 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro Language Models Enable Instant Responses
Apr 21, 2026Edge devices such as smartwatches and smart glasses cannot continuously run even the smallest 100M-1B parameter language models due to power and compute constraints, yet cloud inference introduces multi-second latencies that break the illusion of a responsive assistant. We introduce micro language models ($μ$LMs): ultra-compact models (8M-30M parameters) that instantly generate the first 4-8 words of a contextually grounded response on-device, while a cloud model completes it; thus, masking the cloud latency. We show that useful language generation survives at this extreme scale with our models matching several 70M-256M-class existing models. We design a collaborative generation framework that reframes the cloud model as a continuator rather than a respondent, achieving seamless mid-sentence handoffs and structured graceful recovery via three error correction methods when the local opener goes wrong. Empirical results show that $μ$LMs can initiate responses that larger models complete seamlessly, demonstrating that orders-of-magnitude asymmetric collaboration is achievable and unlocking responsive AI for extremely resource-constrained devices. The model checkpoint and demo are available at https://github.com/Sensente/micro_language_model_swen_project.
Fine-grained Soundscape Control for Augmented Hearing
Mar 04, 2026Hearables are becoming ubiquitous, yet their sound controls remain blunt: users can either enable global noise suppression or focus on a single target sound. Real-world acoustic scenes, however, contain many simultaneous sources that users may want to adjust independently. We introduce Aurchestra, the first system to provide fine-grained, real-time soundscape control on resource-constrained hearables. Our system has two key components: (1) a dynamic interface that surfaces only active sound classes and (2) a real-time, on-device multi-output extraction network that generates separate streams for each selected class, achieving robust performance for upto 5 overlapping target sounds, and letting users mix their environment by customizing per-class volumes, much like an audio engineer mixes tracks. We optimize the model architecture for multiple compute-limited platforms and demonstrate real-time performance on 6 ms streaming audio chunks. Across real-world environments in previously unseen indoor and outdoor scenarios, our system enables expressive per-class sound control and achieves substantial improvements in target-class enhancement and interference suppression. Our results show that the world need not be heard as a single, undifferentiated stream: with Aurchestra, the soundscape becomes truly programmable.
AV-Dialog: Spoken Dialogue Models with Audio-Visual Input
Nov 14, 2025Dialogue models falter in noisy, multi-speaker environments, often producing irrelevant responses and awkward turn-taking. We present AV-Dialog, the first multimodal dialog framework that uses both audio and visual cues to track the target speaker, predict turn-taking, and generate coherent responses. By combining acoustic tokenization with multi-task, multi-stage training on monadic, synthetic, and real audio-visual dialogue datasets, AV-Dialog achieves robust streaming transcription, semantically grounded turn-boundary detection and accurate responses, resulting in a natural conversational flow. Experiments show that AV-Dialog outperforms audio-only models under interference, reducing transcription errors, improving turn-taking prediction, and enhancing human-rated dialogue quality. These results highlight the power of seeing as well as hearing for speaker-aware interaction, paving the way for {spoken} dialogue agents that perform {robustly} in real-world, noisy environments.
Proactive Hearing Assistants that Isolate Egocentric Conversations
Nov 14, 2025We introduce proactive hearing assistants that automatically identify and separate the wearer's conversation partners, without requiring explicit prompts. Our system operates on egocentric binaural audio and uses the wearer's self-speech as an anchor, leveraging turn-taking behavior and dialogue dynamics to infer conversational partners and suppress others. To enable real-time, on-device operation, we propose a dual-model architecture: a lightweight streaming model runs every 12.5 ms for low-latency extraction of the conversation partners, while a slower model runs less frequently to capture longer-range conversational dynamics. Results on real-world 2- and 3-speaker conversation test sets, collected with binaural egocentric hardware from 11 participants totaling 6.8 hours, show generalization in identifying and isolating conversational partners in multi-conversation settings. Our work marks a step toward hearing assistants that adapt proactively to conversational dynamics and engagement. More information can be found on our website: https://proactivehearing.cs.washington.edu/
* Accepted at EMNLP 2025 Main Conference
LLAMAPIE: Proactive In-Ear Conversation Assistants
May 07, 2025



We introduce LlamaPIE, the first real-time proactive assistant designed to enhance human conversations through discreet, concise guidance delivered via hearable devices. Unlike traditional language models that require explicit user invocation, this assistant operates in the background, anticipating user needs without interrupting conversations. We address several challenges, including determining when to respond, crafting concise responses that enhance conversations, leveraging knowledge of the user for context-aware assistance, and real-time, on-device processing. To achieve this, we construct a semi-synthetic dialogue dataset and propose a two-model pipeline: a small model that decides when to respond and a larger model that generates the response. We evaluate our approach on real-world datasets, demonstrating its effectiveness in providing helpful, unobtrusive assistance. User studies with our assistant, implemented on Apple Silicon M2 hardware, show a strong preference for the proactive assistant over both a baseline with no assistance and a reactive model, highlighting the potential of LlamaPie to enhance live conversations.
Wireless Hearables With Programmable Speech AI Accelerators
Mar 24, 2025The conventional wisdom has been that designing ultra-compact, battery-constrained wireless hearables with on-device speech AI models is challenging due to the high computational demands of streaming deep learning models. Speech AI models require continuous, real-time audio processing, imposing strict computational and I/O constraints. We present NeuralAids, a fully on-device speech AI system for wireless hearables, enabling real-time speech enhancement and denoising on compact, battery-constrained devices. Our system bridges the gap between state-of-the-art deep learning for speech enhancement and low-power AI hardware by making three key technical contributions: 1) a wireless hearable platform integrating a speech AI accelerator for efficient on-device streaming inference, 2) an optimized dual-path neural network designed for low-latency, high-quality speech enhancement, and 3) a hardware-software co-design that uses mixed-precision quantization and quantization-aware training to achieve real-time performance under strict power constraints. Our system processes 6 ms audio chunks in real-time, achieving an inference time of 5.54 ms while consuming 71.6 mW. In real-world evaluations, including a user study with 28 participants, our system outperforms prior on-device models in speech quality and noise suppression, paving the way for next-generation intelligent wireless hearables that can enhance hearing entirely on-device.
IRIS: Wireless Ring for Vision-based Smart Home Interaction
Jul 25, 2024



Integrating cameras into wireless smart rings has been challenging due to size and power constraints. We introduce IRIS, the first wireless vision-enabled smart ring system for smart home interactions. Equipped with a camera, Bluetooth radio, inertial measurement unit (IMU), and an onboard battery, IRIS meets the small size, weight, and power (SWaP) requirements for ring devices. IRIS is context-aware, adapting its gesture set to the detected device, and can last for 16-24 hours on a single charge. IRIS leverages the scene semantics to achieve instance-level device recognition. In a study involving 23 participants, IRIS consistently outpaced voice commands, with a higher proportion of participants expressing a preference for IRIS over voice commands regarding toggling a device's state, granular control, and social acceptability. Our work pushes the boundary of what is possible with ring form-factor devices, addressing system challenges and opening up novel interaction capabilities.
Target conversation extraction: Source separation using turn-taking dynamics
Jul 15, 2024
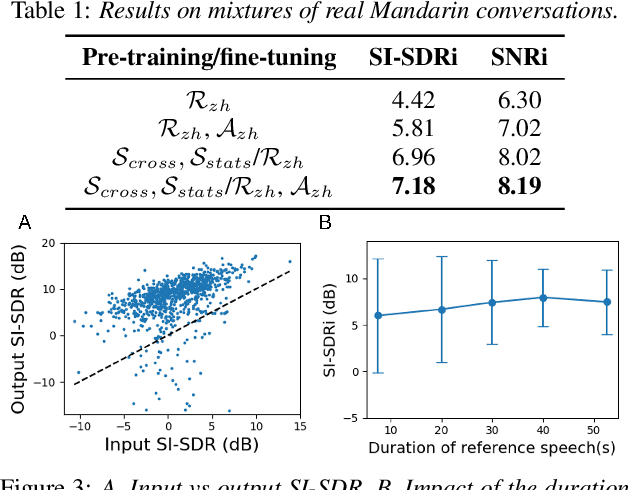
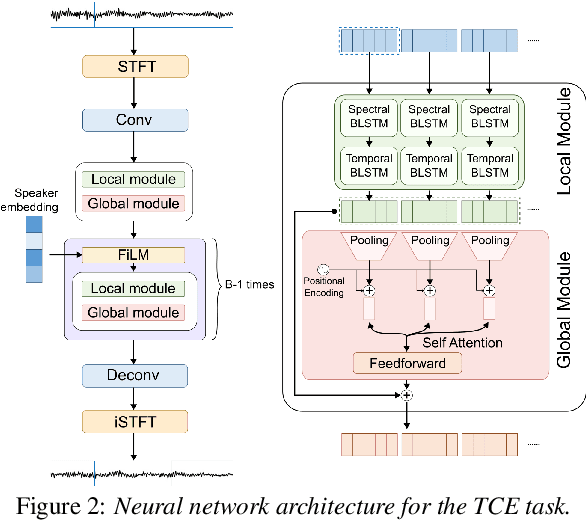

Extracting the speech of participants in a conversation amidst interfering speakers and noise presents a challenging problem. In this paper, we introduce the novel task of target conversation extraction, where the goal is to extract the audio of a target conversation based on the speaker embedding of one of its participants. To accomplish this, we propose leveraging temporal patterns inherent in human conversations, particularly turn-taking dynamics, which uniquely characterize speakers engaged in conversation and distinguish them from interfering speakers and noise. Using neural networks, we show the feasibility of our approach on English and Mandarin conversation datasets. In the presence of interfering speakers, our results show an 8.19 dB improvement in signal-to-noise ratio for 2-speaker conversations and a 7.92 dB improvement for 2-4-speaker conversations. Code, dataset available at https://github.com/chentuochao/Target-Conversation-Extraction.
Look Once to Hear: Target Speech Hearing with Noisy Examples
May 10, 2024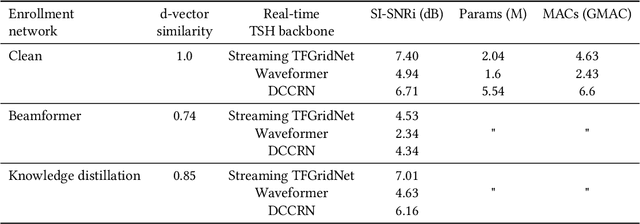
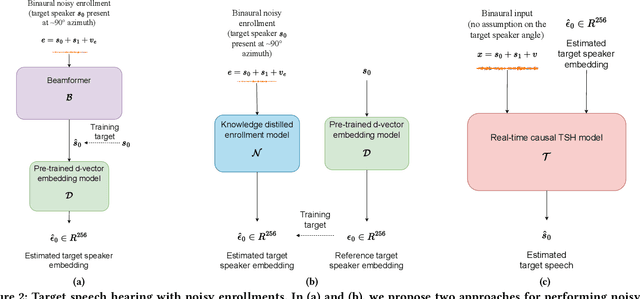

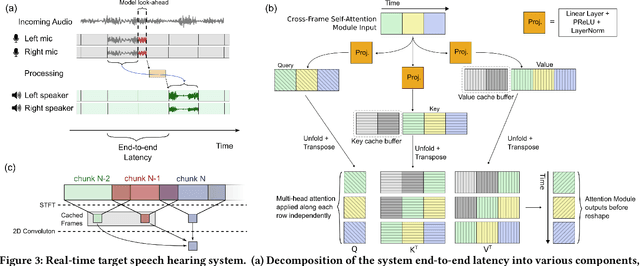
In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the target speaker. A naive approach is to require a clean speech example to enroll the target speaker. This is however not well aligned with the hearable application domain since obtaining a clean example is challenging in real world scenarios, creating a unique user interface problem. We present the first enrollment interface where the wearer looks at the target speaker for a few seconds to capture a single, short, highly noisy, binaural example of the target speaker. This noisy example is used for enrollment and subsequent speech extraction in the presence of interfering speakers and noise. Our system achieves a signal quality improvement of 7.01 dB using less than 5 seconds of noisy enrollment audio and can process 8 ms of audio chunks in 6.24 ms on an embedded CPU. Our user studies demonstrate generalization to real-world static and mobile speakers in previously unseen indoor and outdoor multipath environments. Finally, our enrollment interface for noisy examples does not cause performance degradation compared to clean examples, while being convenient and user-friendly. Taking a step back, this paper takes an important step towards enhancing the human auditory perception with artificial intelligence. We provide code and data at: https://github.com/vb000/LookOnceToHear.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023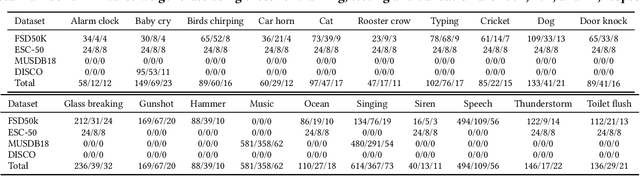
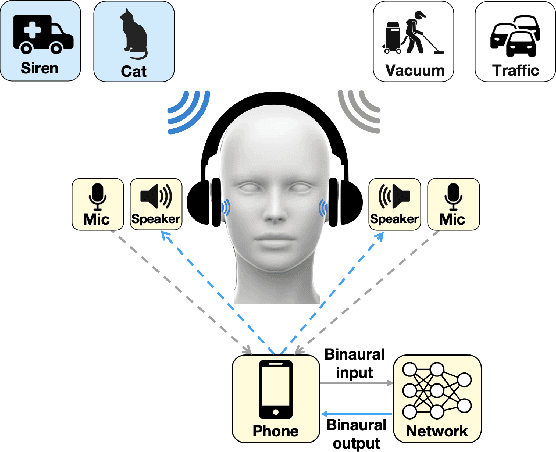
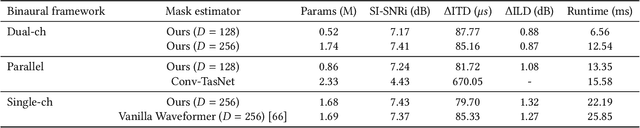
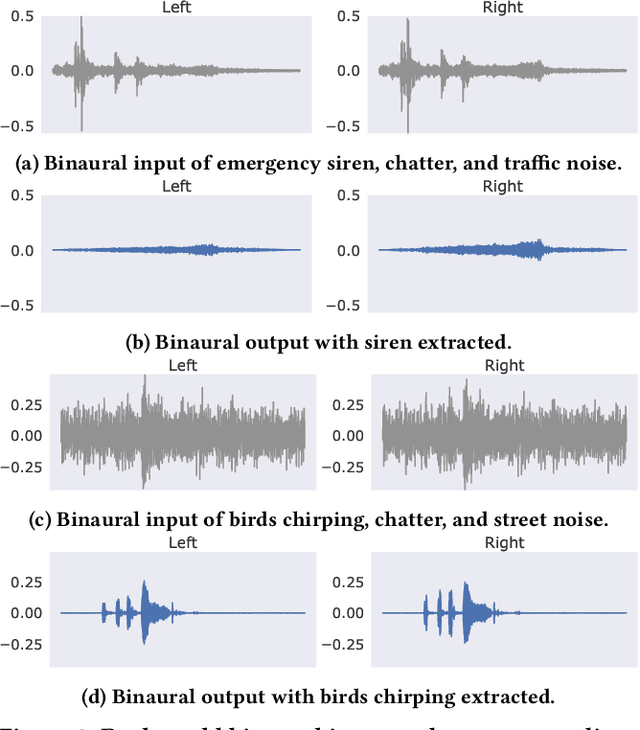
Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu