 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-Dialog: Spoken Dialogue Models with Audio-Visual Input
Nov 14, 2025Dialogue models falter in noisy, multi-speaker environments, often producing irrelevant responses and awkward turn-taking. We present AV-Dialog, the first multimodal dialog framework that uses both audio and visual cues to track the target speaker, predict turn-taking, and generate coherent responses. By combining acoustic tokenization with multi-task, multi-stage training on monadic, synthetic, and real audio-visual dialogue datasets, AV-Dialog achieves robust streaming transcription, semantically grounded turn-boundary detection and accurate responses, resulting in a natural conversational flow. Experiments show that AV-Dialog outperforms audio-only models under interference, reducing transcription errors, improving turn-taking prediction, and enhancing human-rated dialogue quality. These results highlight the power of seeing as well as hearing for speaker-aware interaction, paving the way for {spoken} dialogue agents that perform {robustly} in real-world, noisy environments.
IRIS: Wireless Ring for Vision-based Smart Home Interaction
Jul 25, 2024Integrating cameras into wireless smart rings has been challenging due to size and power constraints. We introduce IRIS, the first wireless vision-enabled smart ring system for smart home interactions. Equipped with a camera, Bluetooth radio, inertial measurement unit (IMU), and an onboard battery, IRIS meets the small size, weight, and power (SWaP) requirements for ring devices. IRIS is context-aware, adapting its gesture set to the detected device, and can last for 16-24 hours on a single charge. IRIS leverages the scene semantics to achieve instance-level device recognition. In a study involving 23 participants, IRIS consistently outpaced voice commands, with a higher proportion of participants expressing a preference for IRIS over voice commands regarding toggling a device's state, granular control, and social acceptability. Our work pushes the boundary of what is possible with ring form-factor devices, addressing system challenges and opening up novel interaction capabilities.
SeamlessExpressiveLM: Speech Language Model for Expressive Speech-to-Speech Translation with Chain-of-Thought
May 30, 2024



Expressive speech-to-speech translation (S2ST) is a key research topic in seamless communication, which focuses on the preservation of semantics and speaker vocal style in translated speech. Early works synthesized speaker style aligned speech in order to directly learn the mapping from speech to target speech spectrogram. Without reliance on style aligned data, recent studies leverage the advances of language modeling (LM) and build cascaded LMs on semantic and acoustic tokens. This work proposes SeamlessExpressiveLM, a single speech language model for expressive S2ST. We decompose the complex source-to-target speech mapping into intermediate generation steps with chain-of-thought prompting. The model is first guided to translate target semantic content and then transfer the speaker style to multi-stream acoustic units. Evaluated on Spanish-to-English and Hungarian-to-English translations, SeamlessExpressiveLM outperforms cascaded LMs in both semantic quality and style transfer, meanwhile achieving better parameter efficiency.
Look Once to Hear: Target Speech Hearing with Noisy Examples
May 10, 2024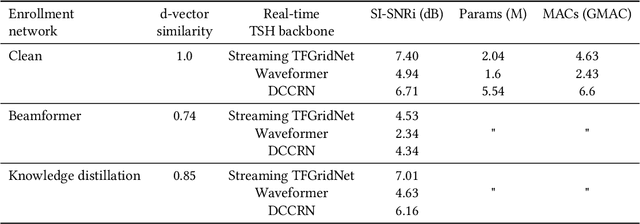
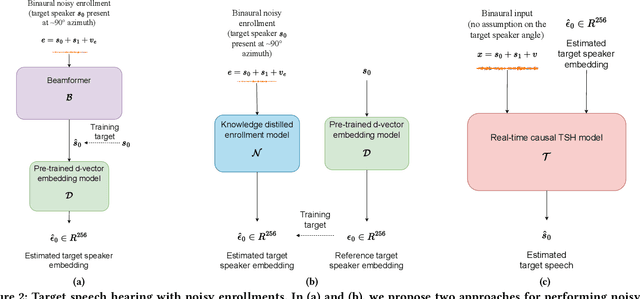

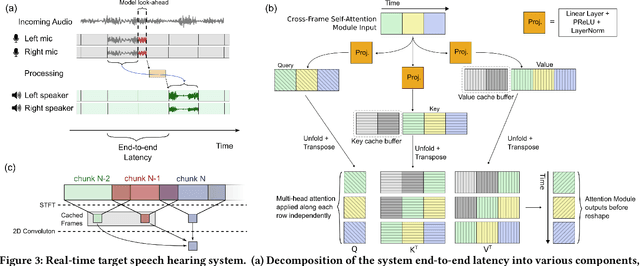
In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the target speaker. A naive approach is to require a clean speech example to enroll the target speaker. This is however not well aligned with the hearable application domain since obtaining a clean example is challenging in real world scenarios, creating a unique user interface problem. We present the first enrollment interface where the wearer looks at the target speaker for a few seconds to capture a single, short, highly noisy, binaural example of the target speaker. This noisy example is used for enrollment and subsequent speech extraction in the presence of interfering speakers and noise. Our system achieves a signal quality improvement of 7.01 dB using less than 5 seconds of noisy enrollment audio and can process 8 ms of audio chunks in 6.24 ms on an embedded CPU. Our user studies demonstrate generalization to real-world static and mobile speakers in previously unseen indoor and outdoor multipath environments. Finally, our enrollment interface for noisy examples does not cause performance degradation compared to clean examples, while being convenient and user-friendly. Taking a step back, this paper takes an important step towards enhancing the human auditory perception with artificial intelligence. We provide code and data at: https://github.com/vb000/LookOnceToHear.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023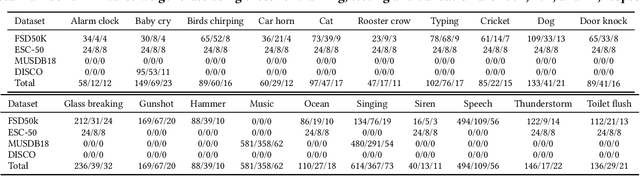
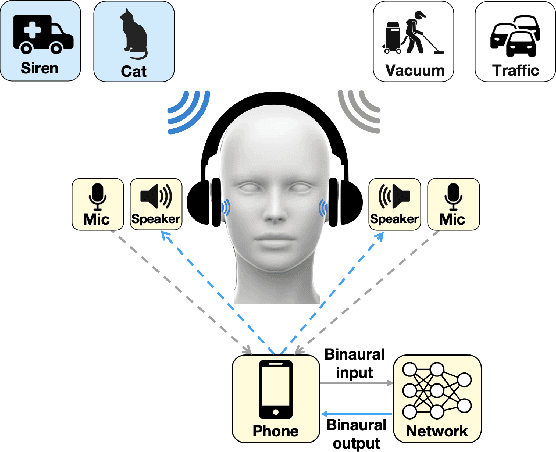
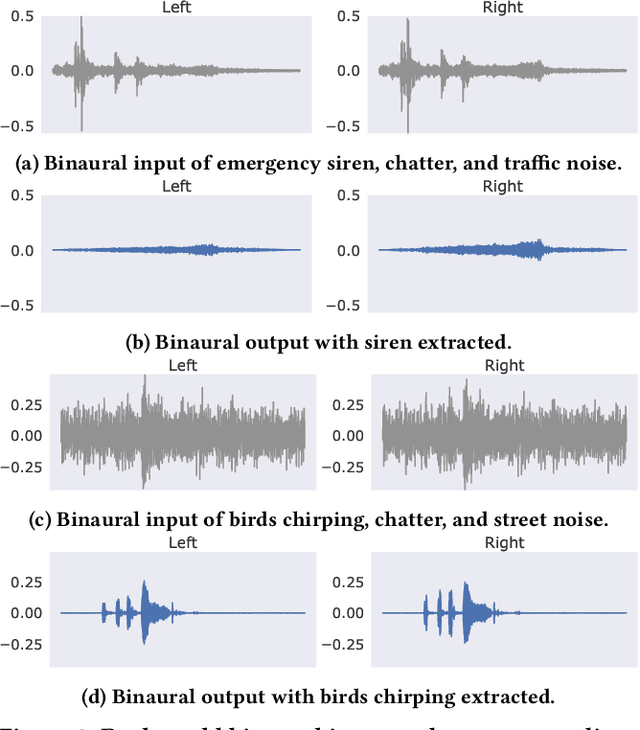
Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu
Real-Time Target Sound Extraction
Nov 14, 2022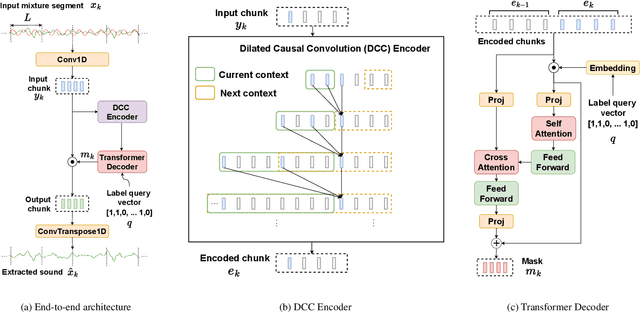

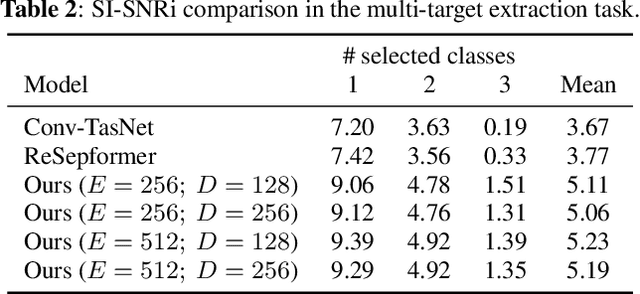
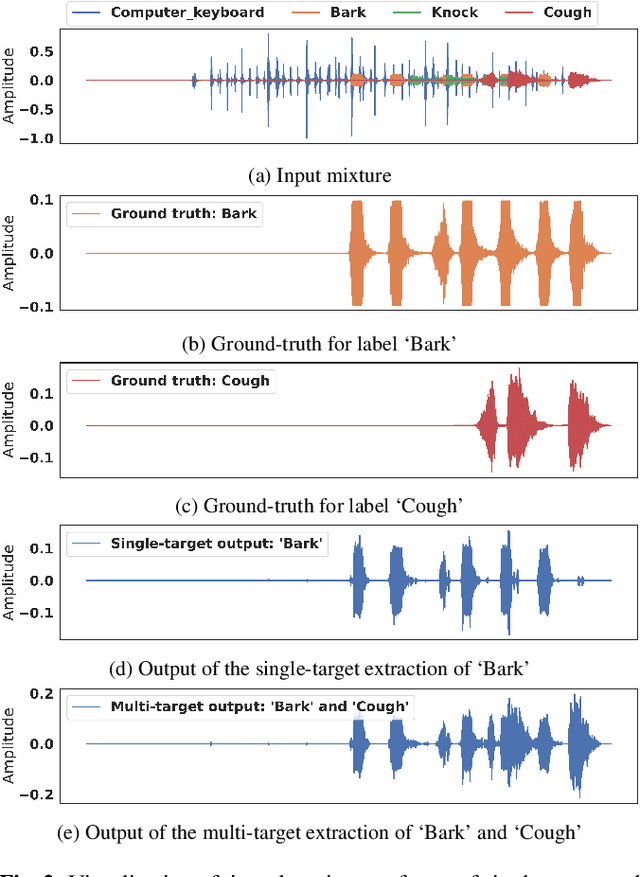
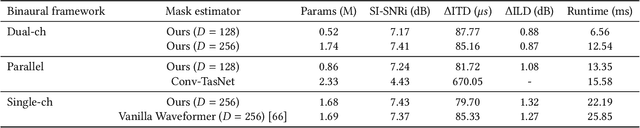
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this, we propose Waveformer, an encoder-decoder architecture with a stack of dilated causal convolution layers as the encoder, and a transformer decoder layer as the decoder. This hybrid architecture uses dilated causal convolutions for processing large receptive fields in a computationally efficient manner, while also benefiting from the performance transformer-based architectures provide. Our evaluations show as much as 2.2-3.3 dB improvement in SI-SNRi compared to the prior models for this task while having a 1.2-4x smaller model size and a 1.5-2x lower runtime. Open-source code and datasets: https://github.com/vb000/Waveformer
NeuriCam: Video Super-Resolution and Colorization Using Key Frames
Jul 25, 2022
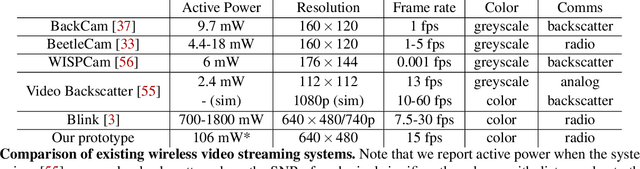
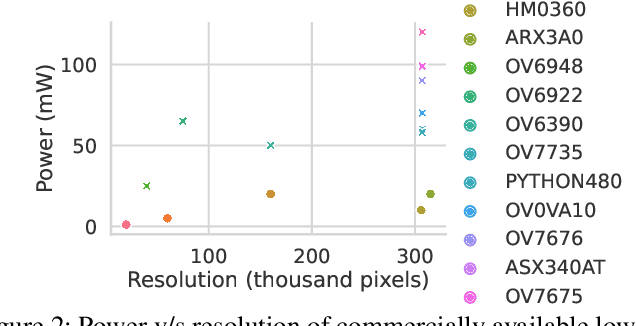
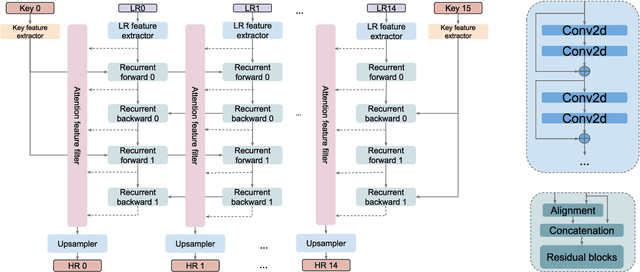
We present NeuriCam, a key-frame video super-resolution and colorization based system, to achieve low-power video capture from dual-mode IOT cameras. Our idea is to design a dual-mode camera system where the first mode is low power (1.1~mW) but only outputs gray-scale, low resolution and noisy video and the second mode consumes much higher power (100~mW) but outputs color and higher resolution images. To reduce total energy consumption, we heavily duty cycle the high power mode to output an image only once every second. The data from this camera system is then wirelessly streamed to a nearby plugged-in gateway, where we run our real-time neural network decoder to reconstruct a higher resolution color video. To achieve this, we introduce an attention feature filter mechanism that assigns different weights to different features, based on the correlation between the feature map and contents of the input frame at each spatial location. We design a wireless hardware prototype using off-the-shelf cameras and address practical issues including packet loss and perspective mismatch. Our evaluation shows that our dual-camera hardware reduces camera energy consumption while achieving an average gray-scale PSNR gain of 3.7~dB over prior video super resolution methods and 5.6~dB RGB gain over existing color propagation methods. Open-source code: https://github.com/vb000/NeuriCam.