 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Impact of Multi-Modal Interactions on User Engagement: A Comprehensive Evaluation in AI-driven Conversations
Jun 21, 2024Large Language Models (LLMs) have significantly advanced user-bot interactions, enabling more complex and coherent dialogues. However, the prevalent text-only modality might not fully exploit the potential for effective user engagement. This paper explores the impact of multi-modal interactions, which incorporate images and audio alongside text, on user engagement in chatbot conversations. We conduct a comprehensive analysis using a diverse set of chatbots and real-user interaction data, employing metrics such as retention rate and conversation length to evaluate user engagement. Our findings reveal a significant enhancement in user engagement with multi-modal interactions compared to text-only dialogues. Notably, the incorporation of a third modality significantly amplifies engagement beyond the benefits observed with just two modalities. These results suggest that multi-modal interactions optimize cognitive processing and facilitate richer information comprehension. This study underscores the importance of multi-modality in chatbot design, offering valuable insights for creating more engaging and immersive AI communication experiences and informing the broader AI community about the benefits of multi-modal interactions in enhancing user engagement.
Quality and Quantity: Unveiling a Million High-Quality Images for Text-to-Image Synthesis in Fashion Design
Nov 29, 2023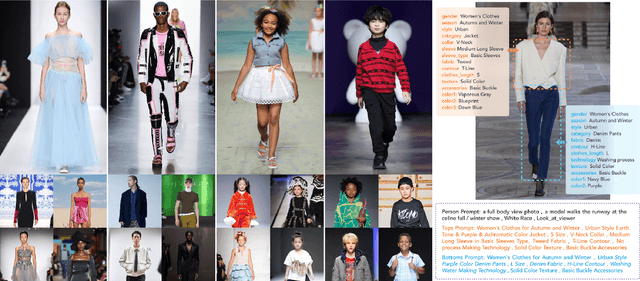

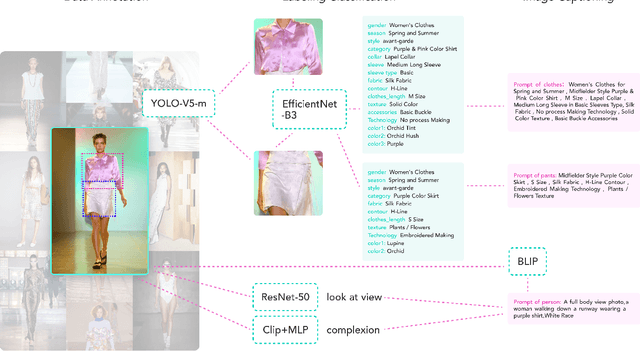

The fusion of AI and fashion design has emerged as a promising research area. However, the lack of extensive, interrelated data on clothing and try-on stages has hindered the full potential of AI in this domain. Addressing this, we present the Fashion-Diffusion dataset, a product of multiple years' rigorous effort. This dataset, the first of its kind, comprises over a million high-quality fashion images, paired with detailed text descriptions. Sourced from a diverse range of geographical locations and cultural backgrounds, the dataset encapsulates global fashion trends. The images have been meticulously annotated with fine-grained attributes related to clothing and humans, simplifying the fashion design process into a Text-to-Image (T2I) task. The Fashion-Diffusion dataset not only provides high-quality text-image pairs and diverse human-garment pairs but also serves as a large-scale resource about humans, thereby facilitating research in T2I generation. Moreover, to foster standardization in the T2I-based fashion design field, we propose a new benchmark comprising multiple datasets for evaluating the performance of fashion design models. This work represents a significant leap forward in the realm of AI-driven fashion design, setting a new standard for future research in this field.