 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Neural Codec Language Model for Selective Editable Text to Speech Generation
Jan 18, 2026Neural codec language models achieve impressive zero-shot Text-to-Speech (TTS) by fully imitating the acoustic characteristics of a short speech prompt, including timbre, prosody, and paralinguistic information. However, such holistic imitation limits their ability to isolate and control individual attributes. In this paper, we present a unified codec language model SpeechEdit that extends zero-shot TTS with a selective control mechanism. By default, SpeechEdit reproduces the complete acoustic profile inferred from the speech prompt, but it selectively overrides only the attributes specified by explicit control instructions. To enable controllable modeling, SpeechEdit is trained on our newly constructed LibriEdit dataset, which provides delta (difference-aware) training pairs derived from LibriHeavy. Experimental results show that our approach maintains naturalness and robustness while offering flexible and localized control over desired attributes. Audio samples are available at https://speech-editing.github.io/speech-editing/.
Fine-Tuning Large Multimodal Models for Automatic Pronunciation Assessment
Sep 19, 2025Automatic Pronunciation Assessment (APA) is critical for Computer-Assisted Language Learning (CALL), requiring evaluation across multiple granularities and aspects. Large Multimodal Models (LMMs) present new opportunities for APA, but their effectiveness in fine-grained assessment remains uncertain. This work investigates fine-tuning LMMs for APA using the Speechocean762 dataset and a private corpus. Fine-tuning significantly outperforms zero-shot settings and achieves competitive results on single-granularity tasks compared to public and commercial systems. The model performs well at word and sentence levels, while phoneme-level assessment remains challenging. We also observe that the Pearson Correlation Coefficient (PCC) reaches 0.9, whereas Spearman's rank Correlation Coefficient (SCC) remains around 0.6, suggesting that SCC better reflects ordinal consistency. These findings highlight both the promise and limitations of LMMs for APA and point to future work on fine-grained modeling and rank-aware evaluation.
Next Tokens Denoising for Speech Synthesis
Jul 30, 2025While diffusion and autoregressive (AR) models have significantly advanced generative modeling, they each present distinct limitations. AR models, which rely on causal attention, cannot exploit future context and suffer from slow generation speeds. Conversely, diffusion models struggle with key-value (KV) caching. To overcome these challenges, we introduce Dragon-FM, a novel text-to-speech (TTS) design that unifies AR and flow-matching. This model processes 48 kHz audio codec tokens in chunks at a compact 12.5 tokens per second rate. This design enables AR modeling across chunks, ensuring global coherence, while parallel flow-matching within chunks facilitates fast iterative denoising. Consequently, the proposed model can utilize KV-cache across chunks and incorporate future context within each chunk. Furthermore, it bridges continuous and discrete feature modeling, demonstrating that continuous AR flow-matching can predict discrete tokens with finite scalar quantizers. This efficient codec and fast chunk-autoregressive architecture also makes the proposed model particularly effective for generating extended content. Experiment for demos of our work} on podcast datasets demonstrate its capability to efficiently generate high-quality zero-shot podcasts.
Medical-Knowledge Driven Multiple Instance Learning for Classifying Severe Abdominal Anomalies on Prenatal Ultrasound
Jul 02, 2025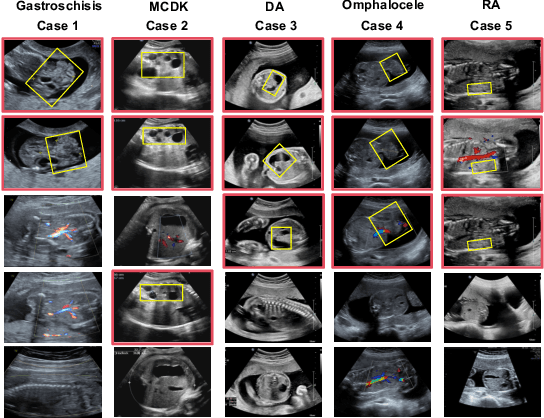
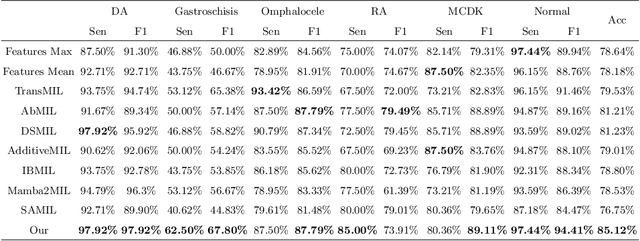
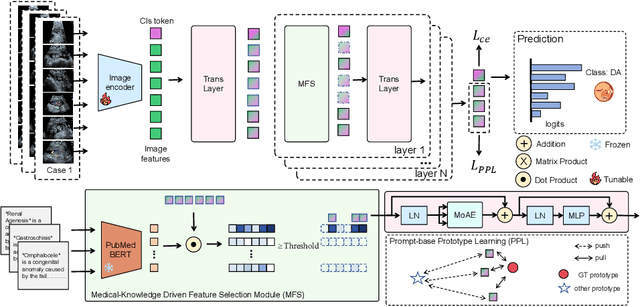

Fetal abdominal malformations are serious congenital anomalies that require accurate diagnosis to guide pregnancy management and reduce mortality. Although AI has demonstrated significant potential in medical diagnosis, its application to prenatal abdominal anomalies remains limited. Most existing studies focus on image-level classification and rely on standard plane localization, placing less emphasis on case-level diagnosis. In this paper, we develop a case-level multiple instance learning (MIL)-based method, free of standard plane localization, for classifying fetal abdominal anomalies in prenatal ultrasound. Our contribution is three-fold. First, we adopt a mixture-of-attention-experts module (MoAE) to weight different attention heads for various planes. Secondly, we propose a medical-knowledge-driven feature selection module (MFS) to align image features with medical knowledge, performing self-supervised image token selection at the case-level. Finally, we propose a prompt-based prototype learning (PPL) to enhance the MFS. Extensively validated on a large prenatal abdominal ultrasound dataset containing 2,419 cases, with a total of 24,748 images and 6 categories, our proposed method outperforms the state-of-the-art competitors. Codes are available at:https://github.com/LL-AC/AAcls.
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
May 26, 2025Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on https://anonymous.4open.science/w/demo_page-48B7/.
Exploring Collaborative GenAI Agents in Synchronous Group Settings: Eliciting Team Perceptions and Design Considerations for the Future of Work
Apr 21, 2025



While generative artificial intelligence (GenAI) is finding increased adoption in workplaces, current tools are primarily designed for individual use. Prior work established the potential for these tools to enhance personal creativity and productivity towards shared goals; however, we don't know yet how to best take into account the nuances of group work and team dynamics when deploying GenAI in work settings. In this paper, we investigate the potential of collaborative GenAI agents to augment teamwork in synchronous group settings through an exploratory study that engaged 25 professionals across 6 teams in speculative design workshops and individual follow-up interviews. Our workshops included a mixed reality provotype to simulate embodied collaborative GenAI agents capable of actively participating in group discussions. Our findings suggest that, if designed well, collaborative GenAI agents offer valuable opportunities to enhance team problem-solving by challenging groupthink, bridging communication gaps, and reducing social friction. However, teams' willingness to integrate GenAI agents depended on its perceived fit across a number of individual, team, and organizational factors. We outline the key design tensions around agent representation, social prominence, and engagement and highlight the opportunities spatial and immersive technologies could offer to modulate GenAI influence on team outcomes and strike a balance between augmentation and agency.
Exploring the Potential of Large Multimodal Models as Effective Alternatives for Pronunciation Assessment
Mar 14, 2025Large Multimodal Models (LMMs) have demonstrated exceptional performance across a wide range of domains. This paper explores their potential in pronunciation assessment tasks, with a particular focus on evaluating the capabilities of the Generative Pre-trained Transformer (GPT) model, specifically GPT-4o. Our study investigates its ability to process speech and audio for pronunciation assessment across multiple levels of granularity and dimensions, with an emphasis on feedback generation and scoring. For our experiments, we use the publicly available Speechocean762 dataset. The evaluation focuses on two key aspects: multi-level scoring and the practicality of the generated feedback. Scoring results are compared against the manual scores provided in the Speechocean762 dataset, while feedback quality is assessed using Large Language Models (LLMs). The findings highlight the effectiveness of integrating LMMs with traditional methods for pronunciation assessment, offering insights into the model's strengths and identifying areas for further improvement.
CosyAudio: Improving Audio Generation with Confidence Scores and Synthetic Captions
Jan 28, 2025Text-to-Audio (TTA) generation is an emerging area within AI-generated content (AIGC), where audio is created from natural language descriptions. Despite growing interest, developing robust TTA models remains challenging due to the scarcity of well-labeled datasets and the prevalence of noisy or inaccurate captions in large-scale, weakly labeled corpora. To address these challenges, we propose CosyAudio, a novel framework that utilizes confidence scores and synthetic captions to enhance the quality of audio generation. CosyAudio consists of two core components: AudioCapTeller and an audio generator. AudioCapTeller generates synthetic captions for audio and provides confidence scores to evaluate their accuracy. The audio generator uses these synthetic captions and confidence scores to enable quality-aware audio generation. Additionally, we introduce a self-evolving training strategy that iteratively optimizes CosyAudio across both well-labeled and weakly-labeled datasets. Initially trained with well-labeled data, AudioCapTeller leverages its assessment capabilities on weakly-labeled datasets for high-quality filtering and reinforcement learning, which further improves its performance. The well-trained AudioCapTeller refines corpora by generating new captions and confidence scores, serving for the audio generator training. Extensive experiments on open-source datasets demonstrate that CosyAudio outperforms existing models in automated audio captioning, generates more faithful audio, and exhibits strong generalization across diverse scenarios.
ZSVC: Zero-shot Style Voice Conversion with Disentangled Latent Diffusion Models and Adversarial Training
Jan 08, 2025



Style voice conversion aims to transform the speaking style of source speech into a desired style while keeping the original speaker's identity. However, previous style voice conversion approaches primarily focus on well-defined domains such as emotional aspects, limiting their practical applications. In this study, we present ZSVC, a novel Zero-shot Style Voice Conversion approach that utilizes a speech codec and a latent diffusion model with speech prompting mechanism to facilitate in-context learning for speaking style conversion. To disentangle speaking style and speaker timbre, we introduce information bottleneck to filter speaking style in the source speech and employ Uncertainty Modeling Adaptive Instance Normalization (UMAdaIN) to perturb the speaker timbre in the style prompt. Moreover, we propose a novel adversarial training strategy to enhance in-context learning and improve style similarity. Experiments conducted on 44,000 hours of speech data demonstrate the superior performance of ZSVC in generating speech with diverse speaking styles in zero-shot scenarios.
Continuous Speech Tokens Makes LLMs Robust Multi-Modality Learners
Dec 06, 2024



Recent advances in GPT-4o like multi-modality models have demonstrated remarkable progress for direct speech-to-speech conversation, with real-time speech interaction experience and strong speech understanding ability. However, current research focuses on discrete speech tokens to align with discrete text tokens for language modelling, which depends on an audio codec with residual connections or independent group tokens, such a codec usually leverages large scale and diverse datasets training to ensure that the discrete speech codes have good representation for varied domain, noise, style data reconstruction as well as a well-designed codec quantizer and encoder-decoder architecture for discrete token language modelling. This paper introduces Flow-Omni, a continuous speech token based GPT-4o like model, capable of real-time speech interaction and low streaming latency. Specifically, first, instead of cross-entropy loss only, we combine flow matching loss with a pretrained autoregressive LLM and a small MLP network to predict the probability distribution of the continuous-valued speech tokens from speech prompt. second, we incorporated the continuous speech tokens to Flow-Omni multi-modality training, thereby achieving robust speech-to-speech performance with discrete text tokens and continuous speech tokens together. Experiments demonstrate that, compared to discrete text and speech multi-modality training and its variants, the continuous speech tokens mitigate robustness issues by avoiding the inherent flaws of discrete speech code's representation loss for LLM.