 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024

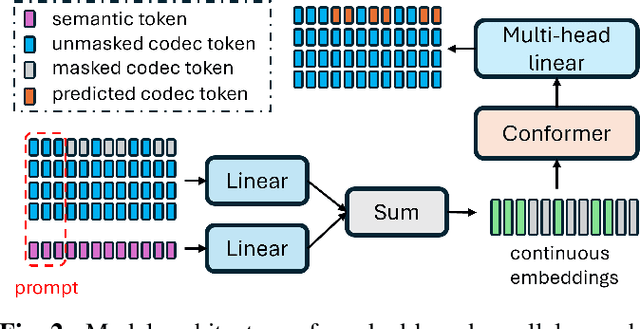
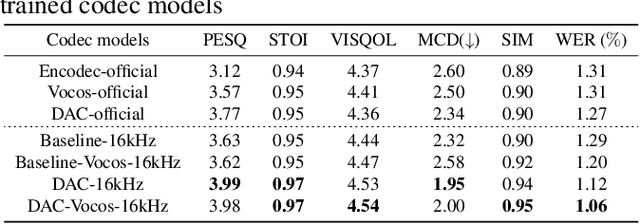
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Apr 10, 2024



Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
Profile-Error-Tolerant Target-Speaker Voice Activity Detection
Sep 21, 2023Target-Speaker Voice Activity Detection (TS-VAD) utilizes a set of speaker profiles alongside an input audio signal to perform speaker diarization. While its superiority over conventional methods has been demonstrated, the method can suffer from errors in speaker profiles, as those profiles are typically obtained by running a traditional clustering-based diarization method over the input signal. This paper proposes an extension to TS-VAD, called Profile-Error-Tolerant TS-VAD (PET-TSVAD), which is robust to such speaker profile errors. This is achieved by employing transformer-based TS-VAD that can handle a variable number of speakers and further introducing a set of additional pseudo-speaker profiles to handle speakers undetected during the first pass diarization. During training, we use speaker profiles estimated by multiple different clustering algorithms to reduce the mismatch between the training and testing conditions regarding speaker profiles. Experimental results show that PET-TSVAD consistently outperforms the existing TS-VAD method on both the VoxConverse and DIHARD-I datasets.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023



State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.
Target Sound Extraction with Variable Cross-modality Clues
Mar 15, 2023



Automatic target sound extraction (TSE) is a machine learning approach to mimic the human auditory perception capability of attending to a sound source of interest from a mixture of sources. It often uses a model conditioned on a fixed form of target sound clues, such as a sound class label, which limits the ways in which users can interact with the model to specify the target sounds. To leverage variable number of clues cross modalities available in the inference phase, including a video, a sound event class, and a text caption, we propose a unified transformer-based TSE model architecture, where a multi-clue attention module integrates all the clues across the modalities. Since there is no off-the-shelf benchmark to evaluate our proposed approach, we build a dataset based on public corpora, Audioset and AudioCaps. Experimental results for seen and unseen target-sound evaluation sets show that our proposed TSE model can effectively deal with a varying number of clues which improves the TSE performance and robustness against partially compromised clues.
Target Speaker Voice Activity Detection with Transformers and Its Integration with End-to-End Neural Diarization
Aug 27, 2022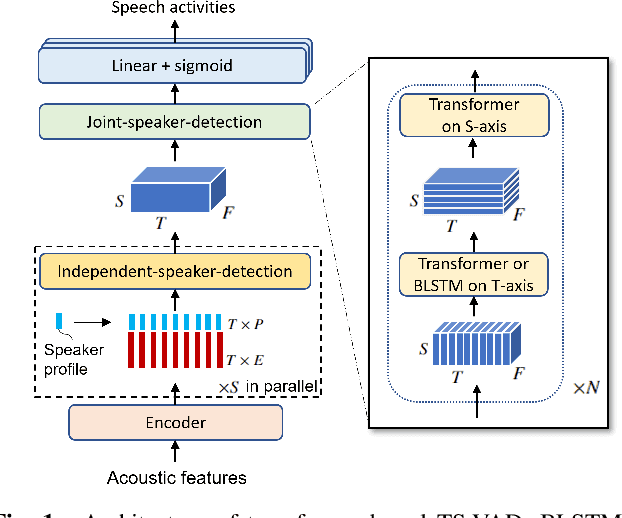
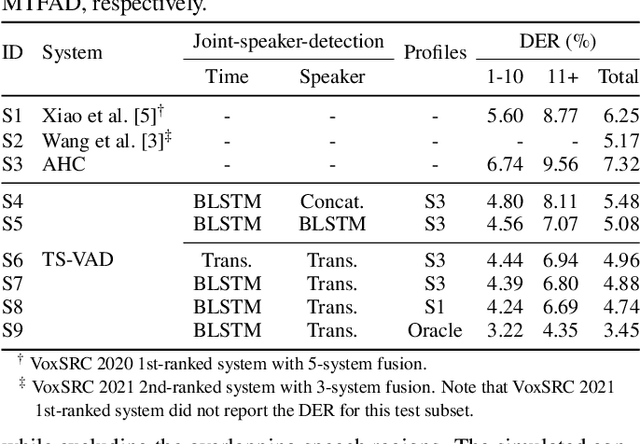
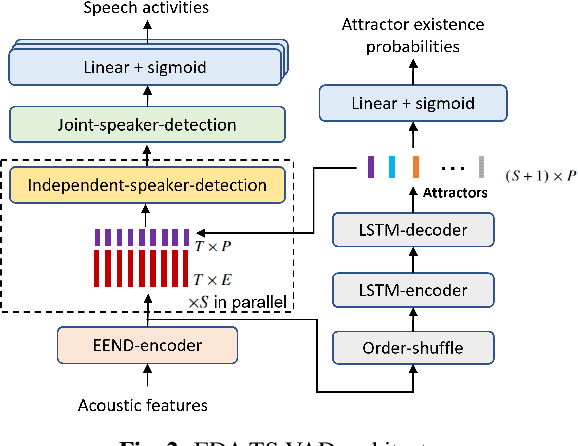
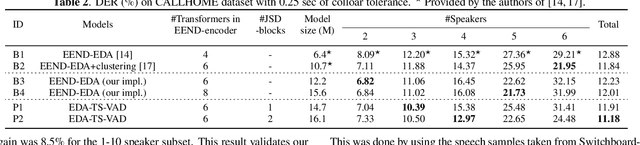
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 10.9%, achieving a new state-of-the-art (SOTA) DER of 4.74%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
Leveraging Real Conversational Data for Multi-Channel Continuous Speech Separation
Apr 07, 2022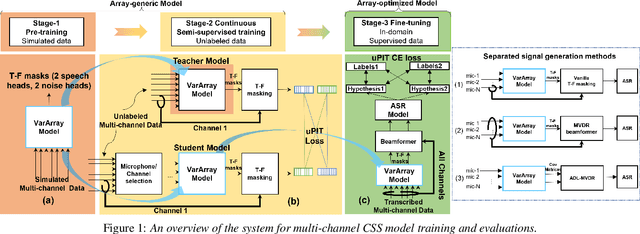
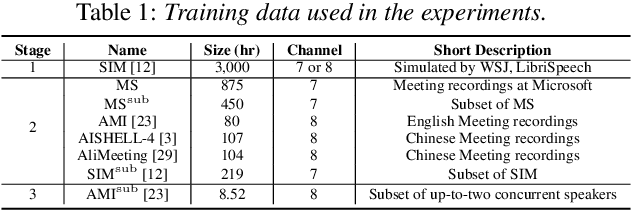
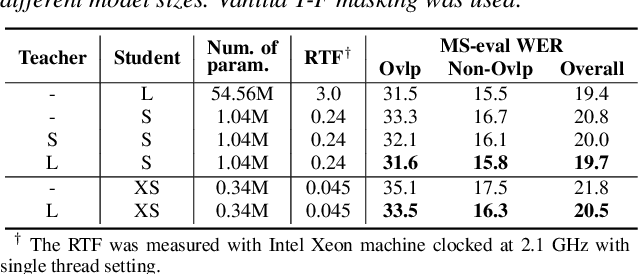

Existing multi-channel continuous speech separation (CSS) models are heavily dependent on supervised data - either simulated data which causes data mismatch between the training and real-data testing, or the real transcribed overlapping data, which is difficult to be acquired, hindering further improvements in the conversational/meeting transcription tasks. In this paper, we propose a three-stage training scheme for the CSS model that can leverage both supervised data and extra large-scale unsupervised real-world conversational data. The scheme consists of two conventional training approaches -- pre-training using simulated data and ASR-loss-based training using transcribed data -- and a novel continuous semi-supervised training between the two, in which the CSS model is further trained by using real data based on the teacher-student learning framework. We apply this scheme to an array-geometry-agnostic CSS model, which can use the multi-channel data collected from any microphone array. Large-scale meeting transcription experiments are carried out on both Microsoft internal meeting data and the AMI meeting corpus. The steady improvement by each training stage has been observed, showing the effect of the proposed method that enables leveraging real conversational data for CSS model training.
PickNet: Real-Time Channel Selection for Ad Hoc Microphone Arrays
Jan 24, 2022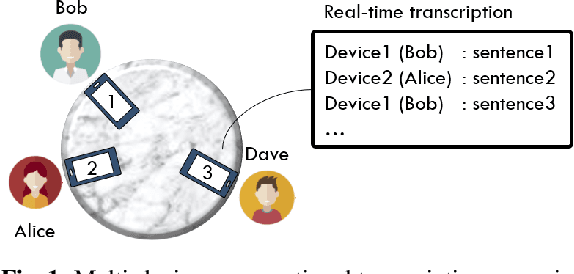
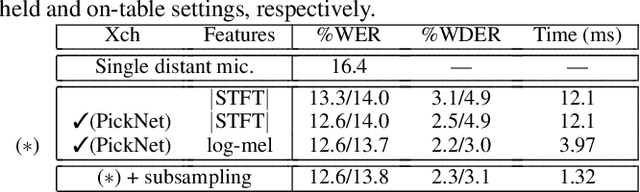
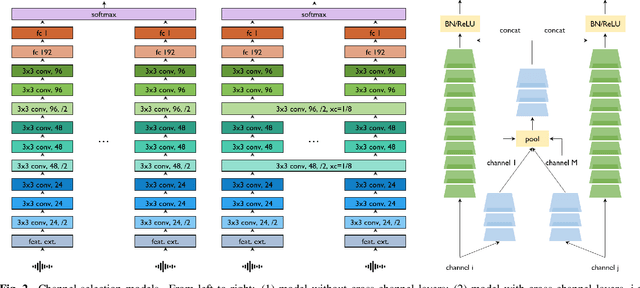
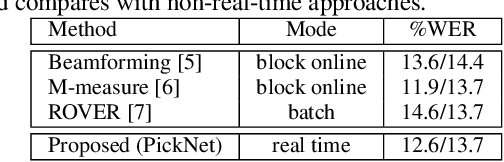
This paper proposes PickNet, a neural network model for real-time channel selection for an ad hoc microphone array consisting of multiple recording devices like cell phones. Assuming at most one person to be vocally active at each time point, PickNet identifies the device that is spatially closest to the active person for each time frame by using a short spectral patch of just hundreds of milliseconds. The model is applied to every time frame, and the short time frame signals from the selected microphones are concatenated across the frames to produce an output signal. As the personal devices are usually held close to their owners, the output signal is expected to have higher signal-to-noise and direct-to-reverberation ratios on average than the input signals. Since PickNet utilizes only limited acoustic context at each time frame, the system using the proposed model works in real time and is robust to changes in acoustic conditions. Speech recognition-based evaluation was carried out by using real conversational recordings obtained with various smartphones. The proposed model yielded significant gains in word error rate with limited computational cost over systems using a block-online beamformer and a single distant microphone.