 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Multi-modal Fusion based Q-distribution Prediction for Controlled Nuclear Fusion
Oct 11, 2024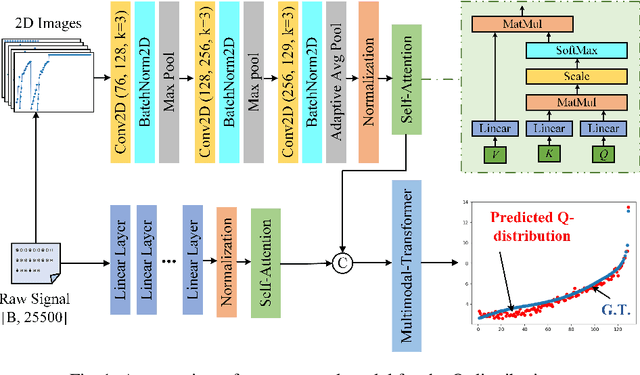


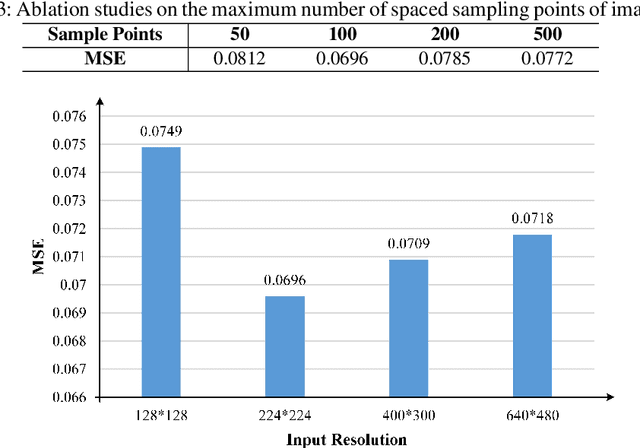
Q-distribution prediction is a crucial research direction in controlled nuclear fusion, with deep learning emerging as a key approach to solving prediction challenges. In this paper, we leverage deep learning techniques to tackle the complexities of Q-distribution prediction. Specifically, we explore multimodal fusion methods in computer vision, integrating 2D line image data with the original 1D data to form a bimodal input. Additionally, we employ the Transformer's attention mechanism for feature extraction and the interactive fusion of bimodal information. Extensive experiments validate the effectiveness of our approach, significantly reducing prediction errors in Q-distribution.
Digger: Detecting Copyright Content Mis-usage in Large Language Model Training
Jan 01, 2024Pre-training, which utilizes extensive and varied datasets, is a critical factor in the success of Large Language Models (LLMs) across numerous applications. However, the detailed makeup of these datasets is often not disclosed, leading to concerns about data security and potential misuse. This is particularly relevant when copyrighted material, still under legal protection, is used inappropriately, either intentionally or unintentionally, infringing on the rights of the authors. In this paper, we introduce a detailed framework designed to detect and assess the presence of content from potentially copyrighted books within the training datasets of LLMs. This framework also provides a confidence estimation for the likelihood of each content sample's inclusion. To validate our approach, we conduct a series of simulated experiments, the results of which affirm the framework's effectiveness in identifying and addressing instances of content misuse in LLM training processes. Furthermore, we investigate the presence of recognizable quotes from famous literary works within these datasets. The outcomes of our study have significant implications for ensuring the ethical use of copyrighted materials in the development of LLMs, highlighting the need for more transparent and responsible data management practices in this field.