 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVA-X: Ego-to-Exo Imitation Error Detection via Scene-Adaptive View Alignment and Bidirectional Cross View Fusion
Mar 13, 2026Error detection is crucial in industrial training, healthcare, and assembly quality control. Most existing work assumes a single-view setting and cannot handle the practical case where a third-person (exo) demonstration is used to assess a first-person (ego) imitation. We formalize Ego$\rightarrow$Exo Imitation Error Detection: given asynchronous, length-mismatched ego and exo videos, the model must localize procedural steps on the ego timeline and decide whether each is erroneous. This setting introduces cross-view domain shift, temporal misalignment, and heavy redundancy. Under a unified protocol, we adapt strong baselines from dense video captioning and temporal action detection and show that they struggle in this cross-view regime. We then propose SAVA-X, an Align-Fuse-Detect framework with (i) view-conditioned adaptive sampling, (ii) scene-adaptive view embeddings, and (iii) bidirectional cross-attention fusion. On the EgoMe benchmark, SAVA-X consistently improves AUPRC and mean tIoU over all baselines, and ablations confirm the complementary benefits of its components. Code is available at https://github.com/jack1ee/SAVAX.
Continual Learning with Vision-Language Models via Semantic-Geometry Preservation
Mar 12, 2026Continual learning of pretrained vision-language models (VLMs) is prone to catastrophic forgetting, yet current approaches adapt to new tasks without explicitly preserving the cross-modal semantic geometry inherited from pretraining and previous stages, allowing new-task supervision to induce geometric distortion. We observe that the most pronounced drift tends to concentrate in vulnerable neighborhoods near the old-new semantic interface, where shared visual patterns are easily re-explained by new textual semantics. To address this under an exemplar-free constraint, we propose Semantic Geometry Preservation for Continual Learning (SeGP-CL). SeGP-CL first probes the drift-prone region by constructing a compact set of adversarial anchors with dual-targeted projected gradient descent (DPGD), which drives selected new-task seeds toward old-class semantics while remaining faithful in raw visual space. During training, we preserve cross-modal structure by anchor-guided cross-modal geometry distillation (ACGD), and stabilize the textual reference frame across tasks via a lightweight text semantic-geometry regularization (TSGR). After training, we estimate anchor-induced raw-space drift to transfer old visual prototypes and perform dual-path inference by fusing cross-modal and visual cues. Extensive experiments on five continual learning benchmarks demonstrate that SeGP-CL consistently improves stability and forward transfer, achieving state-of-the-art performance while better preserving semantic geometry of VLMs.
Closing the Oracle Gap: Increment Vector Transformation for Class Incremental Learning
Sep 26, 2025Class Incremental Learning (CIL) aims to sequentially acquire knowledge of new classes without forgetting previously learned ones. Despite recent progress, current CIL methods still exhibit significant performance gaps compared to their oracle counterparts-models trained with full access to historical data. Inspired by recent insights on Linear Mode Connectivity (LMC), we revisit the geometric properties of oracle solutions in CIL and uncover a fundamental observation: these oracle solutions typically maintain low-loss linear connections to the optimum of previous tasks. Motivated by this finding, we propose Increment Vector Transformation (IVT), a novel plug-and-play framework designed to mitigate catastrophic forgetting during training. Rather than directly following CIL updates, IVT periodically teleports the model parameters to transformed solutions that preserve linear connectivity to previous task optimum. By maintaining low-loss along these connecting paths, IVT effectively ensures stable performance on previously learned tasks. The transformation is efficiently approximated using diagonal Fisher Information Matrices, making IVT suitable for both exemplar-free and exemplar-based scenarios, and compatible with various initialization strategies. Extensive experiments on CIFAR-100, FGVCAircraft, ImageNet-Subset, and ImageNet-Full demonstrate that IVT consistently enhances the performance of strong CIL baselines. Specifically, on CIFAR-100, IVT improves the last accuracy of the PASS baseline by +5.12% and reduces forgetting by 2.54%. For the CLIP-pre-trained SLCA baseline on FGVCAircraft, IVT yields gains of +14.93% in average accuracy and +21.95% in last accuracy. The code will be released.
MINGLE: Mixtures of Null-Space Gated Low-Rank Experts for Test-Time Continual Model Merging
May 17, 2025Continual model merging integrates independently fine-tuned models sequentially without access to original training data, providing a scalable and efficient solution to continual learning. However, current methods still face critical challenges, notably parameter interference among tasks and limited adaptability to evolving test distributions. The former causes catastrophic forgetting of integrated tasks, while the latter hinders effective adaptation to new tasks. To address these, we propose MINGLE, a novel framework for test-time continual model merging, which leverages test-time adaptation using a small set of unlabeled test samples from the current task to dynamically guide the merging process. MINGLE employs a mixture-of-experts architecture composed of parameter-efficient, low-rank experts, enabling efficient adaptation and improving robustness to distribution shifts. To mitigate catastrophic forgetting, we propose Null-Space Constrained Gating, which restricts gating updates to subspaces orthogonal to prior task representations. This suppresses activations on old task inputs and preserves model behavior on past tasks. To further balance stability and adaptability, we design an Adaptive Relaxation Strategy, which dynamically adjusts the constraint strength based on interference signals captured during test-time adaptation. Extensive experiments on standard continual merging benchmarks demonstrate that MINGLE achieves robust generalization, reduces forgetting significantly, and consistently surpasses previous state-of-the-art methods by 7-9\% on average across diverse task orders.
CMaP-SAM: Contraction Mapping Prior for SAM-driven Few-shot Segmentation
Apr 07, 2025



Few-shot segmentation (FSS) aims to segment new classes using few annotated images. While recent FSS methods have shown considerable improvements by leveraging Segment Anything Model (SAM), they face two critical limitations: insufficient utilization of structural correlations in query images, and significant information loss when converting continuous position priors to discrete point prompts. To address these challenges, we propose CMaP-SAM, a novel framework that introduces contraction mapping theory to optimize position priors for SAM-driven few-shot segmentation. CMaP-SAM consists of three key components: (1) a contraction mapping module that formulates position prior optimization as a Banach contraction mapping with convergence guarantees. This module iteratively refines position priors through pixel-wise structural similarity, generating a converged prior that preserves both semantic guidance from reference images and structural correlations in query images; (2) an adaptive distribution alignment module bridging continuous priors with SAM's binary mask prompt encoder; and (3) a foreground-background decoupled refinement architecture producing accurate final segmentation masks. Extensive experiments demonstrate CMaP-SAM's effectiveness, achieving state-of-the-art performance with 71.1 mIoU on PASCAL-$5^i$ and 56.1 on COCO-$20^i$ datasets.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Few-Shot Continual Learning for Activity Recognition in Classroom Surveillance Images
Sep 05, 2024
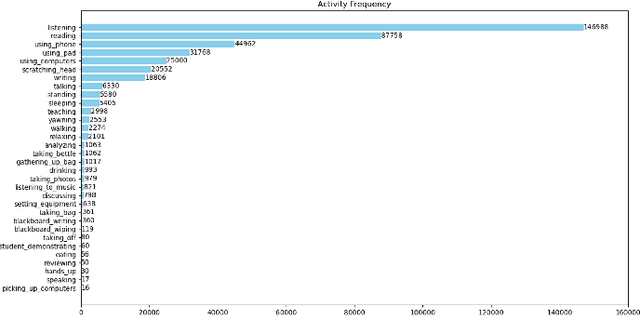
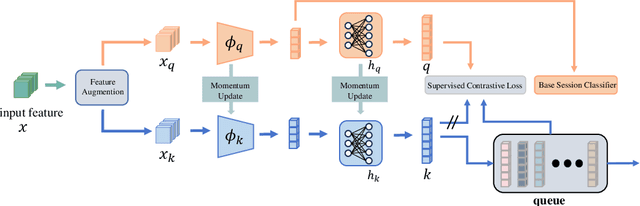
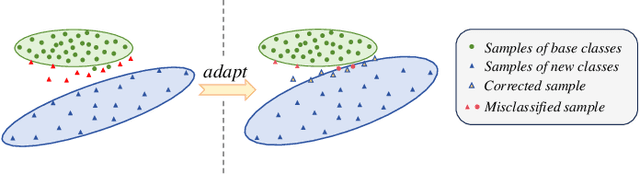
The application of activity recognition in the "AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. In real classroom settings, normal teaching activities such as reading, account for a large proportion of samples, while rare non-teaching activities such as eating, continue to appear. This requires a model that can learn non-teaching activities from few samples without forgetting the normal teaching activities, which necessitates fewshot continual learning (FSCL) capability. To address this gap, we constructed a continual learning dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition in Classroom). The dataset has advantages such as multiple perspectives, a wide variety of activities, and real-world scenarios, but it also presents challenges like similar activities and imbalanced sample distribution. To overcome these challenges, we designed a few-shot continual learning method that combines supervised contrastive learning (SCL) and an adaptive covariance classifier (ACC). During the base phase, we proposed a SCL approach based on feature augmentation to enhance the model's generalization ability. In the incremental phase, we employed an ACC to more accurately describe the distribution of new classes. Experimental results demonstrate that our method outperforms other existing methods on the ARIC dataset.
Distribution-Level Memory Recall for Continual Learning: Preserving Knowledge and Avoiding Confusion
Aug 04, 2024



Continual Learning (CL) aims to enable Deep Neural Networks (DNNs) to learn new data without forgetting previously learned knowledge. The key to achieving this goal is to avoid confusion at the feature level, i.e., avoiding confusion within old tasks and between new and old tasks. Previous prototype-based CL methods generate pseudo features for old knowledge replay by adding Gaussian noise to the centroids of old classes. However, the distribution in the feature space exhibits anisotropy during the incremental process, which prevents the pseudo features from faithfully reproducing the distribution of old knowledge in the feature space, leading to confusion in classification boundaries within old tasks. To address this issue, we propose the Distribution-Level Memory Recall (DMR) method, which uses a Gaussian mixture model to precisely fit the feature distribution of old knowledge at the distribution level and generate pseudo features in the next stage. Furthermore, resistance to confusion at the distribution level is also crucial for multimodal learning, as the problem of multimodal imbalance results in significant differences in feature responses between different modalities, exacerbating confusion within old tasks in prototype-based CL methods. Therefore, we mitigate the multi-modal imbalance problem by using the Inter-modal Guidance and Intra-modal Mining (IGIM) method to guide weaker modalities with prior information from dominant modalities and further explore useful information within modalities. For the second key, We propose the Confusion Index to quantitatively describe a model's ability to distinguish between new and old tasks, and we use the Incremental Mixup Feature Enhancement (IMFE) method to enhance pseudo features with new sample features, alleviating classification confusion between new and old knowledge.
No Re-Train, More Gain: Upgrading Backbones with Diffusion Model for Few-Shot Segmentation
Jul 23, 2024



Few-Shot Segmentation (FSS) aims to segment novel classes using only a few annotated images. Despite considerable process under pixel-wise support annotation, current FSS methods still face three issues: the inflexibility of backbone upgrade without re-training, the inability to uniformly handle various types of annotations (e.g., scribble, bounding box, mask and text), and the difficulty in accommodating different annotation quantity. To address these issues simultaneously, we propose DiffUp, a novel FSS method that conceptualizes the FSS task as a conditional generative problem using a diffusion process. For the first issue, we introduce a backbone-agnostic feature transformation module that converts different segmentation cues into unified coarse priors, facilitating seamless backbone upgrade without re-training. For the second issue, due to the varying granularity of transformed priors from diverse annotation types, we conceptualize these multi-granular transformed priors as analogous to noisy intermediates at different steps of a diffusion model. This is implemented via a self-conditioned modulation block coupled with a dual-level quality modulation branch. For the third issue, we incorporates an uncertainty-aware information fusion module that harmonizing the variability across zero-shot, one-shot and many-shot scenarios. Evaluated through rigorous benchmarks, DiffUp significantly outperforms existing FSS models in terms of flexibility and accuracy.
Learning with Noisy Low-Cost MOS for Image Quality Assessment via Dual-Bias Calibration
Nov 27, 2023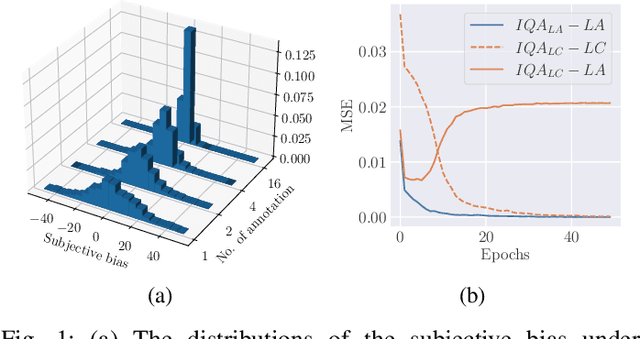
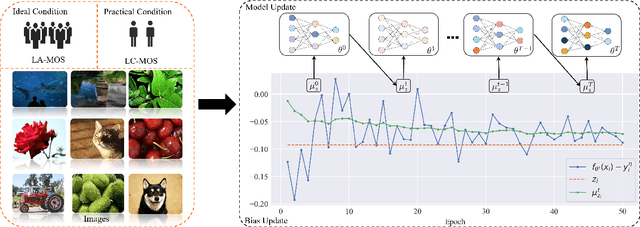
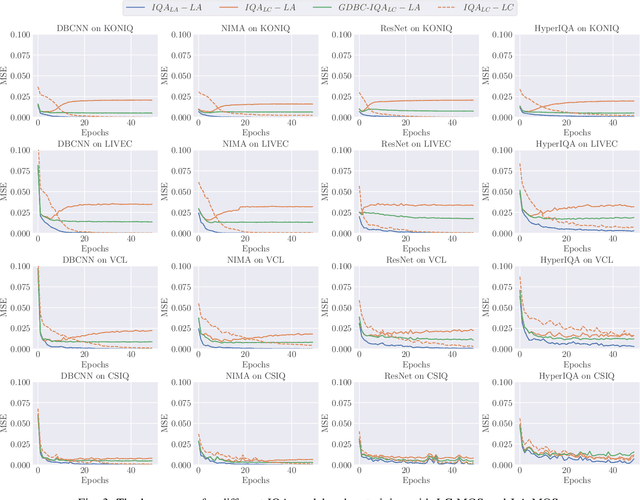
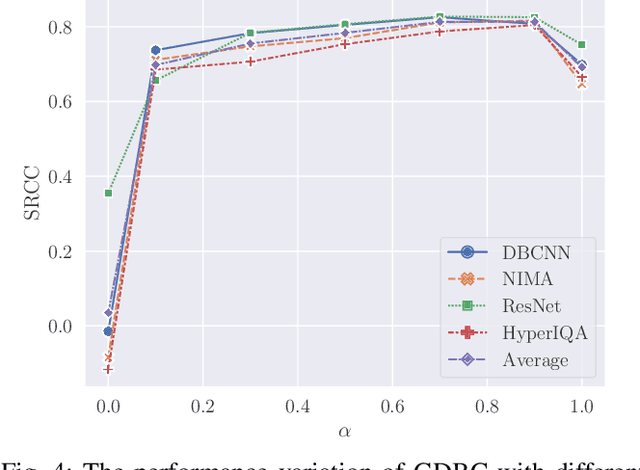
Learning based image quality assessment (IQA) models have obtained impressive performance with the help of reliable subjective quality labels, where mean opinion score (MOS) is the most popular choice. However, in view of the subjective bias of individual annotators, the labor-abundant MOS (LA-MOS) typically requires a large collection of opinion scores from multiple annotators for each image, which significantly increases the learning cost. In this paper, we aim to learn robust IQA models from low-cost MOS (LC-MOS), which only requires very few opinion scores or even a single opinion score for each image. More specifically, we consider the LC-MOS as the noisy observation of LA-MOS and enforce the IQA model learned from LC-MOS to approach the unbiased estimation of LA-MOS. In this way, we represent the subjective bias between LC-MOS and LA-MOS, and the model bias between IQA predictions learned from LC-MOS and LA-MOS (i.e., dual-bias) as two latent variables with unknown parameters. By means of the expectation-maximization based alternating optimization, we can jointly estimate the parameters of the dual-bias, which suppresses the misleading of LC-MOS via a gated dual-bias calibration (GDBC) module. To the best of our knowledge, this is the first exploration of robust IQA model learning from noisy low-cost labels. Theoretical analysis and extensive experiments on four popular IQA datasets show that the proposed method is robust toward different bias rates and annotation numbers and significantly outperforms the other learning based IQA models when only LC-MOS is available. Furthermore, we also achieve comparable performance with respect to the other models learned with LA-MOS.