 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive noise cancellation on open-ear smart glasses
Apr 07, 2026Smart glasses are becoming an increasingly prevalent wearable platform, with audio as a key interaction modality. However, hearing in noisy environments remains challenging because smart glasses are equipped with open-ear speakers that do not seal the ear canal. Furthermore, the open-ear design is incompatible with conventional active noise cancellation (ANC) techniques, which rely on an error microphone inside or at the entrance of the ear canal to measure the residual sound heard after cancellation. Here we present the first real-time ANC system for open-ear smart glasses that suppresses environmental noise using only microphones and miniaturized open-ear speakers embedded in the glasses frame. Our low-latency computational pipeline estimates the noise at the ear from an array of eight microphones distributed around the glasses frame and generates an anti-noise signal in real-time to cancel environmental noise. We develop a custom glasses prototype and evaluate it in a user study across 8 environments under mobility in the 100--1000 Hz frequency range, where environmental noise is concentrated. We achieve a mean noise reduction of 9.6 dB without any calibration, and 11.2 dB with a brief user-specific calibration.
SonicSieve: Bringing Directional Speech Extraction to Smartphones Using Acoustic Microstructures
Apr 15, 2025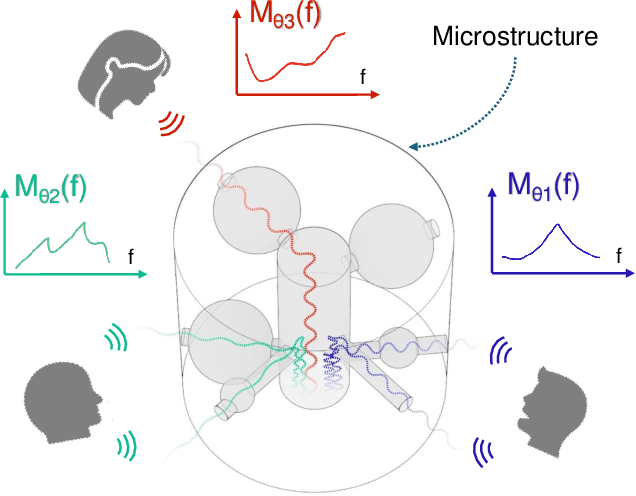
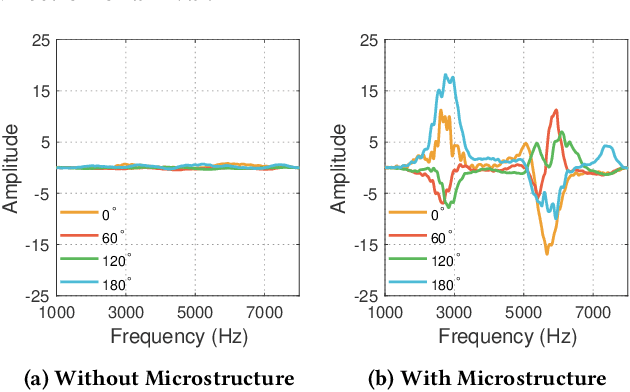
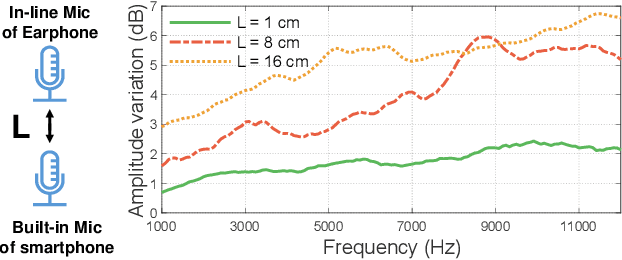
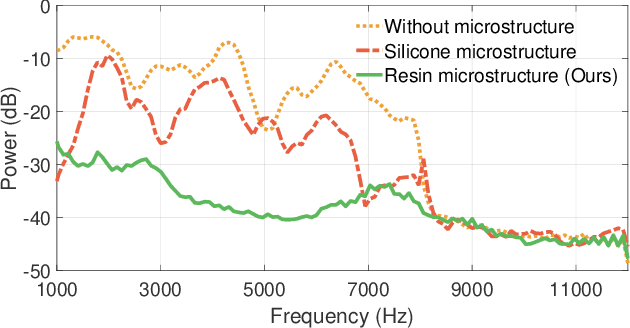
Imagine placing your smartphone on a table in a noisy restaurant and clearly capturing the voices of friends seated around you, or recording a lecturer's voice with clarity in a reverberant auditorium. We introduce SonicSieve, the first intelligent directional speech extraction system for smartphones using a bio-inspired acoustic microstructure. Our passive design embeds directional cues onto incoming speech without any additional electronics. It attaches to the in-line mic of low-cost wired earphones which can be attached to smartphones. We present an end-to-end neural network that processes the raw audio mixtures in real-time on mobile devices. Our results show that SonicSieve achieves a signal quality improvement of 5.0 dB when focusing on a 30{\deg} angular region. Additionally, the performance of our system based on only two microphones exceeds that of conventional 5-microphone arrays.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023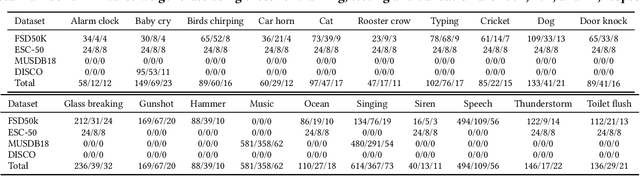
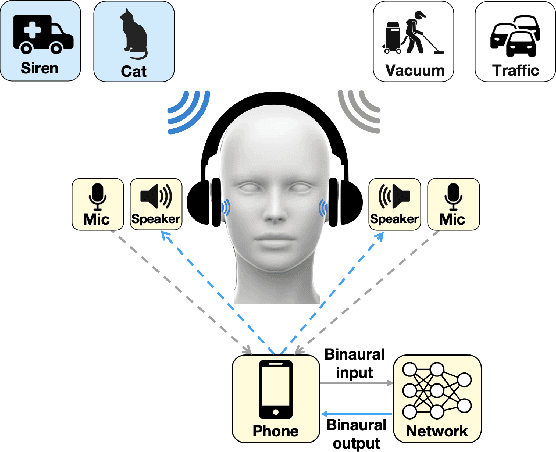
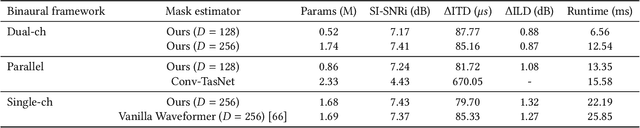
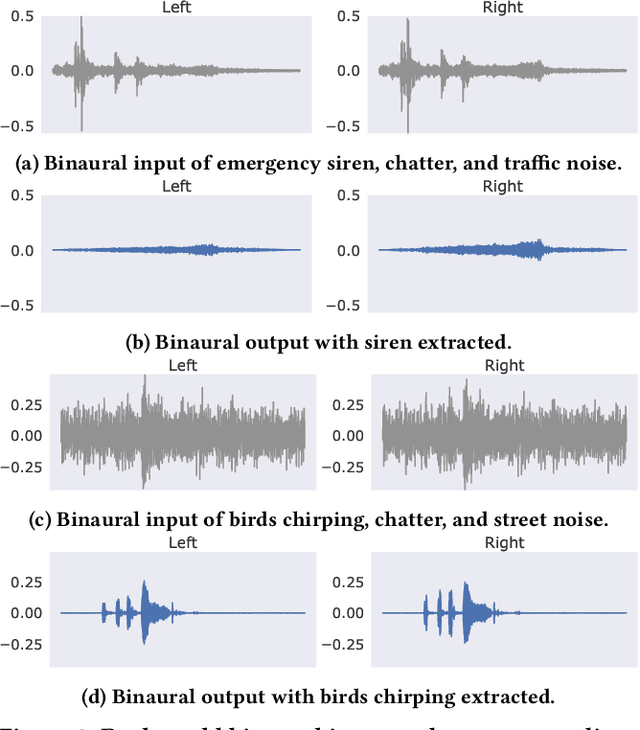
Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu
Underwater 3D positioning on smart devices
Jul 20, 2023



The emergence of water-proof mobile and wearable devices (e.g., Garmin Descent and Apple Watch Ultra) designed for underwater activities like professional scuba diving, opens up opportunities for underwater networking and localization capabilities on these devices. Here, we present the first underwater acoustic positioning system for smart devices. Unlike conventional systems that use floating buoys as anchors at known locations, we design a system where a dive leader can compute the relative positions of all other divers, without any external infrastructure. Our intuition is that in a well-connected network of devices, if we compute the pairwise distances, we can determine the shape of the network topology. By incorporating orientation information about a single diver who is in the visual range of the leader device, we can then estimate the positions of all the remaining divers, even if they are not within sight. We address various practical problems including detecting erroneous distance estimates, addressing rotational and flipping ambiguities as well as designing a distributed timestamp protocol that scales linearly with the number of devices. Our evaluations show that our distributed system running on underwater deployments of 4-5 commodity smart devices can perform pairwise ranging and localization with median errors of 0.5-0.9 m and 0.9-1.6 m
Real-Time Target Sound Extraction
Nov 14, 2022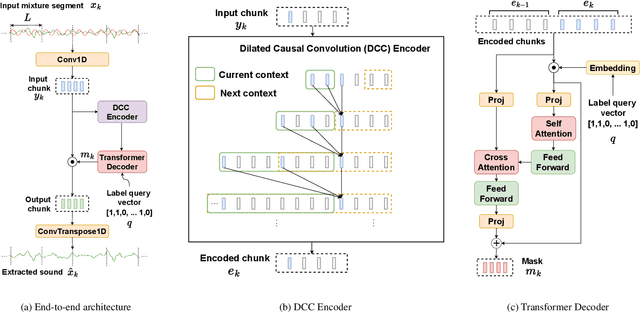

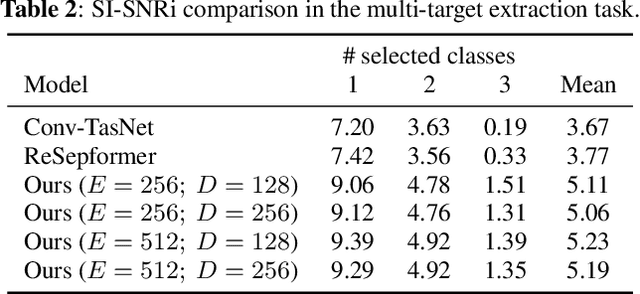
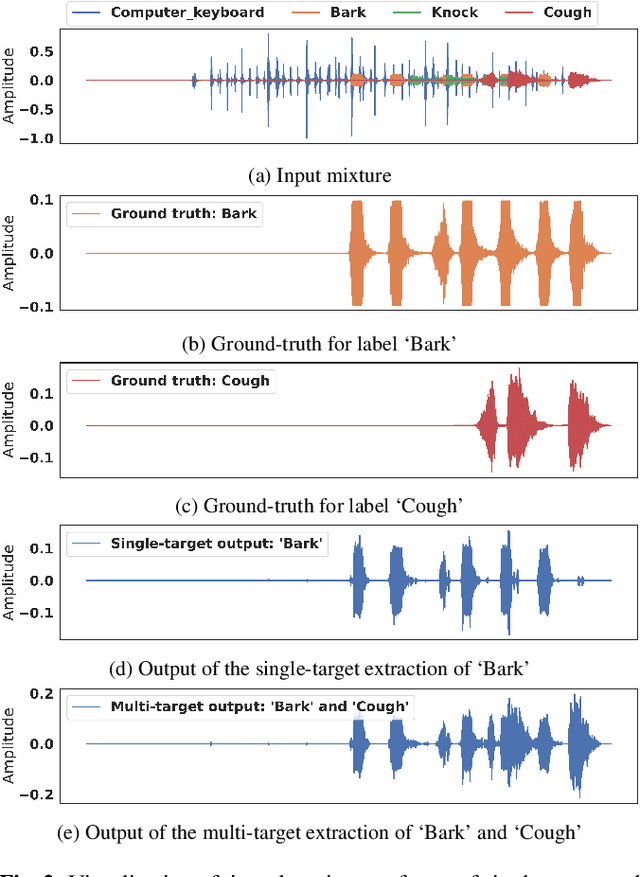
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this, we propose Waveformer, an encoder-decoder architecture with a stack of dilated causal convolution layers as the encoder, and a transformer decoder layer as the decoder. This hybrid architecture uses dilated causal convolutions for processing large receptive fields in a computationally efficient manner, while also benefiting from the performance transformer-based architectures provide. Our evaluations show as much as 2.2-3.3 dB improvement in SI-SNRi compared to the prior models for this task while having a 1.2-4x smaller model size and a 1.5-2x lower runtime. Open-source code and datasets: https://github.com/vb000/Waveformer
Underwater Messaging Using Mobile Devices
Aug 22, 2022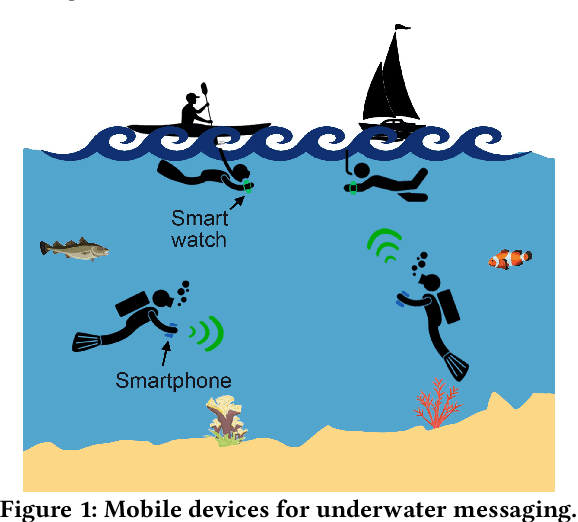
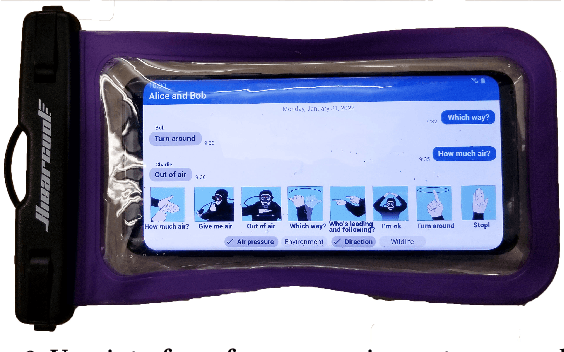
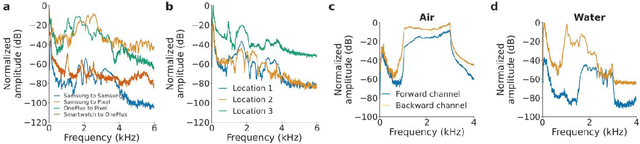
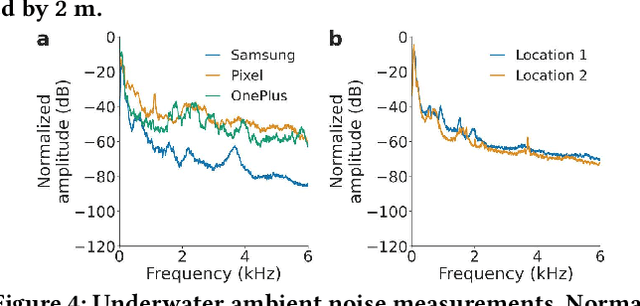
Since its inception, underwater digital acoustic communication has required custom hardware that neither has the economies of scale nor is pervasive. We present the first acoustic system that brings underwater messaging capabilities to existing mobile devices like smartphones and smart watches. Our software-only solution leverages audio sensors, i.e., microphones and speakers, ubiquitous in today's devices to enable acoustic underwater communication between mobile devices. To achieve this, we design a communication system that in real-time adapts to differences in frequency responses across mobile devices, changes in multipath and noise levels at different locations and dynamic channel changes due to mobility. We evaluate our system in six different real-world underwater environments with depths of 2-15 m in the presence of boats, ships and people fishing and kayaking. Our results show that our system can in real-time adapt its frequency band and achieve bit rates of 100 bps to 1.8 kbps and a range of 30 m. By using a lower bit rate of 10-20 bps, we can further increase the range to 100 m. As smartphones and watches are increasingly being used in underwater scenarios, our software-based approach has the potential to make underwater messaging capabilities widely available to anyone with a mobile device. Project page with open-source code and data can be found here: https://underwatermessaging.cs.washington.edu/
Identifying Pediatric Vascular Anomalies With Deep Learning
Sep 16, 2019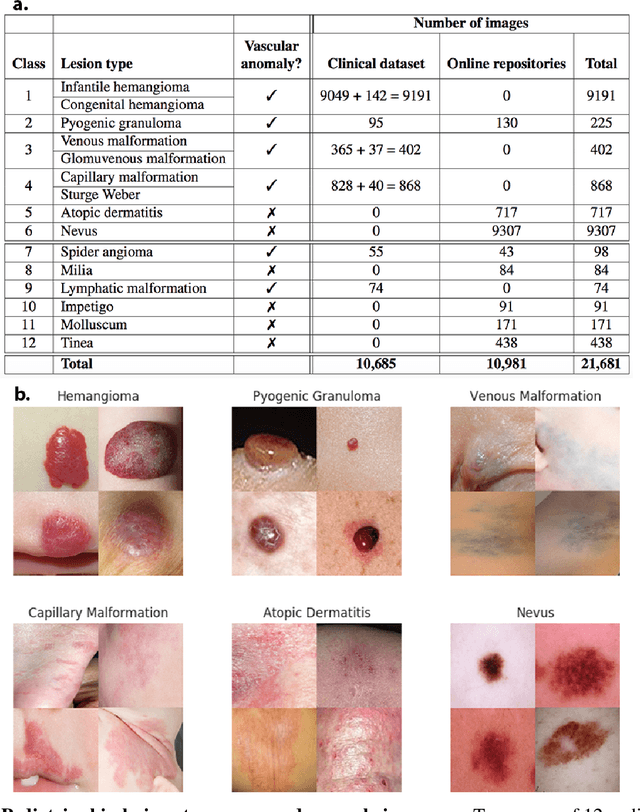
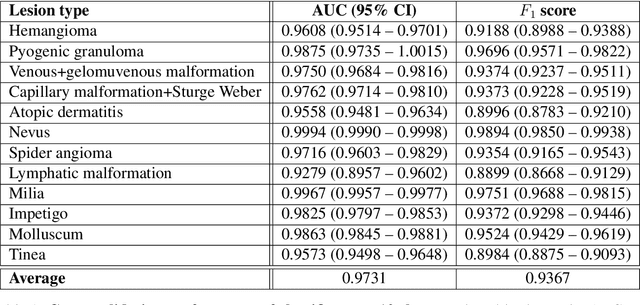
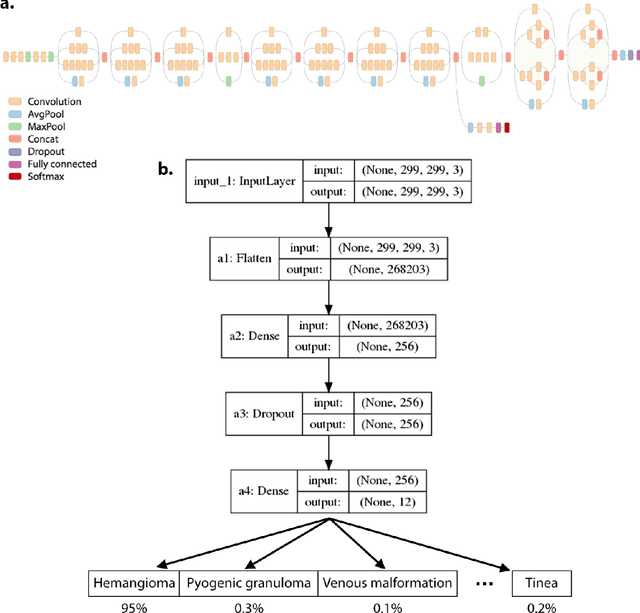

Vascular anomalies, more colloquially known as birthmarks, affect up to 1 in 10 infants. Though many of these lesions self-resolve, some types can result in medical complications or disfigurement without proper diagnosis or management. Accurately diagnosing vascular anomalies is challenging for pediatricians and primary care physicians due to subtle visual differences and similarity to other pediatric dermatologic conditions. This can result in delayed or incorrect referrals for treatment. To address this problem, we developed a convolutional neural network (CNN) to automatically classify images of vascular anomalies and other pediatric skin conditions to aid physicians with diagnosis. We constructed a dataset of 21,681 clinical images, including data collected between 2002-2018 at Seattle Children's hospital as well as five dermatologist-curated online repositories, and built a taxonomy over vascular anomalies and other common pediatric skin lesions. The CNN achieved an average AUC of 0.9731 when ten-fold cross-validation was performed across a taxonomy of 12 classes. The classifier's average AUC and weighted F1 score was 0.9889 and 0.9732 respectively when evaluated on a previously unseen test set of six of these classes. Further, when used as an aid by pediatricians (n = 7), the classifier increased their average visual diagnostic accuracy from 73.10% to 91.67%. The classifier runs in real-time on a smartphone and has the potential to improve diagnosis of these conditions, particularly in resource-limited areas.