 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024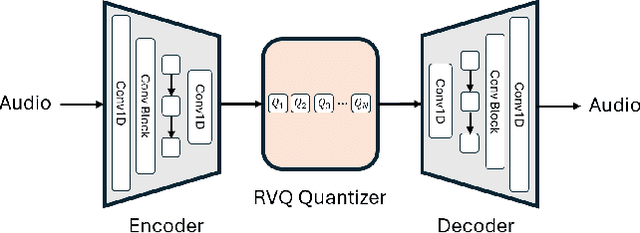

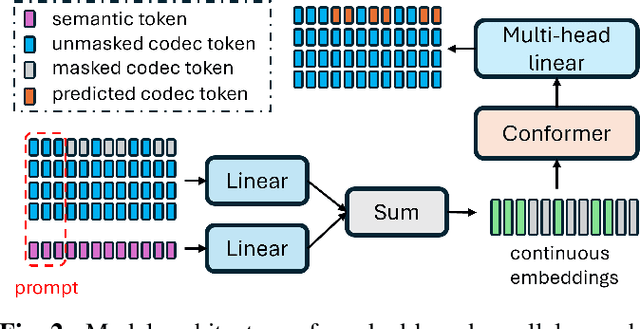
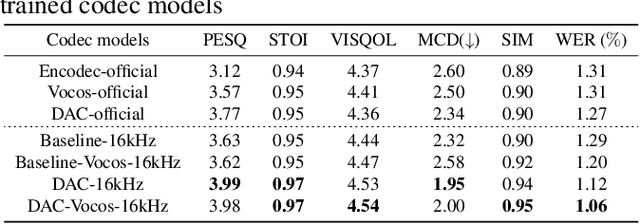
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024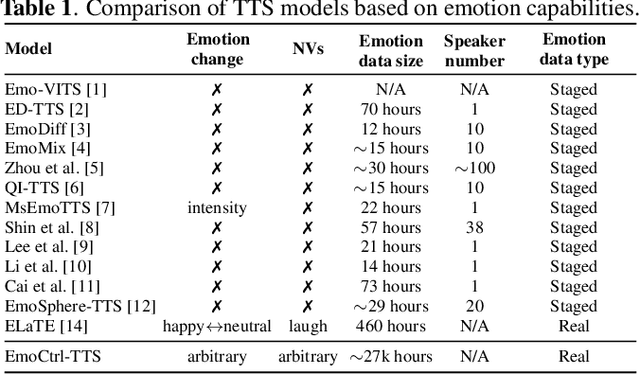
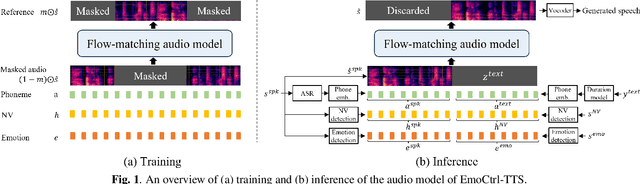
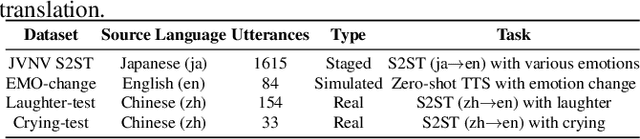
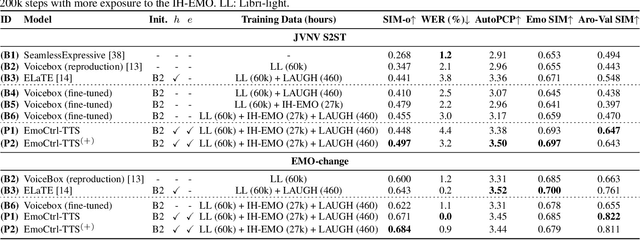
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024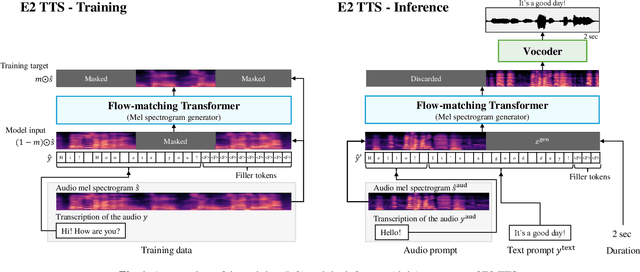
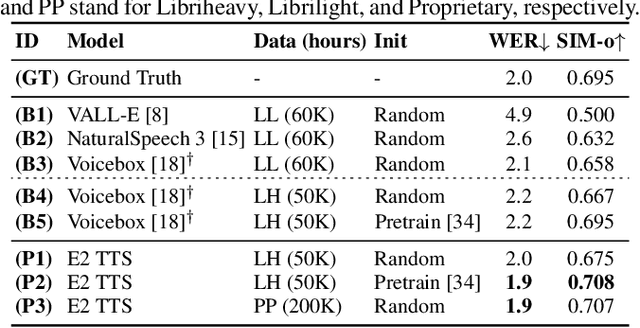
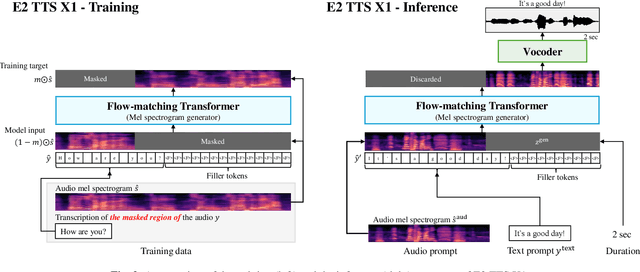
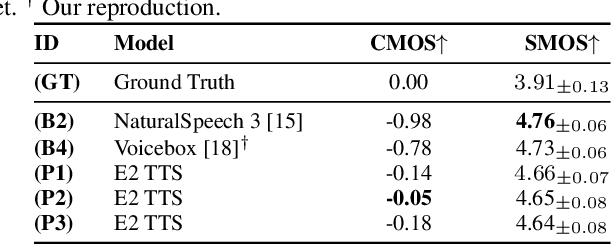
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
Jun 06, 2024



Accurate control of the total duration of generated speech by adjusting the speech rate is crucial for various text-to-speech (TTS) applications. However, the impact of adjusting the speech rate on speech quality, such as intelligibility and speaker characteristics, has been underexplored. In this work, we propose a novel total-duration-aware (TDA) duration model for TTS, where phoneme durations are predicted not only from the text input but also from an additional input of the total target duration. We also propose a MaskGIT-based duration model that enhances the diversity and quality of the predicted phoneme durations. Our results demonstrate that the proposed TDA duration models achieve better intelligibility and speaker similarity for various speech rate configurations compared to the baseline models. We also show that the proposed MaskGIT-based model can generate phoneme durations with higher quality and diversity compared to its regression or flow-matching counterparts.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.