 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgGoal: Rethinking Surgical Planning Evaluation via Goal-Satisfiability
Jan 15, 2026Surgical planning integrates visual perception, long-horizon reasoning, and procedural knowledge, yet it remains unclear whether current evaluation protocols reliably assess vision-language models (VLMs) in safety-critical settings. Motivated by a goal-oriented view of surgical planning, we define planning correctness via phase-goal satisfiability, where plan validity is determined by expert-defined surgical rules. Based on this definition, we introduce a multicentric meta-evaluation benchmark with valid procedural variations and invalid plans containing order and content errors. Using this benchmark, we show that sequence similarity metrics systematically misjudge planning quality, penalizing valid plans while failing to identify invalid ones. We therefore adopt a rule-based goal-satisfiability metric as a high-precision meta-evaluation reference to assess Video-LLMs under progressively constrained settings, revealing failures due to perception errors and under-constrained reasoning. Structural knowledge consistently improves performance, whereas semantic guidance alone is unreliable and benefits larger models only when combined with structural constraints.
Byzantine-Resilient Federated Learning via Distributed Optimization
Mar 13, 2025Byzantine attacks present a critical challenge to Federated Learning (FL), where malicious participants can disrupt the training process, degrade model accuracy, and compromise system reliability. Traditional FL frameworks typically rely on aggregation-based protocols for model updates, leaving them vulnerable to sophisticated adversarial strategies. In this paper, we demonstrate that distributed optimization offers a principled and robust alternative to aggregation-centric methods. Specifically, we show that the Primal-Dual Method of Multipliers (PDMM) inherently mitigates Byzantine impacts by leveraging its fault-tolerant consensus mechanism. Through extensive experiments on three datasets (MNIST, FashionMNIST, and Olivetti), under various attack scenarios including bit-flipping and Gaussian noise injection, we validate the superior resilience of distributed optimization protocols. Compared to traditional aggregation-centric approaches, PDMM achieves higher model utility, faster convergence, and improved stability. Our results highlight the effectiveness of distributed optimization in defending against Byzantine threats, paving the way for more secure and resilient federated learning systems.
From Centralized to Decentralized Federated Learning: Theoretical Insights, Privacy Preservation, and Robustness Challenges
Mar 10, 2025



Federated Learning (FL) enables collaborative learning without directly sharing individual's raw data. FL can be implemented in either a centralized (server-based) or decentralized (peer-to-peer) manner. In this survey, we present a novel perspective: the fundamental difference between centralized FL (CFL) and decentralized FL (DFL) is not merely the network topology, but the underlying training protocol: separate aggregation vs. joint optimization. We argue that this distinction in protocol leads to significant differences in model utility, privacy preservation, and robustness to attacks. We systematically review and categorize existing works in both CFL and DFL according to the type of protocol they employ. This taxonomy provides deeper insights into prior research and clarifies how various approaches relate or differ. Through our analysis, we identify key gaps in the literature. In particular, we observe a surprising lack of exploration of DFL approaches based on distributed optimization methods, despite their potential advantages. We highlight this under-explored direction and call for more research on leveraging distributed optimization for federated learning. Overall, this work offers a comprehensive overview from centralized to decentralized FL, sheds new light on the core distinctions between approaches, and outlines open challenges and future directions for the field.
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Jun 09, 2024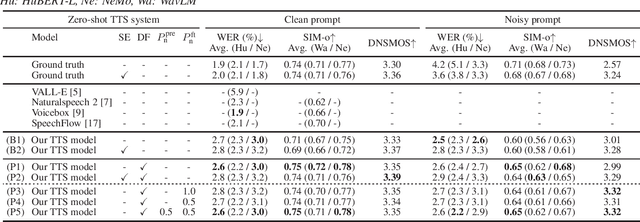
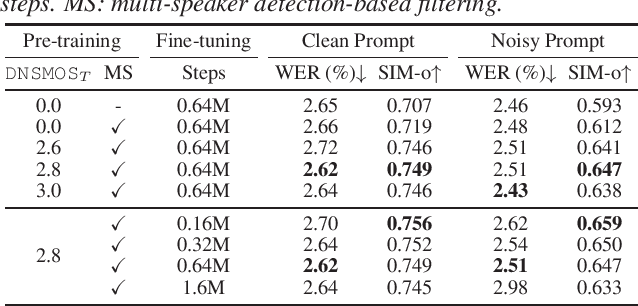
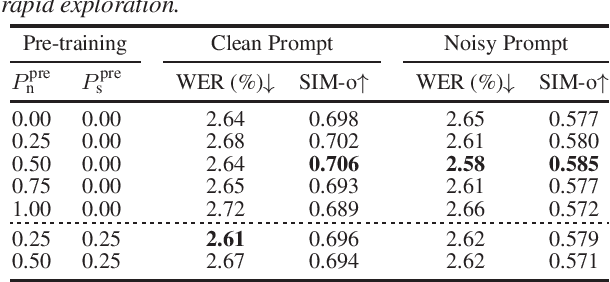
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.