 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
Spectral Property-Driven Data Augmentation for Hyperspectral Single-Source Domain Generalization
Mar 17, 2026While hyperspectral images (HSI) benefit from numerous spectral channels that provide rich information for classification, the increased dimensionality and sensor variability make them more sensitive to distributional discrepancies across domains, which in turn can affect classification performance. To tackle this issue, hyperspectral single-source domain generalization (SDG) typically employs data augmentation to simulate potential domain shifts and enhance model robustness under the condition of single-source domain training data availability. However, blind augmentation may produce samples misaligned with real-world scenarios, while excessive emphasis on realism can suppress diversity, highlighting a tradeoff between realism and diversity that limits generalization to target domains. To address this challenge, we propose a spectral property-driven data augmentation (SPDDA) that explicitly accounts for the inherent properties of HSI, namely the device-dependent variation in the number of spectral channels and the mixing of adjacent channels. Specifically, SPDDA employs a spectral diversity module that resamples data from the source domain along the spectral dimension to generate samples with varying spectral channels, and constructs a channel-wise adaptive spectral mixer by modeling inter-channel similarity, thereby avoiding fixed augmentation patterns. To further enhance the realism of the augmented samples, we propose a spatial-spectral co-optimization mechanism, which jointly optimizes a spatial fidelity constraint and a spectral continuity self-constraint. Moreover, the weight of the spectral self-constraint is adaptively adjusted based on the spatial counterpart, thus preventing over-smoothing in the spectral dimension and preserving spatial structure. Extensive experiments conducted on three remote sensing benchmarks demonstrate that SPDDA outperforms state-of-the-art methods.
A Reconstruction System for Industrial Pipeline Inner Walls Using Panoramic Image Stitching with Endoscopic Imaging
Feb 28, 2026Visual analysis and reconstruction of pipeline inner walls remain challenging in industrial inspection scenarios. This paper presents a dedicated reconstruction system for pipeline inner walls via industrial endoscopes, which is built on panoramic image stitching technology. Equipped with a custom graphical user interface (GUI), the system extracts key frames from endoscope video footage, and integrates polar coordinate transformation with image stitching techniques to unwrap annular video frames of pipeline inner walls into planar panoramic images. Experimental results demonstrate that the proposed method enables efficient processing of industrial endoscope videos, and the generated panoramic stitched images preserve all detailed features of pipeline inner walls in their entirety. This provides intuitive and accurate visual support for defect detection and condition assessment of pipeline inner walls. In comparison with the traditional frame-by-frame video review method, the proposed approach significantly elevates the efficiency of pipeline inner wall reconstruction and exhibits considerable engineering application value.
A Dual-Branch Local-Global Framework for Cross-Resolution Land Cover Mapping
Dec 23, 2025Cross-resolution land cover mapping aims to produce high-resolution semantic predictions from coarse or low-resolution supervision, yet the severe resolution mismatch makes effective learning highly challenging. Existing weakly supervised approaches often struggle to align fine-grained spatial structures with coarse labels, leading to noisy supervision and degraded mapping accuracy. To tackle this problem, we propose DDTM, a dual-branch weakly supervised framework that explicitly decouples local semantic refinement from global contextual reasoning. Specifically, DDTM introduces a diffusion-based branch to progressively refine fine-scale local semantics under coarse supervision, while a transformer-based branch enforces long-range contextual consistency across large spatial extents. In addition, we design a pseudo-label confidence evaluation module to mitigate noise induced by cross-resolution inconsistencies and to selectively exploit reliable supervisory signals. Extensive experiments demonstrate that DDTM establishes a new state-of-the-art on the Chesapeake Bay benchmark, achieving 66.52\% mIoU and substantially outperforming prior weakly supervised methods. The code is available at https://github.com/gpgpgp123/DDTM.
A Semantically Enhanced Generative Foundation Model Improves Pathological Image Synthesis
Dec 16, 2025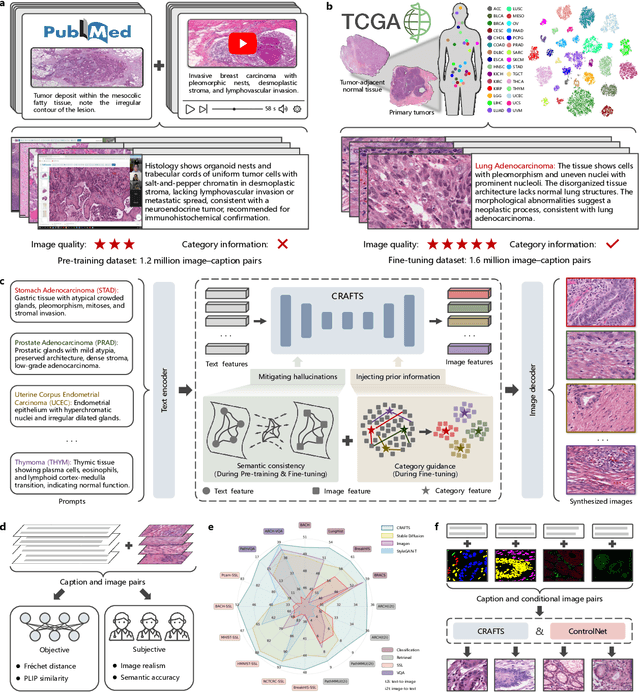
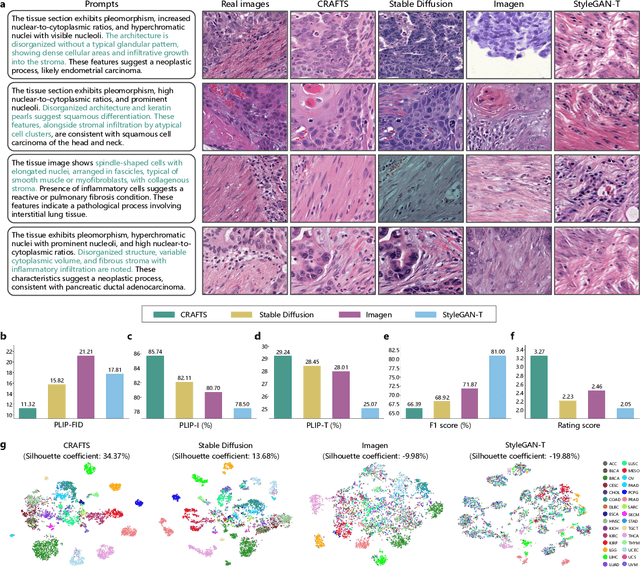
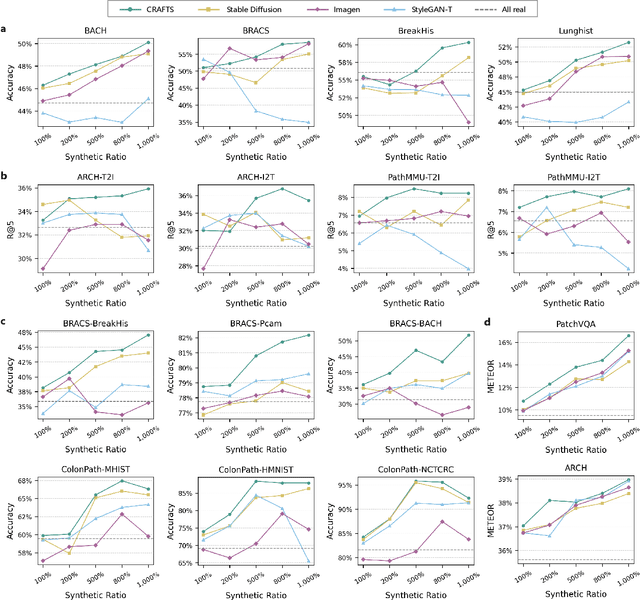
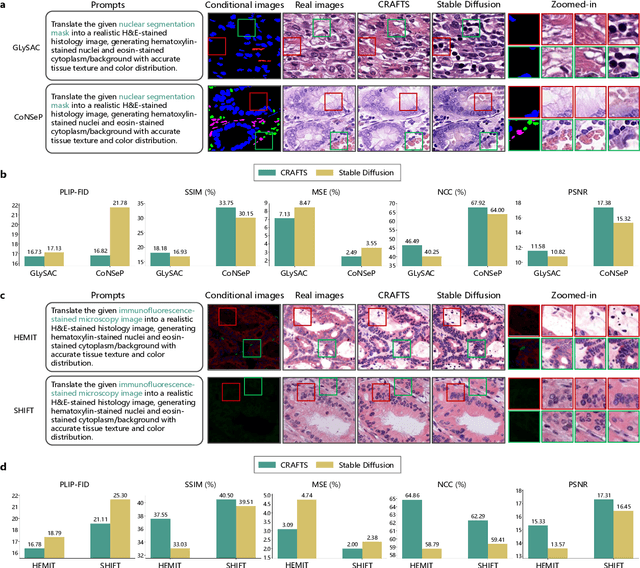
The development of clinical-grade artificial intelligence in pathology is limited by the scarcity of diverse, high-quality annotated datasets. Generative models offer a potential solution but suffer from semantic instability and morphological hallucinations that compromise diagnostic reliability. To address this challenge, we introduce a Correlation-Regulated Alignment Framework for Tissue Synthesis (CRAFTS), the first generative foundation model for pathology-specific text-to-image synthesis. By leveraging a dual-stage training strategy on approximately 2.8 million image-caption pairs, CRAFTS incorporates a novel alignment mechanism that suppresses semantic drift to ensure biological accuracy. This model generates diverse pathological images spanning 30 cancer types, with quality rigorously validated by objective metrics and pathologist evaluations. Furthermore, CRAFTS-augmented datasets enhance the performance across various clinical tasks, including classification, cross-modal retrieval, self-supervised learning, and visual question answering. In addition, coupling CRAFTS with ControlNet enables precise control over tissue architecture from inputs such as nuclear segmentation masks and fluorescence images. By overcoming the critical barriers of data scarcity and privacy concerns, CRAFTS provides a limitless source of diverse, annotated histology data, effectively unlocking the creation of robust diagnostic tools for rare and complex cancer phenotypes.
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025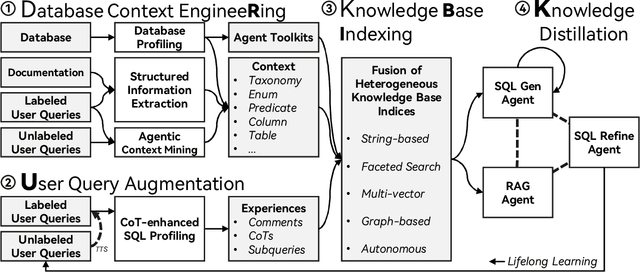
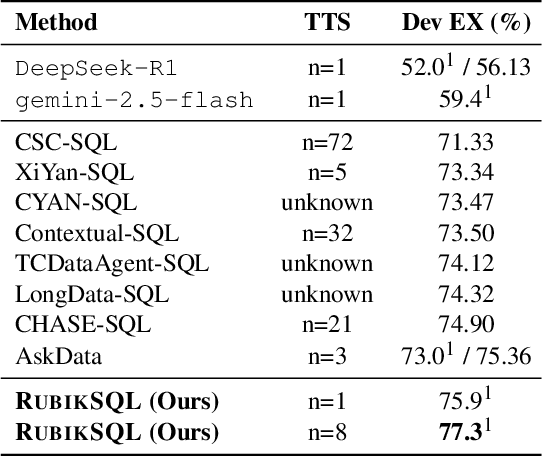
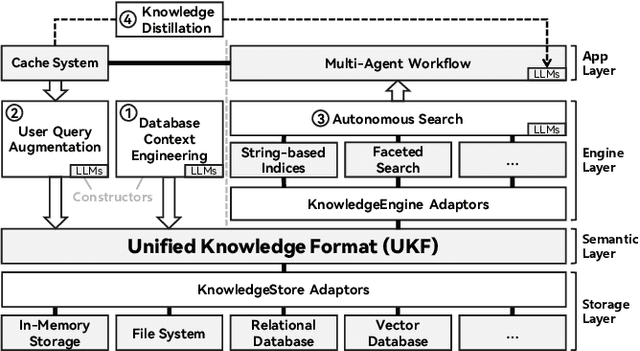
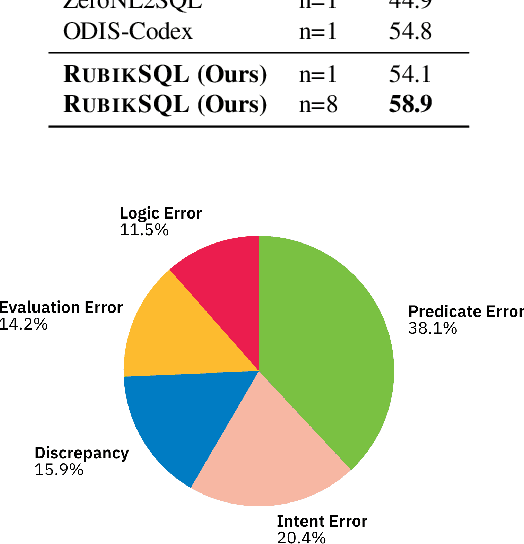
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
The Four Color Theorem for Cell Instance Segmentation
Jun 11, 2025Cell instance segmentation is critical to analyzing biomedical images, yet accurately distinguishing tightly touching cells remains a persistent challenge. Existing instance segmentation frameworks, including detection-based, contour-based, and distance mapping-based approaches, have made significant progress, but balancing model performance with computational efficiency remains an open problem. In this paper, we propose a novel cell instance segmentation method inspired by the four-color theorem. By conceptualizing cells as countries and tissues as oceans, we introduce a four-color encoding scheme that ensures adjacent instances receive distinct labels. This reformulation transforms instance segmentation into a constrained semantic segmentation problem with only four predicted classes, substantially simplifying the instance differentiation process. To solve the training instability caused by the non-uniqueness of four-color encoding, we design an asymptotic training strategy and encoding transformation method. Extensive experiments on various modes demonstrate our approach achieves state-of-the-art performance. The code is available at https://github.com/zhangye-zoe/FCIS.
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
Robust Cross-View Geo-Localization via Content-Viewpoint Disentanglement
May 17, 2025Cross-view geo-localization (CVGL) aims to match images of the same geographic location captured from different perspectives, such as drones and satellites. Despite recent advances, CVGL remains highly challenging due to significant appearance changes and spatial distortions caused by viewpoint variations. Existing methods typically assume that cross-view images can be directly aligned within a shared feature space by maximizing feature similarity through contrastive learning. Nonetheless, this assumption overlooks the inherent conflicts induced by viewpoint discrepancies, resulting in extracted features containing inconsistent information that hinders precise localization. In this study, we take a manifold learning perspective and model the feature space of cross-view images as a composite manifold jointly governed by content and viewpoint information. Building upon this insight, we propose $\textbf{CVD}$, a new CVGL framework that explicitly disentangles $\textit{content}$ and $\textit{viewpoint}$ factors. To promote effective disentanglement, we introduce two constraints: $\textit{(i)}$ An intra-view independence constraint, which encourages statistical independence between the two factors by minimizing their mutual information. $\textit{(ii)}$ An inter-view reconstruction constraint that reconstructs each view by cross-combining $\textit{content}$ and $\textit{viewpoint}$ from paired images, ensuring factor-specific semantics are preserved. As a plug-and-play module, CVD can be seamlessly integrated into existing geo-localization pipelines. Extensive experiments on four benchmarks, i.e., University-1652, SUES-200, CVUSA, and CVACT, demonstrate that CVD consistently improves both localization accuracy and generalization across multiple baselines.
SonicSieve: Bringing Directional Speech Extraction to Smartphones Using Acoustic Microstructures
Apr 15, 2025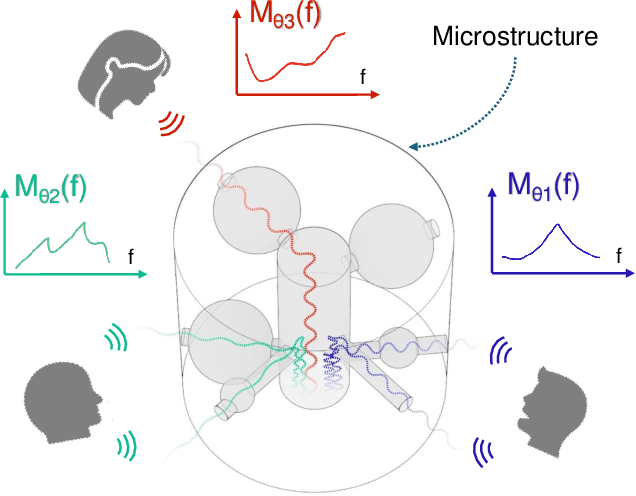
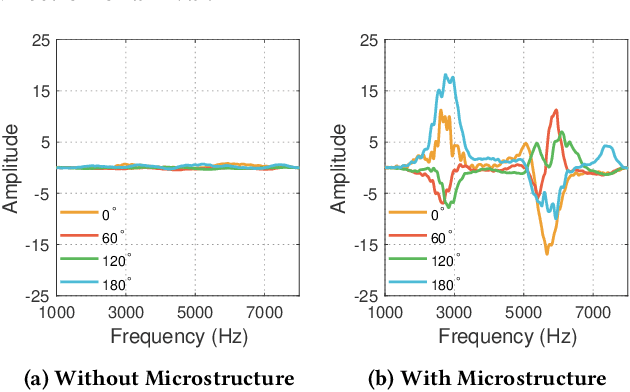
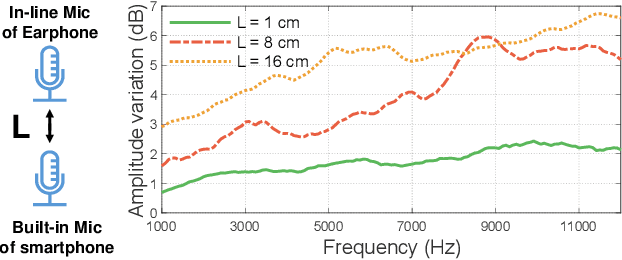
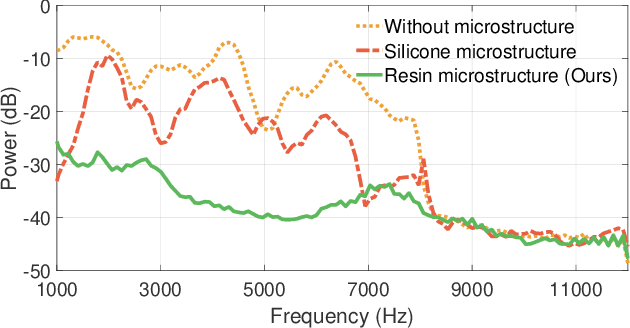
Imagine placing your smartphone on a table in a noisy restaurant and clearly capturing the voices of friends seated around you, or recording a lecturer's voice with clarity in a reverberant auditorium. We introduce SonicSieve, the first intelligent directional speech extraction system for smartphones using a bio-inspired acoustic microstructure. Our passive design embeds directional cues onto incoming speech without any additional electronics. It attaches to the in-line mic of low-cost wired earphones which can be attached to smartphones. We present an end-to-end neural network that processes the raw audio mixtures in real-time on mobile devices. Our results show that SonicSieve achieves a signal quality improvement of 5.0 dB when focusing on a 30{\deg} angular region. Additionally, the performance of our system based on only two microphones exceeds that of conventional 5-microphone arrays.