 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Abstract and Reasoning Abilities Through A Theoretical Perspective
May 28, 2025



In this paper, we aim to establish a simple, effective, and theoretically grounded benchmark for rigorously probing abstract reasoning in Large Language Models (LLMs). To achieve this, we first develop a mathematic framework that defines abstract reasoning as the ability to: (i) extract essential patterns independent of surface representations, and (ii) apply consistent rules to these abstract patterns. Based on this framework, we introduce two novel complementary metrics: \(\scoreGamma\) measures basic reasoning accuracy, while \(\scoreDelta\) quantifies a model's reliance on specific symbols rather than underlying patterns - a key indicator of true abstraction versus mere memorization. To implement this measurement, we design a benchmark: systematic symbol remapping in rule-based tasks, which forces models to demonstrate genuine pattern recognition beyond superficial token matching. Extensive LLM evaluations using this benchmark (commercial API models, 7B-70B, multi-agent) reveal:1) critical limitations in non-decimal arithmetic and symbolic reasoning; 2) persistent abstraction gaps despite chain-of-thought prompting; and 3) \(\scoreDelta\)'s effectiveness in robustly measuring memory dependence by quantifying performance degradation under symbol remapping, particularly highlighting operand-specific memorization. These findings underscore that current LLMs, despite domain-specific strengths, still lack robust abstract reasoning, highlighting key areas for future improvement.
Multi-modal Fusion based Q-distribution Prediction for Controlled Nuclear Fusion
Oct 11, 2024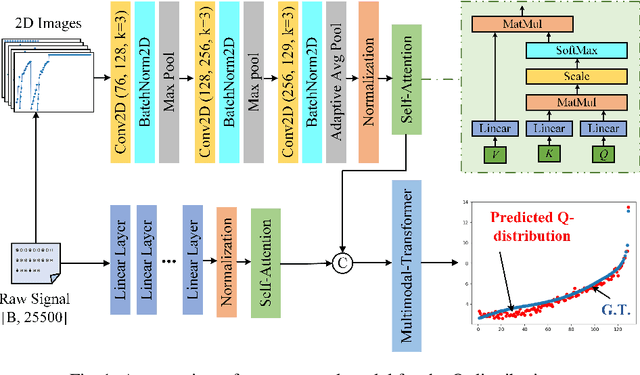


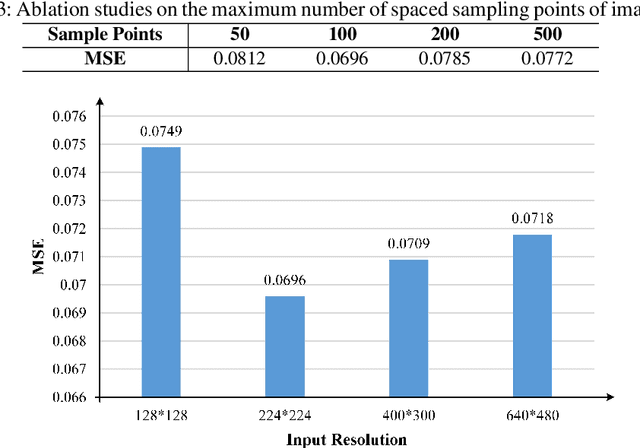
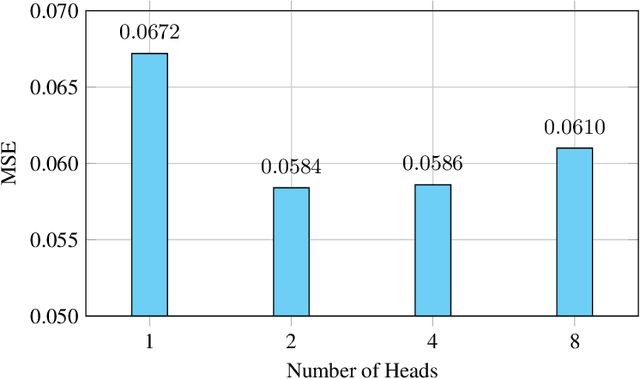
Q-distribution prediction is a crucial research direction in controlled nuclear fusion, with deep learning emerging as a key approach to solving prediction challenges. In this paper, we leverage deep learning techniques to tackle the complexities of Q-distribution prediction. Specifically, we explore multimodal fusion methods in computer vision, integrating 2D line image data with the original 1D data to form a bimodal input. Additionally, we employ the Transformer's attention mechanism for feature extraction and the interactive fusion of bimodal information. Extensive experiments validate the effectiveness of our approach, significantly reducing prediction errors in Q-distribution.
Exploiting Memory-aware Q-distribution Prediction for Nuclear Fusion via Modern Hopfield Network
Oct 11, 2024


This study addresses the critical challenge of predicting the Q-distribution in long-term stable nuclear fusion task, a key component for advancing clean energy solutions. We introduce an innovative deep learning framework that employs Modern Hopfield Networks to incorporate associative memory from historical shots. Utilizing a newly compiled dataset, we demonstrate the effectiveness of our approach in enhancing Q-distribution prediction. The proposed method represents a significant advancement by leveraging historical memory information for the first time in this context, showcasing improved prediction accuracy and contributing to the optimization of nuclear fusion research.
CXPMRG-Bench: Pre-training and Benchmarking for X-ray Medical Report Generation on CheXpert Plus Dataset
Oct 01, 2024
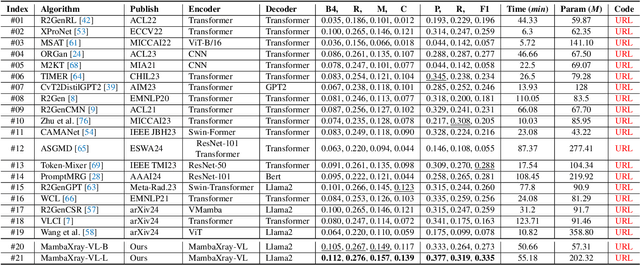
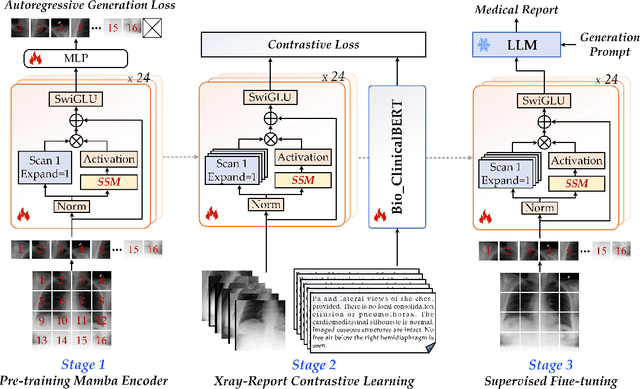
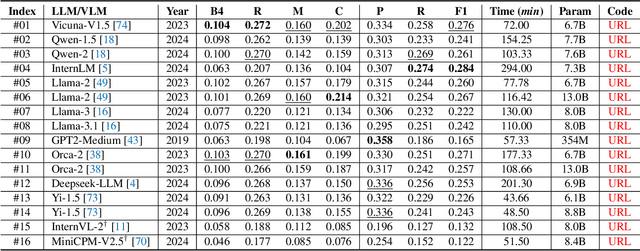
X-ray image-based medical report generation (MRG) is a pivotal area in artificial intelligence which can significantly reduce diagnostic burdens and patient wait times. Despite significant progress, we believe that the task has reached a bottleneck due to the limited benchmark datasets and the existing large models' insufficient capability enhancements in this specialized domain. Specifically, the recently released CheXpert Plus dataset lacks comparative evaluation algorithms and their results, providing only the dataset itself. This situation makes the training, evaluation, and comparison of subsequent algorithms challenging. Thus, we conduct a comprehensive benchmarking of existing mainstream X-ray report generation models and large language models (LLMs), on the CheXpert Plus dataset. We believe that the proposed benchmark can provide a solid comparative basis for subsequent algorithms and serve as a guide for researchers to quickly grasp the state-of-the-art models in this field. More importantly, we propose a large model for the X-ray image report generation using a multi-stage pre-training strategy, including self-supervised autoregressive generation and Xray-report contrastive learning, and supervised fine-tuning. Extensive experimental results indicate that the autoregressive pre-training based on Mamba effectively encodes X-ray images, and the image-text contrastive pre-training further aligns the feature spaces, achieving better experimental results. Source code can be found on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
An Empirical Study of Mamba-based Pedestrian Attribute Recognition
Jul 15, 2024



Current strong pedestrian attribute recognition models are developed based on Transformer networks, which are computationally heavy. Recently proposed models with linear complexity (e.g., Mamba) have garnered significant attention and have achieved a good balance between accuracy and computational cost across a variety of visual tasks. Relevant review articles also suggest that while these models can perform well on some pedestrian attribute recognition datasets, they are generally weaker than the corresponding Transformer models. To further tap into the potential of the novel Mamba architecture for PAR tasks, this paper designs and adapts Mamba into two typical PAR frameworks, i.e., the text-image fusion approach and pure vision Mamba multi-label recognition framework. It is found that interacting with attribute tags as additional input does not always lead to an improvement, specifically, Vim can be enhanced, but VMamba cannot. This paper further designs various hybrid Mamba-Transformer variants and conducts thorough experimental validations. These experimental results indicate that simply enhancing Mamba with a Transformer does not always lead to performance improvements but yields better results under certain settings. We hope this empirical study can further inspire research in Mamba for PAR, and even extend into the domain of multi-label recognition, through the design of these network structures and comprehensive experimentation. The source code of this work will be released at \url{https://github.com/Event-AHU/OpenPAR}