationalizing Specifications, In Addition to Test Sets for Evaluating Constrained Generative Models
Nov 19, 2022

In this work, we present some recommendations on the evaluation of state-of-the-art generative models for constrained generation tasks. The progress on generative models has been rapid in recent years. These large-scale models have had three impacts: firstly, the fluency of generation in both language and vision modalities has rendered common average-case evaluation metrics much less useful in diagnosing system errors. Secondly, the same substrate models now form the basis of a number of applications, driven both by the utility of their representations as well as phenomena such as in-context learning, which raise the abstraction level of interacting with such models. Thirdly, the user expectations around these models and their feted public releases have made the technical challenge of out of domain generalization much less excusable in practice. Subsequently, our evaluation methodologies haven't adapted to these changes. More concretely, while the associated utility and methods of interacting with generative models have expanded, a similar expansion has not been observed in their evaluation practices. In this paper, we argue that the scale of generative models could be exploited to raise the abstraction level at which evaluation itself is conducted and provide recommendations for the same. Our recommendations are based on leveraging specifications as a powerful instrument to evaluate generation quality and are readily applicable to a variety of tasks.
Finding Memo: Extractive Memorization in Constrained Sequence Generation Tasks
Oct 24, 2022



Memorization presents a challenge for several constrained Natural Language Generation (NLG) tasks such as Neural Machine Translation (NMT), wherein the proclivity of neural models to memorize noisy and atypical samples reacts adversely with the noisy (web crawled) datasets. However, previous studies of memorization in constrained NLG tasks have only focused on counterfactual memorization, linking it to the problem of hallucinations. In this work, we propose a new, inexpensive algorithm for extractive memorization (exact training data generation under insufficient context) in constrained sequence generation tasks and use it to study extractive memorization and its effects in NMT. We demonstrate that extractive memorization poses a serious threat to NMT reliability by qualitatively and quantitatively characterizing the memorized samples as well as the model behavior in their vicinity. Based on empirical observations, we develop a simple algorithm which elicits non-memorized translations of memorized samples from the same model, for a large fraction of such samples. Finally, we show that the proposed algorithm could also be leveraged to mitigate memorization in the model through finetuning. We have released the code to reproduce our results at https://github.com/vyraun/Finding-Memo.