 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal-2-TF: Robust All-Neural Text Formatting for ASR
Jan 10, 2025This paper introduces an all-neural text formatting (TF) model designed for commercial automatic speech recognition (ASR) systems, encompassing punctuation restoration (PR), truecasing, and inverse text normalization (ITN). Unlike traditional rule-based or hybrid approaches, this method leverages a two-stage neural architecture comprising a multi-objective token classifier and a sequence-to-sequence (seq2seq) model. This design minimizes computational costs and reduces hallucinations while ensuring flexibility and robustness across diverse linguistic entities and text domains. Developed as part of the Universal-2 ASR system, the proposed method demonstrates superior performance in TF accuracy, computational efficiency, and perceptual quality, as validated through comprehensive evaluations using both objective and subjective methods. This work underscores the importance of holistic TF models in enhancing ASR usability in practical settings.
Target conversation extraction: Source separation using turn-taking dynamics
Jul 15, 2024
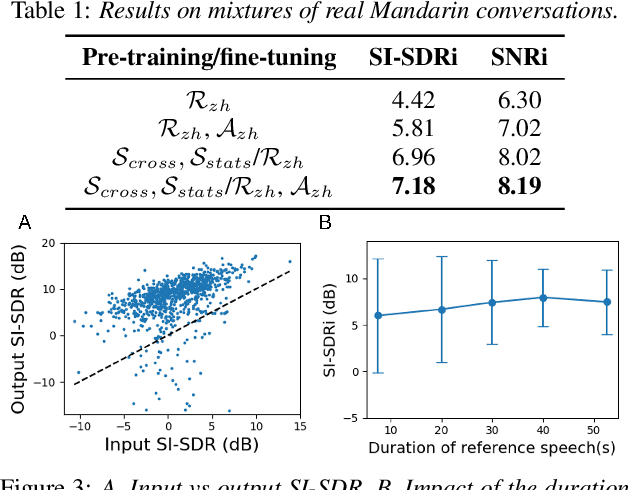
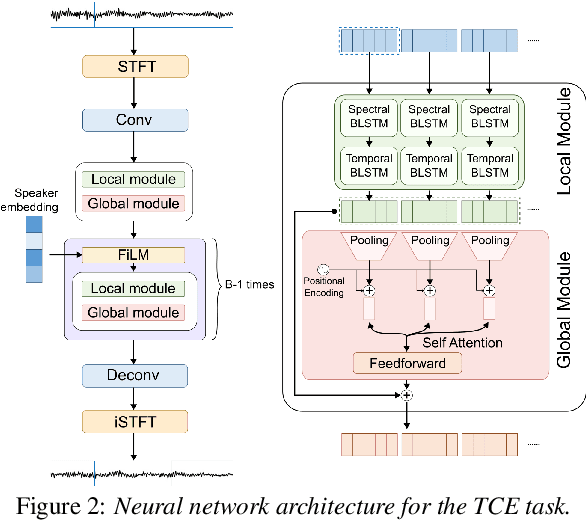

Extracting the speech of participants in a conversation amidst interfering speakers and noise presents a challenging problem. In this paper, we introduce the novel task of target conversation extraction, where the goal is to extract the audio of a target conversation based on the speaker embedding of one of its participants. To accomplish this, we propose leveraging temporal patterns inherent in human conversations, particularly turn-taking dynamics, which uniquely characterize speakers engaged in conversation and distinguish them from interfering speakers and noise. Using neural networks, we show the feasibility of our approach on English and Mandarin conversation datasets. In the presence of interfering speakers, our results show an 8.19 dB improvement in signal-to-noise ratio for 2-speaker conversations and a 7.92 dB improvement for 2-4-speaker conversations. Code, dataset available at https://github.com/chentuochao/Target-Conversation-Extraction.
Look Once to Hear: Target Speech Hearing with Noisy Examples
May 10, 2024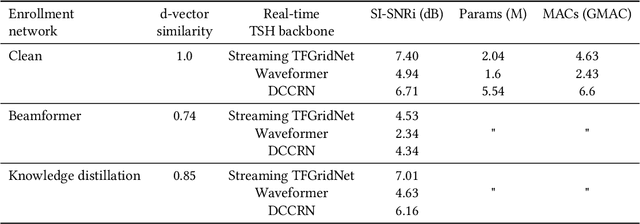
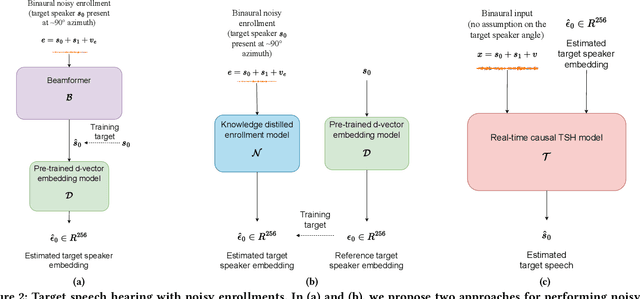

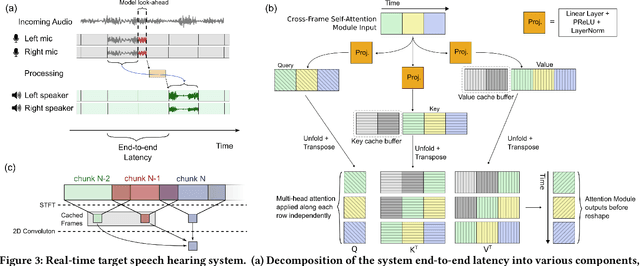
In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the target speaker. A naive approach is to require a clean speech example to enroll the target speaker. This is however not well aligned with the hearable application domain since obtaining a clean example is challenging in real world scenarios, creating a unique user interface problem. We present the first enrollment interface where the wearer looks at the target speaker for a few seconds to capture a single, short, highly noisy, binaural example of the target speaker. This noisy example is used for enrollment and subsequent speech extraction in the presence of interfering speakers and noise. Our system achieves a signal quality improvement of 7.01 dB using less than 5 seconds of noisy enrollment audio and can process 8 ms of audio chunks in 6.24 ms on an embedded CPU. Our user studies demonstrate generalization to real-world static and mobile speakers in previously unseen indoor and outdoor multipath environments. Finally, our enrollment interface for noisy examples does not cause performance degradation compared to clean examples, while being convenient and user-friendly. Taking a step back, this paper takes an important step towards enhancing the human auditory perception with artificial intelligence. We provide code and data at: https://github.com/vb000/LookOnceToHear.
Anatomy of Industrial Scale Multilingual ASR
Apr 16, 2024
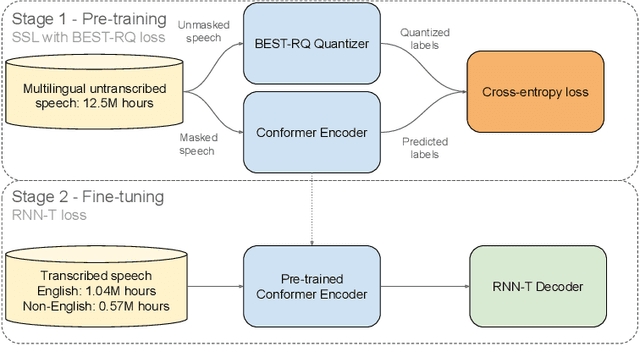


This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023
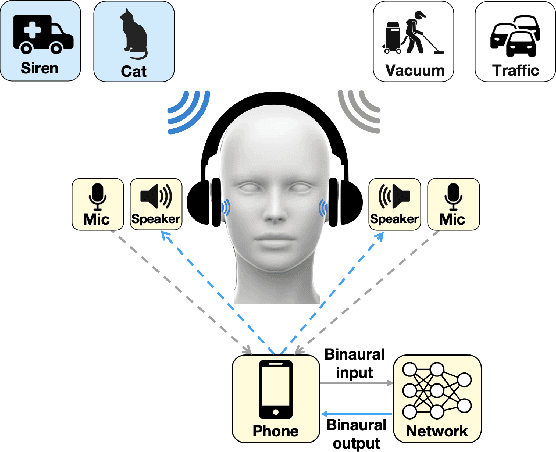
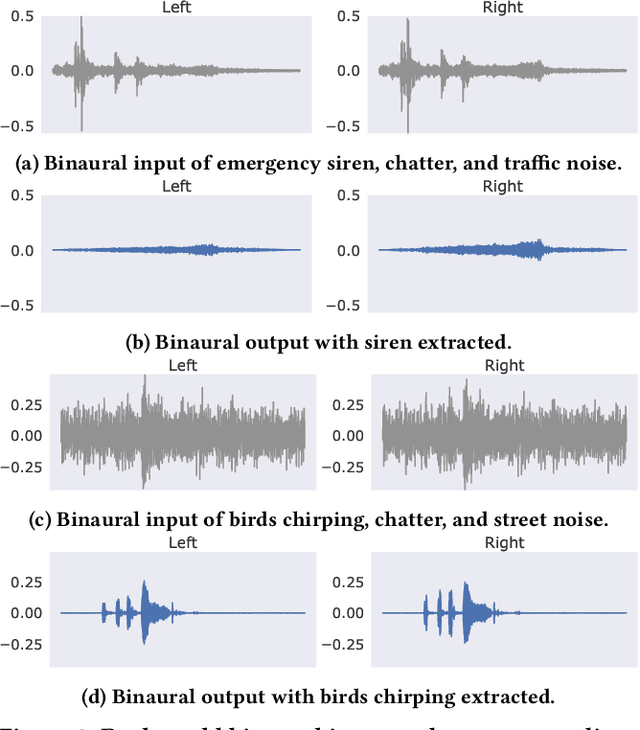
Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu
Profile-Error-Tolerant Target-Speaker Voice Activity Detection
Sep 21, 2023Target-Speaker Voice Activity Detection (TS-VAD) utilizes a set of speaker profiles alongside an input audio signal to perform speaker diarization. While its superiority over conventional methods has been demonstrated, the method can suffer from errors in speaker profiles, as those profiles are typically obtained by running a traditional clustering-based diarization method over the input signal. This paper proposes an extension to TS-VAD, called Profile-Error-Tolerant TS-VAD (PET-TSVAD), which is robust to such speaker profile errors. This is achieved by employing transformer-based TS-VAD that can handle a variable number of speakers and further introducing a set of additional pseudo-speaker profiles to handle speakers undetected during the first pass diarization. During training, we use speaker profiles estimated by multiple different clustering algorithms to reduce the mismatch between the training and testing conditions regarding speaker profiles. Experimental results show that PET-TSVAD consistently outperforms the existing TS-VAD method on both the VoxConverse and DIHARD-I datasets.
t-SOT FNT: Streaming Multi-talker ASR with Text-only Domain Adaptation Capability
Sep 15, 2023Token-level serialized output training (t-SOT) was recently proposed to address the challenge of streaming multi-talker automatic speech recognition (ASR). T-SOT effectively handles overlapped speech by representing multi-talker transcriptions as a single token stream with $\langle \text{cc}\rangle$ symbols interspersed. However, the use of a naive neural transducer architecture significantly constrained its applicability for text-only adaptation. To overcome this limitation, we propose a novel t-SOT model structure that incorporates the idea of factorized neural transducers (FNT). The proposed method separates a language model (LM) from the transducer's predictor and handles the unnatural token order resulting from the use of $\langle \text{cc}\rangle$ symbols in t-SOT. We achieve this by maintaining multiple hidden states and introducing special handling of the $\langle \text{cc}\rangle$ tokens within the LM. The proposed t-SOT FNT model achieves comparable performance to the original t-SOT model while retaining the ability to reduce word error rate (WER) on both single and multi-talker datasets through text-only adaptation.
DiariST: Streaming Speech Translation with Speaker Diarization
Sep 14, 2023

End-to-end speech translation (ST) for conversation recordings involves several under-explored challenges such as speaker diarization (SD) without accurate word time stamps and handling of overlapping speech in a streaming fashion. In this work, we propose DiariST, the first streaming ST and SD solution. It is built upon a neural transducer-based streaming ST system and integrates token-level serialized output training and t-vector, which were originally developed for multi-talker speech recognition. Due to the absence of evaluation benchmarks in this area, we develop a new evaluation dataset, DiariST-AliMeeting, by translating the reference Chinese transcriptions of the AliMeeting corpus into English. We also propose new metrics, called speaker-agnostic BLEU and speaker-attributed BLEU, to measure the ST quality while taking SD accuracy into account. Our system achieves a strong ST and SD capability compared to offline systems based on Whisper, while performing streaming inference for overlapping speech. To facilitate the research in this new direction, we release the evaluation data, the offline baseline systems, and the evaluation code.
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Aug 14, 2023Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023



State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.