 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing XR Auditory Realism via Multimodal Scene-Aware Acoustic Rendering
Nov 14, 2025



In Extended Reality (XR), rendering sound that accurately simulates real-world acoustics is pivotal in creating lifelike and believable virtual experiences. However, existing XR spatial audio rendering methods often struggle with real-time adaptation to diverse physical scenes, causing a sensory mismatch between visual and auditory cues that disrupts user immersion. To address this, we introduce SAMOSA, a novel on-device system that renders spatially accurate sound by dynamically adapting to its physical environment. SAMOSA leverages a synergistic multimodal scene representation by fusing real-time estimations of room geometry, surface materials, and semantic-driven acoustic context. This rich representation then enables efficient acoustic calibration via scene priors, allowing the system to synthesize a highly realistic Room Impulse Response (RIR). We validate our system through technical evaluation using acoustic metrics for RIR synthesis across various room configurations and sound types, alongside an expert evaluation (N=12). Evaluation results demonstrate SAMOSA's feasibility and efficacy in enhancing XR auditory realism.
IRIS: Wireless Ring for Vision-based Smart Home Interaction
Jul 25, 2024



Integrating cameras into wireless smart rings has been challenging due to size and power constraints. We introduce IRIS, the first wireless vision-enabled smart ring system for smart home interactions. Equipped with a camera, Bluetooth radio, inertial measurement unit (IMU), and an onboard battery, IRIS meets the small size, weight, and power (SWaP) requirements for ring devices. IRIS is context-aware, adapting its gesture set to the detected device, and can last for 16-24 hours on a single charge. IRIS leverages the scene semantics to achieve instance-level device recognition. In a study involving 23 participants, IRIS consistently outpaced voice commands, with a higher proportion of participants expressing a preference for IRIS over voice commands regarding toggling a device's state, granular control, and social acceptability. Our work pushes the boundary of what is possible with ring form-factor devices, addressing system challenges and opening up novel interaction capabilities.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022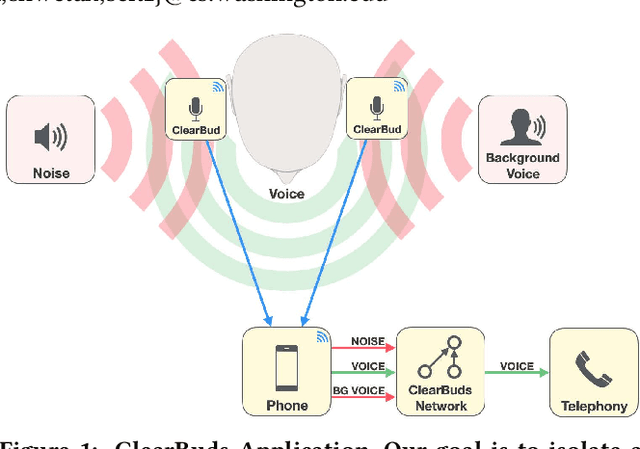

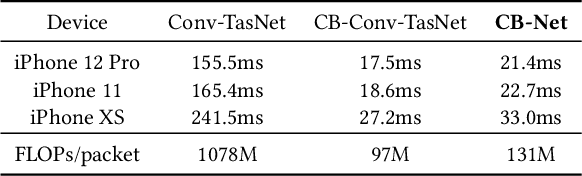
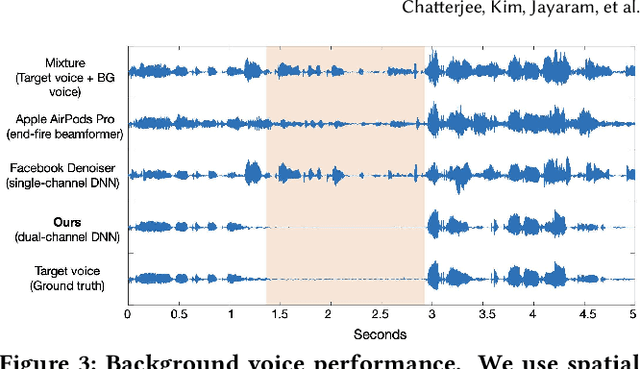
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
Hybrid Neural Networks for On-device Directional Hearing
Dec 11, 2021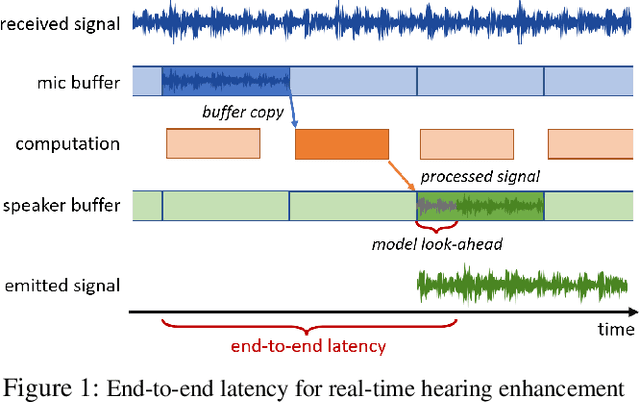

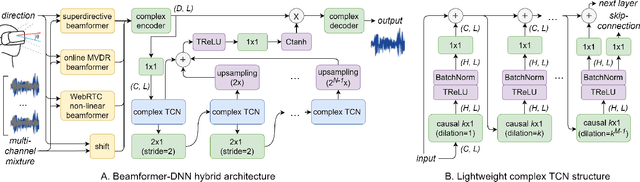
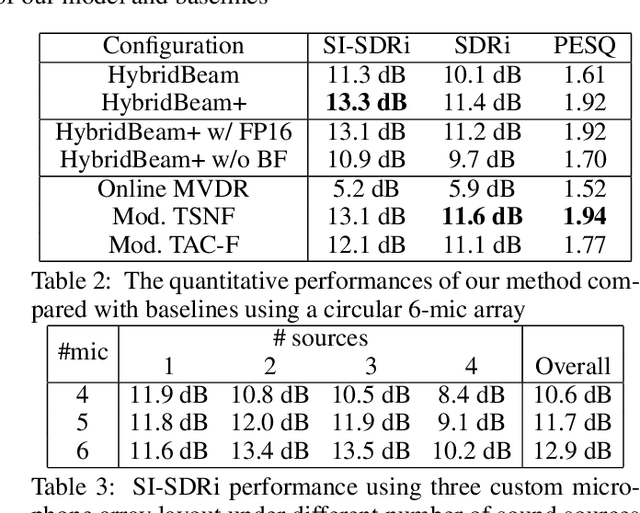
On-device directional hearing requires audio source separation from a given direction while achieving stringent human-imperceptible latency requirements. While neural nets can achieve significantly better performance than traditional beamformers, all existing models fall short of supporting low-latency causal inference on computationally-constrained wearables. We present DeepBeam, a hybrid model that combines traditional beamformers with a custom lightweight neural net. The former reduces the computational burden of the latter and also improves its generalizability, while the latter is designed to further reduce the memory and computational overhead to enable real-time and low-latency operations. Our evaluation shows comparable performance to state-of-the-art causal inference models on synthetic data while achieving a 5x reduction of model size, 4x reduction of computation per second, 5x reduction in processing time and generalizing better to real hardware data. Further, our real-time hybrid model runs in 8 ms on mobile CPUs designed for low-power wearable devices and achieves an end-to-end latency of 17.5 ms.