 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Hearing Assistants that Isolate Egocentric Conversations
Nov 14, 2025We introduce proactive hearing assistants that automatically identify and separate the wearer's conversation partners, without requiring explicit prompts. Our system operates on egocentric binaural audio and uses the wearer's self-speech as an anchor, leveraging turn-taking behavior and dialogue dynamics to infer conversational partners and suppress others. To enable real-time, on-device operation, we propose a dual-model architecture: a lightweight streaming model runs every 12.5 ms for low-latency extraction of the conversation partners, while a slower model runs less frequently to capture longer-range conversational dynamics. Results on real-world 2- and 3-speaker conversation test sets, collected with binaural egocentric hardware from 11 participants totaling 6.8 hours, show generalization in identifying and isolating conversational partners in multi-conversation settings. Our work marks a step toward hearing assistants that adapt proactively to conversational dynamics and engagement. More information can be found on our website: https://proactivehearing.cs.washington.edu/
* Accepted at EMNLP 2025 Main Conference
Wireless Hearables With Programmable Speech AI Accelerators
Mar 24, 2025The conventional wisdom has been that designing ultra-compact, battery-constrained wireless hearables with on-device speech AI models is challenging due to the high computational demands of streaming deep learning models. Speech AI models require continuous, real-time audio processing, imposing strict computational and I/O constraints. We present NeuralAids, a fully on-device speech AI system for wireless hearables, enabling real-time speech enhancement and denoising on compact, battery-constrained devices. Our system bridges the gap between state-of-the-art deep learning for speech enhancement and low-power AI hardware by making three key technical contributions: 1) a wireless hearable platform integrating a speech AI accelerator for efficient on-device streaming inference, 2) an optimized dual-path neural network designed for low-latency, high-quality speech enhancement, and 3) a hardware-software co-design that uses mixed-precision quantization and quantization-aware training to achieve real-time performance under strict power constraints. Our system processes 6 ms audio chunks in real-time, achieving an inference time of 5.54 ms while consuming 71.6 mW. In real-world evaluations, including a user study with 28 participants, our system outperforms prior on-device models in speech quality and noise suppression, paving the way for next-generation intelligent wireless hearables that can enhance hearing entirely on-device.
Target conversation extraction: Source separation using turn-taking dynamics
Jul 15, 2024
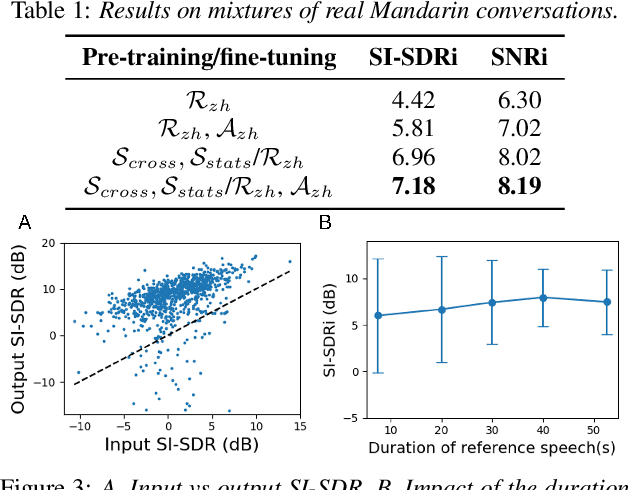
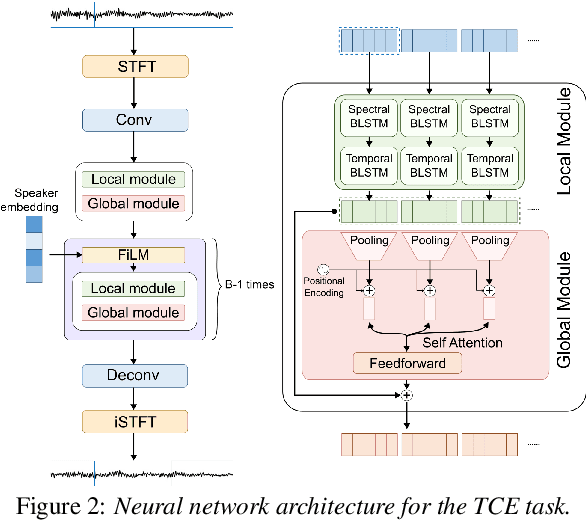

Extracting the speech of participants in a conversation amidst interfering speakers and noise presents a challenging problem. In this paper, we introduce the novel task of target conversation extraction, where the goal is to extract the audio of a target conversation based on the speaker embedding of one of its participants. To accomplish this, we propose leveraging temporal patterns inherent in human conversations, particularly turn-taking dynamics, which uniquely characterize speakers engaged in conversation and distinguish them from interfering speakers and noise. Using neural networks, we show the feasibility of our approach on English and Mandarin conversation datasets. In the presence of interfering speakers, our results show an 8.19 dB improvement in signal-to-noise ratio for 2-speaker conversations and a 7.92 dB improvement for 2-4-speaker conversations. Code, dataset available at https://github.com/chentuochao/Target-Conversation-Extraction.
Look Once to Hear: Target Speech Hearing with Noisy Examples
May 10, 2024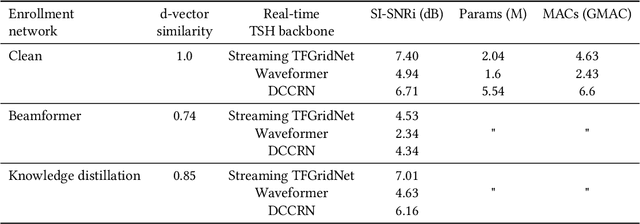
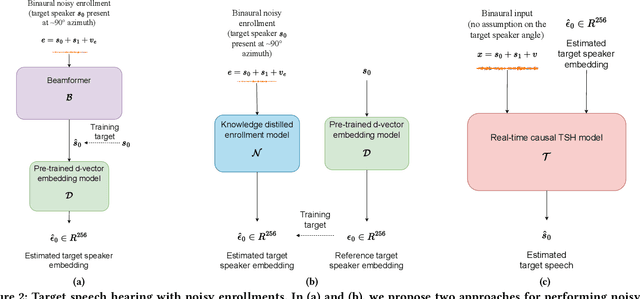

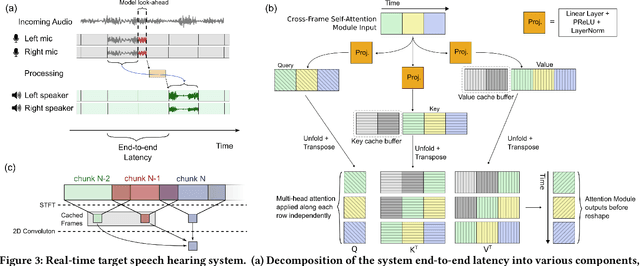
In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the target speaker. A naive approach is to require a clean speech example to enroll the target speaker. This is however not well aligned with the hearable application domain since obtaining a clean example is challenging in real world scenarios, creating a unique user interface problem. We present the first enrollment interface where the wearer looks at the target speaker for a few seconds to capture a single, short, highly noisy, binaural example of the target speaker. This noisy example is used for enrollment and subsequent speech extraction in the presence of interfering speakers and noise. Our system achieves a signal quality improvement of 7.01 dB using less than 5 seconds of noisy enrollment audio and can process 8 ms of audio chunks in 6.24 ms on an embedded CPU. Our user studies demonstrate generalization to real-world static and mobile speakers in previously unseen indoor and outdoor multipath environments. Finally, our enrollment interface for noisy examples does not cause performance degradation compared to clean examples, while being convenient and user-friendly. Taking a step back, this paper takes an important step towards enhancing the human auditory perception with artificial intelligence. We provide code and data at: https://github.com/vb000/LookOnceToHear.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023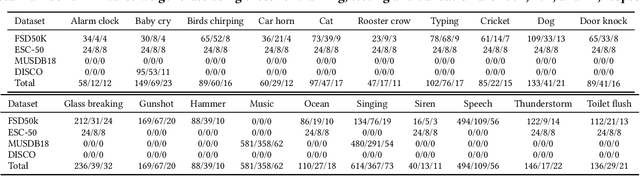
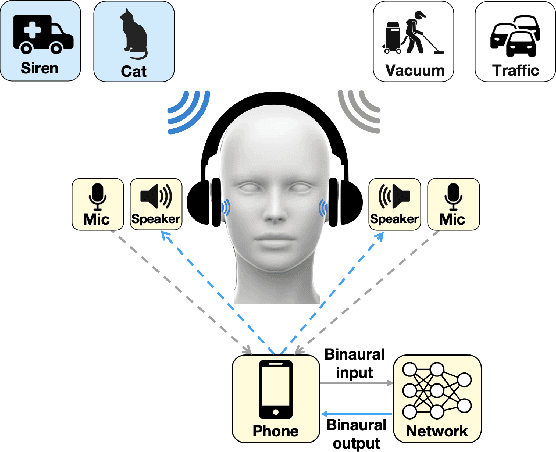
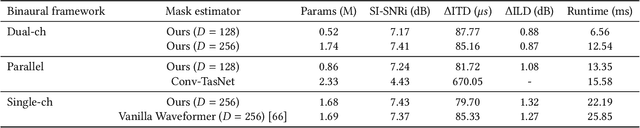
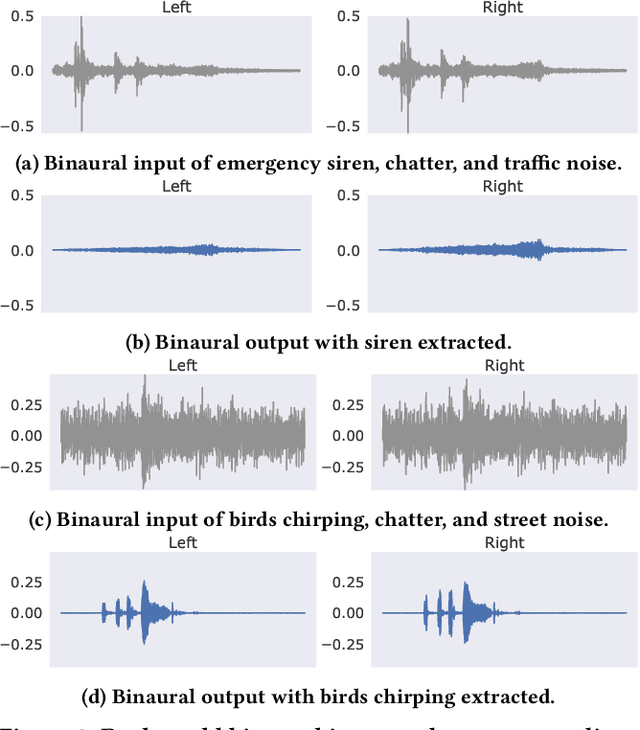
Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu
Real-Time Target Sound Extraction
Nov 14, 2022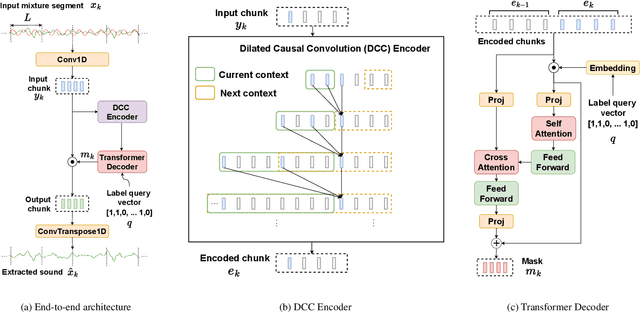

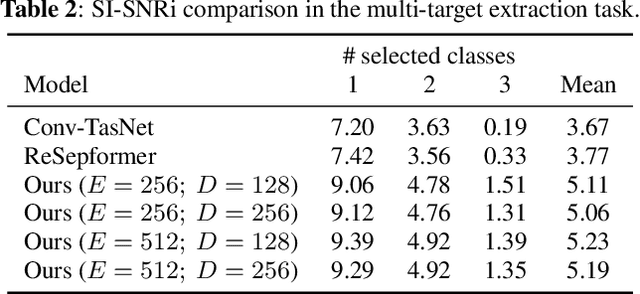
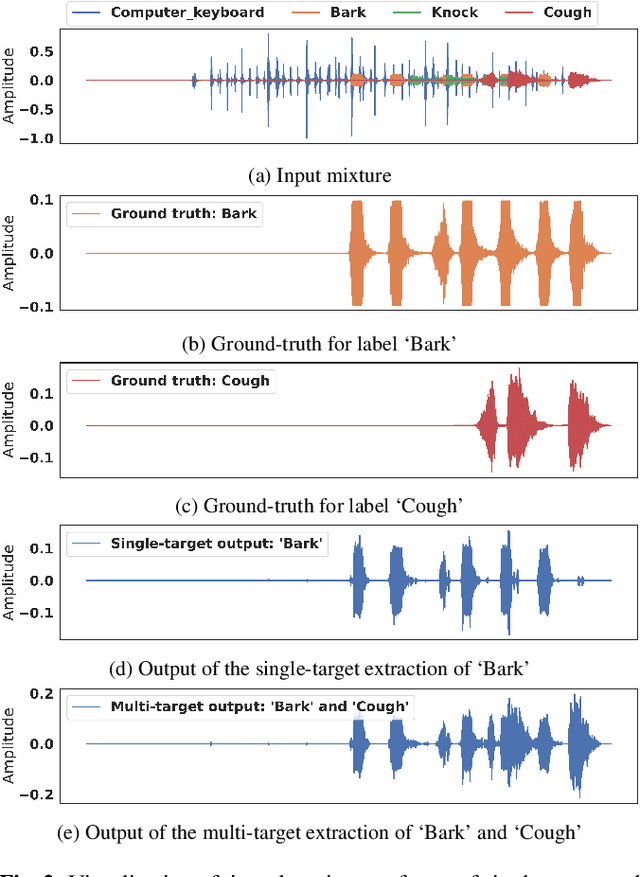
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this, we propose Waveformer, an encoder-decoder architecture with a stack of dilated causal convolution layers as the encoder, and a transformer decoder layer as the decoder. This hybrid architecture uses dilated causal convolutions for processing large receptive fields in a computationally efficient manner, while also benefiting from the performance transformer-based architectures provide. Our evaluations show as much as 2.2-3.3 dB improvement in SI-SNRi compared to the prior models for this task while having a 1.2-4x smaller model size and a 1.5-2x lower runtime. Open-source code and datasets: https://github.com/vb000/Waveformer