 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Ego-Exo-centric Adaptation for Action Anticipation via Multi-Label Prototype Growing and Dual-Clue Consistency
Mar 10, 2026Efficient adaptation between Egocentric (Ego) and Exocentric (Exo) views is crucial for applications such as human-robot cooperation. However, the success of most existing Ego-Exo adaptation methods relies heavily on target-view data for training, thereby increasing computational and data collection costs. In this paper, we make the first exploration of a Test-time Ego-Exo Adaptation for Action Anticipation (TE$^{2}$A$^{3}$) task, which aims to adjust the source-view-trained model online during test time to anticipate target-view actions. It is challenging for existing Test-Time Adaptation (TTA) methods to address this task due to the multi-action candidates and significant temporal-spatial inter-view gap. Hence, we propose a novel Dual-Clue enhanced Prototype Growing Network (DCPGN), which accumulates multi-label knowledge and integrates cross-modality clues for effective test-time Ego-Exo adaptation and action anticipation. Specifically, we propose a Multi-Label Prototype Growing Module (ML-PGM) to balance multiple positive classes via multi-label assignment and confidence-based reweighting for class-wise memory banks, which are updated by an entropy priority queue strategy. Then, the Dual-Clue Consistency Module (DCCM) introduces a lightweight narrator to generate textual clues indicating action progressions, which complement the visual clues containing various objects. Moreover, we constrain the inferred textual and visual logits to construct dual-clue consistency for temporally and spatially bridging Ego and Exo views. Extensive experiments on the newly proposed EgoMe-anti and the existing EgoExoLearn benchmarks show the effectiveness of our method, which outperforms related state-of-the-art methods by a large margin. Code is available at \href{https://github.com/ZhaofengSHI/DCPGN}{https://github.com/ZhaofengSHI/DCPGN}.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
R^2MoE: Redundancy-Removal Mixture of Experts for Lifelong Concept Learning
Jul 17, 2025Enabling large-scale generative models to continuously learn new visual concepts is essential for personalizing pre-trained models to meet individual user preferences. Existing approaches for continual visual concept learning are constrained by two fundamental challenges: catastrophic forgetting and parameter expansion. In this paper, we propose Redundancy-Removal Mixture of Experts (R^2MoE), a parameter-efficient framework for lifelong visual concept learning that effectively learns new concepts while incurring minimal parameter overhead. Our framework includes three key innovative contributions: First, we propose a mixture-of-experts framework with a routing distillation mechanism that enables experts to acquire concept-specific knowledge while preserving the gating network's routing capability, thereby effectively mitigating catastrophic forgetting. Second, we propose a strategy for eliminating redundant layer-wise experts that reduces the number of expert parameters by fully utilizing previously learned experts. Third, we employ a hierarchical local attention-guided inference approach to mitigate interference between generated visual concepts. Extensive experiments have demonstrated that our method generates images with superior conceptual fidelity compared to the state-of-the-art (SOTA) method, achieving an impressive 87.8\% reduction in forgetting rates and 63.3\% fewer parameters on the CustomConcept 101 dataset. Our code is available at {https://github.com/learninginvision/R2MoE}
LoRA-Based Continual Learning with Constraints on Critical Parameter Changes
Apr 18, 2025LoRA-based continual learning represents a promising avenue for leveraging pre-trained models in downstream continual learning tasks. Recent studies have shown that orthogonal LoRA tuning effectively mitigates forgetting. However, this work unveils that under orthogonal LoRA tuning, the critical parameters for pre-tasks still change notably after learning post-tasks. To address this problem, we directly propose freezing the most critical parameter matrices in the Vision Transformer (ViT) for pre-tasks before learning post-tasks. In addition, building on orthogonal LoRA tuning, we propose orthogonal LoRA composition (LoRAC) based on QR decomposition, which may further enhance the plasticity of our method. Elaborate ablation studies and extensive comparisons demonstrate the effectiveness of our proposed method. Our results indicate that our method achieves state-of-the-art (SOTA) performance on several well-known continual learning benchmarks. For instance, on the Split CIFAR-100 dataset, our method shows a 6.35\% improvement in accuracy and a 3.24\% reduction in forgetting compared to previous methods. Our code is available at https://github.com/learninginvision/LoRAC-IPC.
UBER: Uncertainty-Based Evolution with Large Language Models for Automatic Heuristic Design
Dec 30, 2024



NP-hard problem-solving traditionally relies on heuristics, but manually crafting effective heuristics for complex problems remains challenging. While recent work like FunSearch has demonstrated that large language models (LLMs) can be leveraged for heuristic design in evolutionary algorithm (EA) frameworks, their potential is not fully realized due to its deficiency in exploitation and exploration. We present UBER (Uncertainty-Based Evolution for Refinement), a method that enhances LLM+EA methods for automatic heuristic design by integrating uncertainty on top of the FunSearch framework. UBER introduces two key innovations: an Uncertainty-Inclusive Evolution Process (UIEP) for adaptive exploration-exploitation balance, and a principled Uncertainty-Inclusive Island Reset (UIIS) strategy for maintaining population diversity. Through extensive experiments on challenging NP-complete problems, UBER demonstrates significant improvements over FunSearch. Our work provides a new direction for the synergy of LLMs and EA, advancing the field of automatic heuristic design.
Nova: An Iterative Planning and Search Approach to Enhance Novelty and Diversity of LLM Generated Ideas
Oct 18, 2024Scientific innovation is pivotal for humanity, and harnessing large language models (LLMs) to generate research ideas could transform discovery. However, existing LLMs often produce simplistic and repetitive suggestions due to their limited ability in acquiring external knowledge for innovation. To address this problem, we introduce an enhanced planning and search methodology designed to boost the creative potential of LLM-based systems. Our approach involves an iterative process to purposely plan the retrieval of external knowledge, progressively enriching the idea generation with broader and deeper insights. Validation through automated and human assessments indicates that our framework substantially elevates the quality of generated ideas, particularly in novelty and diversity. The number of unique novel ideas produced by our framework is 3.4 times higher than without it. Moreover, our method outperforms the current state-of-the-art, generating at least 2.5 times more top-rated ideas based on 170 seed papers in a Swiss Tournament evaluation.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Quality and Quantity: Unveiling a Million High-Quality Images for Text-to-Image Synthesis in Fashion Design
Nov 29, 2023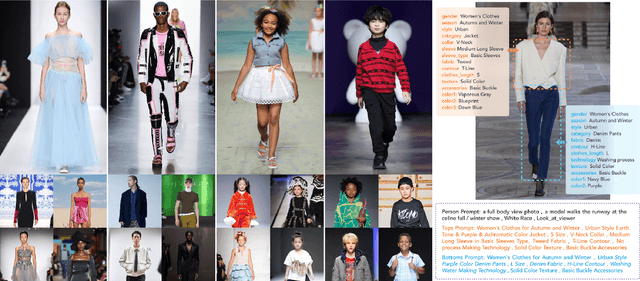

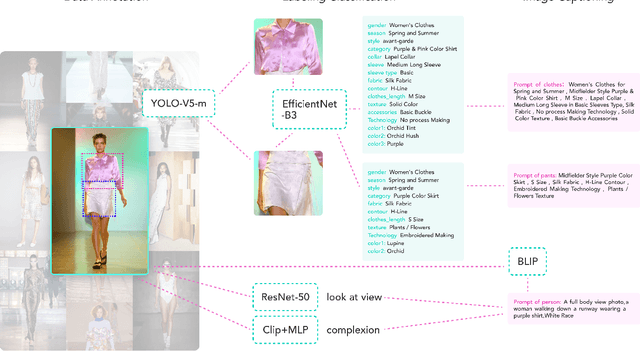

The fusion of AI and fashion design has emerged as a promising research area. However, the lack of extensive, interrelated data on clothing and try-on stages has hindered the full potential of AI in this domain. Addressing this, we present the Fashion-Diffusion dataset, a product of multiple years' rigorous effort. This dataset, the first of its kind, comprises over a million high-quality fashion images, paired with detailed text descriptions. Sourced from a diverse range of geographical locations and cultural backgrounds, the dataset encapsulates global fashion trends. The images have been meticulously annotated with fine-grained attributes related to clothing and humans, simplifying the fashion design process into a Text-to-Image (T2I) task. The Fashion-Diffusion dataset not only provides high-quality text-image pairs and diverse human-garment pairs but also serves as a large-scale resource about humans, thereby facilitating research in T2I generation. Moreover, to foster standardization in the T2I-based fashion design field, we propose a new benchmark comprising multiple datasets for evaluating the performance of fashion design models. This work represents a significant leap forward in the realm of AI-driven fashion design, setting a new standard for future research in this field.
Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting
Oct 12, 2023We propose a novel perspective of viewing large pretrained models as search engines, thereby enabling the repurposing of techniques previously used to enhance search engine performance. As an illustration, we employ a personalized query rewriting technique in the realm of text-to-image generation. Despite significant progress in the field, it is still challenging to create personalized visual representations that align closely with the desires and preferences of individual users. This process requires users to articulate their ideas in words that are both comprehensible to the models and accurately capture their vision, posing difficulties for many users. In this paper, we tackle this challenge by leveraging historical user interactions with the system to enhance user prompts. We propose a novel approach that involves rewriting user prompts based a new large-scale text-to-image dataset with over 300k prompts from 3115 users. Our rewriting model enhances the expressiveness and alignment of user prompts with their intended visual outputs. Experimental results demonstrate the superiority of our methods over baseline approaches, as evidenced in our new offline evaluation method and online tests. Our approach opens up exciting possibilities of applying more search engine techniques to build truly personalized large pretrained models.
Towards Continual Egocentric Activity Recognition: A Multi-modal Egocentric Activity Dataset for Continual Learning
Jan 26, 2023


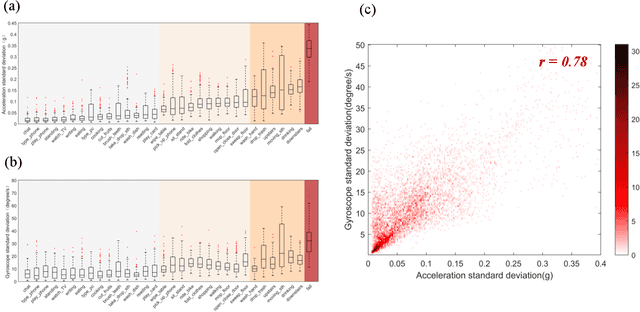
With the rapid development of wearable cameras, a massive collection of egocentric video for first-person visual perception becomes available. Using egocentric videos to predict first-person activity faces many challenges, including limited field of view, occlusions, and unstable motions. Observing that sensor data from wearable devices facilitates human activity recognition, multi-modal activity recognition is attracting increasing attention. However, the deficiency of related dataset hinders the development of multi-modal deep learning for egocentric activity recognition. Nowadays, deep learning in real world has led to a focus on continual learning that often suffers from catastrophic forgetting. But the catastrophic forgetting problem for egocentric activity recognition, especially in the context of multiple modalities, remains unexplored due to unavailability of dataset. In order to assist this research, we present a multi-modal egocentric activity dataset for continual learning named UESTC-MMEA-CL, which is collected by self-developed glasses integrating a first-person camera and wearable sensors. It contains synchronized data of videos, accelerometers, and gyroscopes, for 32 types of daily activities, performed by 10 participants. Its class types and scale are compared with other publicly available datasets. The statistical analysis of the sensor data is given to show the auxiliary effects for different behaviors. And results of egocentric activity recognition are reported when using separately, and jointly, three modalities: RGB, acceleration, and gyroscope, on a base network architecture. To explore the catastrophic forgetting in continual learning tasks, four baseline methods are extensively evaluated with different multi-modal combinations. We hope the UESTC-MMEA-CL can promote future studies on continual learning for first-person activity recognition in wearable applications.