 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adversarial Robustness of Learning-based Image Compression Against Rate-Distortion Attacks
May 13, 2024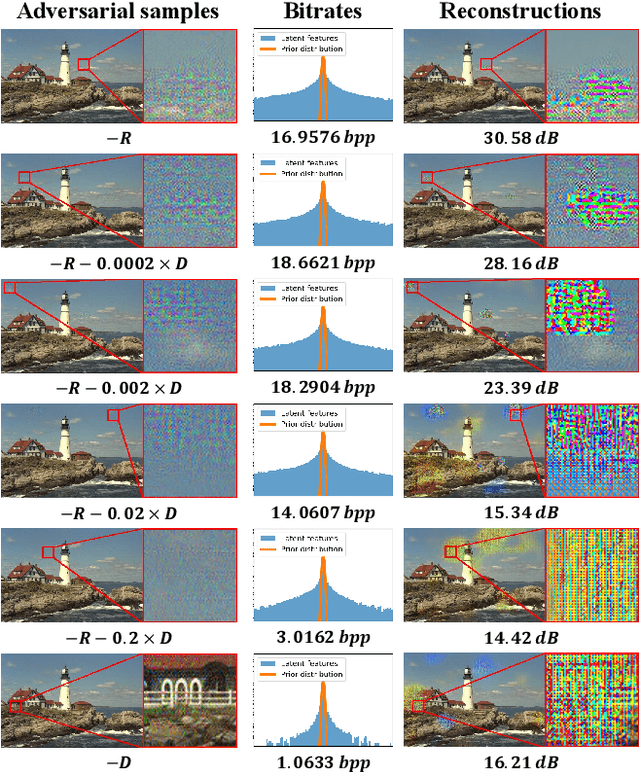
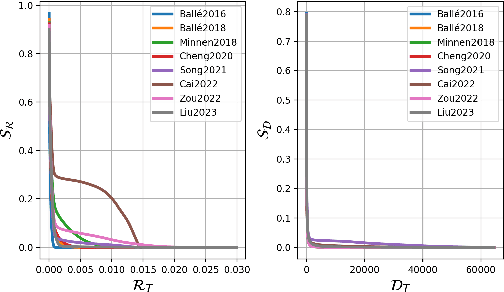


Despite demonstrating superior rate-distortion (RD) performance, learning-based image compression (LIC) algorithms have been found to be vulnerable to malicious perturbations in recent studies. Adversarial samples in these studies are designed to attack only one dimension of either bitrate or distortion, targeting a submodel with a specific compression ratio. However, adversaries in real-world scenarios are neither confined to singular dimensional attacks nor always have control over compression ratios. This variability highlights the inadequacy of existing research in comprehensively assessing the adversarial robustness of LIC algorithms in practical applications. To tackle this issue, this paper presents two joint rate-distortion attack paradigms at both submodel and algorithm levels, i.e., Specific-ratio Rate-Distortion Attack (SRDA) and Agnostic-ratio Rate-Distortion Attack (ARDA). Additionally, a suite of multi-granularity assessment tools is introduced to evaluate the attack results from various perspectives. On this basis, extensive experiments on eight prominent LIC algorithms are conducted to offer a thorough analysis of their inherent vulnerabilities. Furthermore, we explore the efficacy of two defense techniques in improving the performance under joint rate-distortion attacks. The findings from these experiments can provide a valuable reference for the development of compression algorithms with enhanced adversarial robustness.
Learning with Noisy Low-Cost MOS for Image Quality Assessment via Dual-Bias Calibration
Nov 27, 2023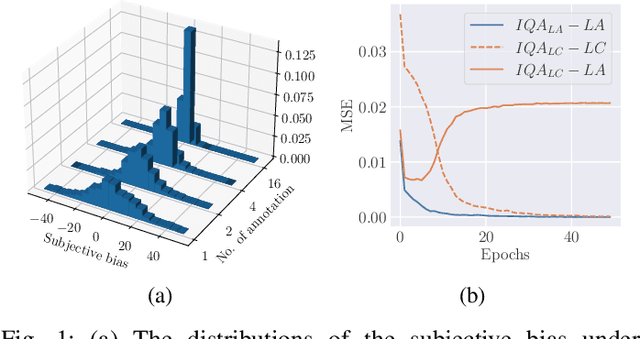
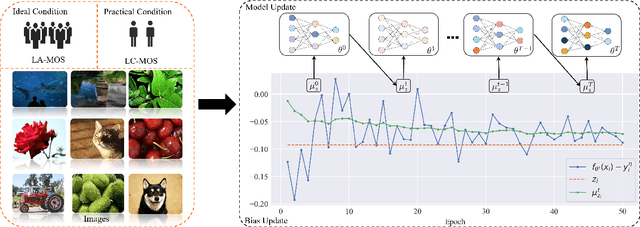
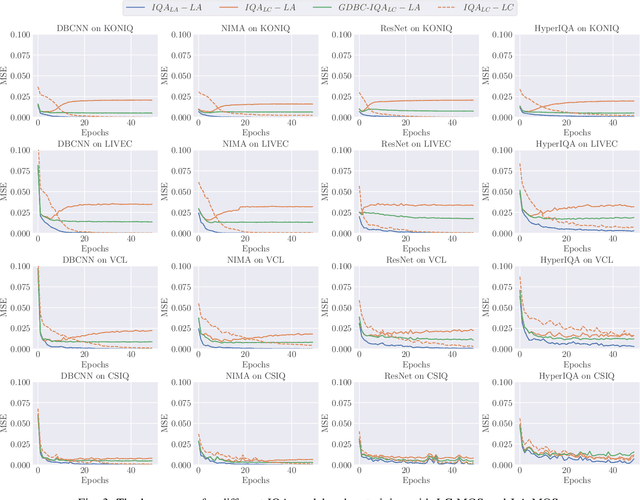
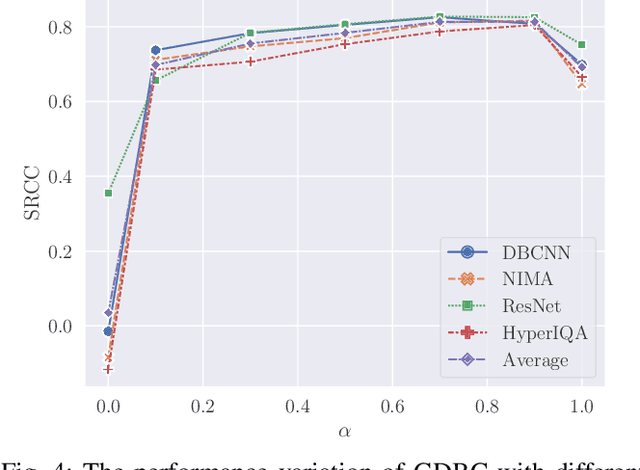
Learning based image quality assessment (IQA) models have obtained impressive performance with the help of reliable subjective quality labels, where mean opinion score (MOS) is the most popular choice. However, in view of the subjective bias of individual annotators, the labor-abundant MOS (LA-MOS) typically requires a large collection of opinion scores from multiple annotators for each image, which significantly increases the learning cost. In this paper, we aim to learn robust IQA models from low-cost MOS (LC-MOS), which only requires very few opinion scores or even a single opinion score for each image. More specifically, we consider the LC-MOS as the noisy observation of LA-MOS and enforce the IQA model learned from LC-MOS to approach the unbiased estimation of LA-MOS. In this way, we represent the subjective bias between LC-MOS and LA-MOS, and the model bias between IQA predictions learned from LC-MOS and LA-MOS (i.e., dual-bias) as two latent variables with unknown parameters. By means of the expectation-maximization based alternating optimization, we can jointly estimate the parameters of the dual-bias, which suppresses the misleading of LC-MOS via a gated dual-bias calibration (GDBC) module. To the best of our knowledge, this is the first exploration of robust IQA model learning from noisy low-cost labels. Theoretical analysis and extensive experiments on four popular IQA datasets show that the proposed method is robust toward different bias rates and annotation numbers and significantly outperforms the other learning based IQA models when only LC-MOS is available. Furthermore, we also achieve comparable performance with respect to the other models learned with LA-MOS.
Non-Homogeneous Haze Removal via Artificial Scene Prior and Bidimensional Graph Reasoning
Apr 05, 2021
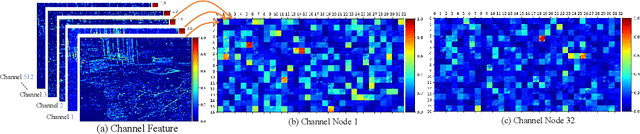
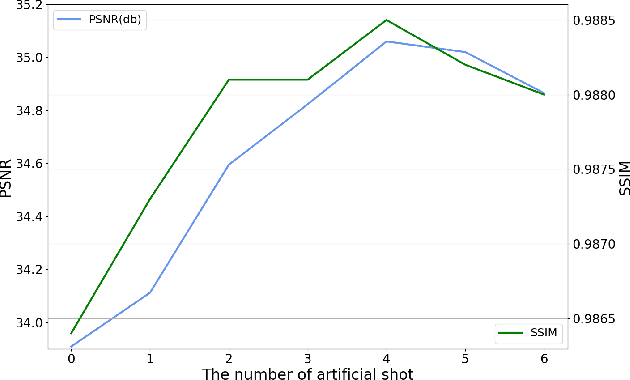
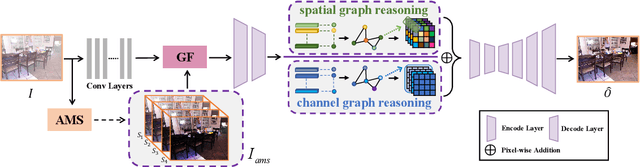
Due to the lack of natural scene and haze prior information, it is greatly challenging to completely remove the haze from single image without distorting its visual content. Fortunately, the real-world haze usually presents non-homogeneous distribution, which provides us with many valuable clues in partial well-preserved regions. In this paper, we propose a Non-Homogeneous Haze Removal Network (NHRN) via artificial scene prior and bidimensional graph reasoning. Firstly, we employ the gamma correction iteratively to simulate artificial multiple shots under different exposure conditions, whose haze degrees are different and enrich the underlying scene prior. Secondly, beyond utilizing the local neighboring relationship, we build a bidimensional graph reasoning module to conduct non-local filtering in the spatial and channel dimensions of feature maps, which models their long-range dependency and propagates the natural scene prior between the well-preserved nodes and the nodes contaminated by haze. We evaluate our method on different benchmark datasets. The results demonstrate that our method achieves superior performance over many state-of-the-art algorithms for both the single image dehazing and hazy image understanding tasks.
BA^2M: A Batch Aware Attention Module for Image Classification
Mar 28, 2021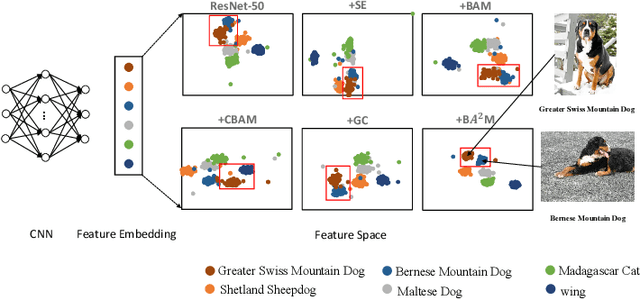
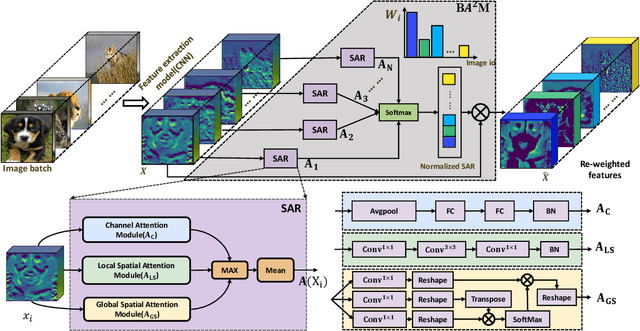
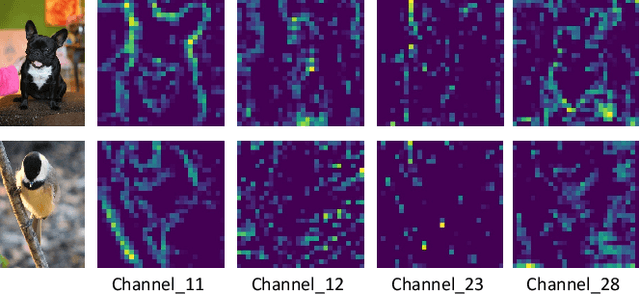
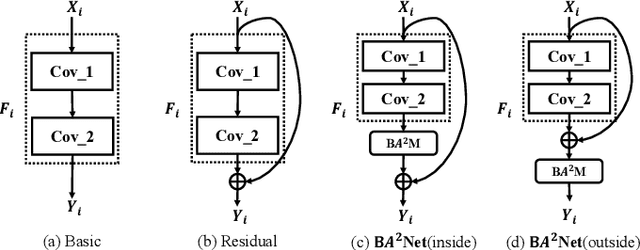
The attention mechanisms have been employed in Convolutional Neural Network (CNN) to enhance the feature representation. However, existing attention mechanisms only concentrate on refining the features inside each sample and neglect the discrimination between different samples. In this paper, we propose a batch aware attention module (BA2M) for feature enrichment from a distinctive perspective. More specifically, we first get the sample-wise attention representation (SAR) by fusing the channel, local spatial and global spatial attention maps within each sample. Then, we feed the SARs of the whole batch to a normalization function to get the weights for each sample. The weights serve to distinguish the features' importance between samples in a training batch with different complexity of content. The BA2M could be embedded into different parts of CNN and optimized with the network in an end-to-end manner. The design of BA2M is lightweight with few extra parameters and calculations. We validate BA2M through extensive experiments on CIFAR-100 and ImageNet-1K for the image recognition task. The results show that BA2M can boost the performance of various network architectures and outperforms many classical attention methods. Besides, BA2M exceeds traditional methods of re-weighting samples based on the loss value.
Advanced Geometry Surface Coding for Dynamic Point Cloud Compression
Mar 11, 2021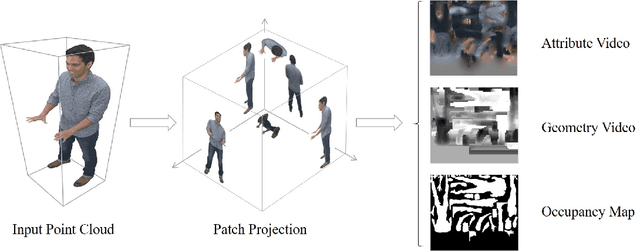
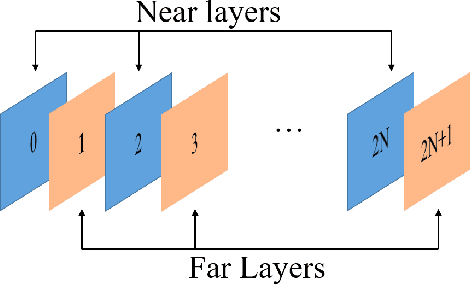
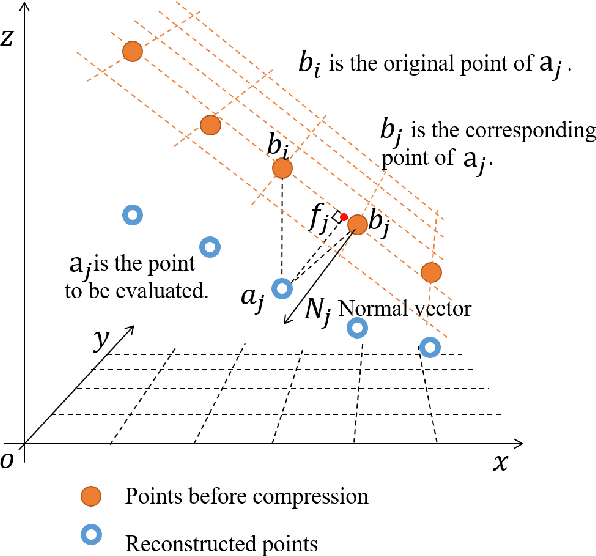
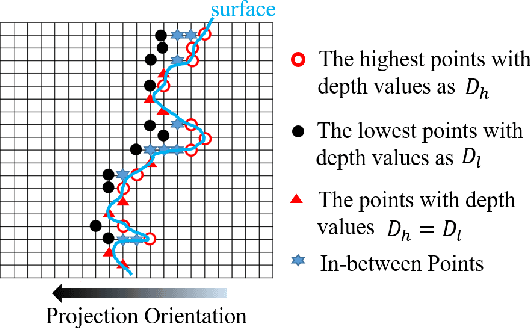
In video-based dynamic point cloud compression (V-PCC), 3D point clouds are projected onto 2D images for compressing with the existing video codecs. However, the existing video codecs are originally designed for natural visual signals, and it fails to account for the characteristics of point clouds. Thus, there are still problems in the compression of geometry information generated from the point clouds. Firstly, the distortion model in the existing rate-distortion optimization (RDO) is not consistent with the geometry quality assessment metrics. Secondly, the prediction methods in video codecs fail to account for the fact that the highest depth values of a far layer is greater than or equal to the corresponding lowest depth values of a near layer. This paper proposes an advanced geometry surface coding (AGSC) method for dynamic point clouds (DPC) compression. The proposed method consists of two modules, including an error projection model-based (EPM-based) RDO and an occupancy map-based (OM-based) merge prediction. Firstly, the EPM model is proposed to describe the relationship between the distortion model in the existing video codec and the geometry quality metric. Secondly, the EPM-based RDO method is presented to project the existing distortion model on the plane normal and is simplified to estimate the average normal vectors of coding units (CUs). Finally, we propose the OM-based merge prediction approach, in which the prediction pixels of merge modes are refined based on the occupancy map. Experiments tested on the standard point clouds show that the proposed method achieves an average 9.84\% bitrate saving for geometry compression.
Visibility Constrained Generative Model for Depth-based 3D Facial Pose Tracking
May 06, 2019
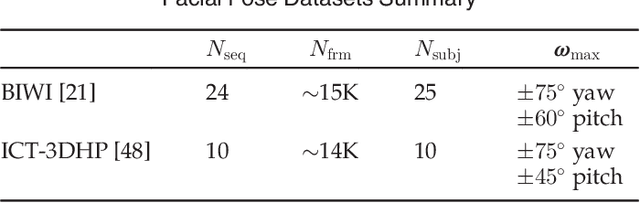
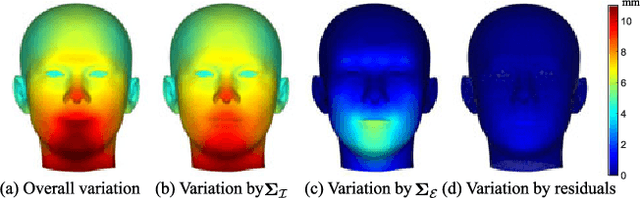

In this paper, we propose a generative framework that unifies depth-based 3D facial pose tracking and face model adaptation on-the-fly, in the unconstrained scenarios with heavy occlusions and arbitrary facial expression variations. Specifically, we introduce a statistical 3D morphable model that flexibly describes the distribution of points on the surface of the face model, with an efficient switchable online adaptation that gradually captures the identity of the tracked subject and rapidly constructs a suitable face model when the subject changes. Moreover, unlike prior art that employed ICP-based facial pose estimation, to improve robustness to occlusions, we propose a ray visibility constraint that regularizes the pose based on the face model's visibility with respect to the input point cloud. Ablation studies and experimental results on Biwi and ICT-3DHP datasets demonstrate that the proposed framework is effective and outperforms completing state-of-the-art depth-based methods.
MVF-Net: Multi-View 3D Face Morphable Model Regression
Apr 09, 2019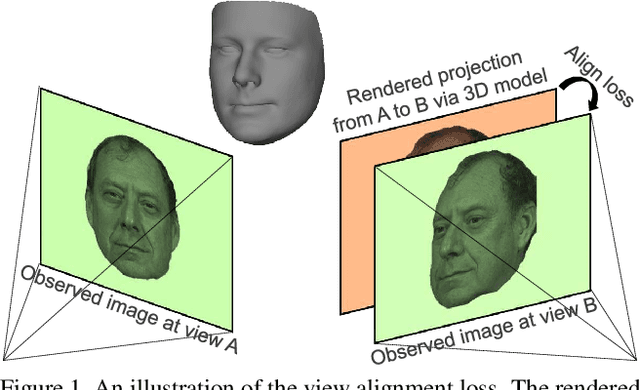
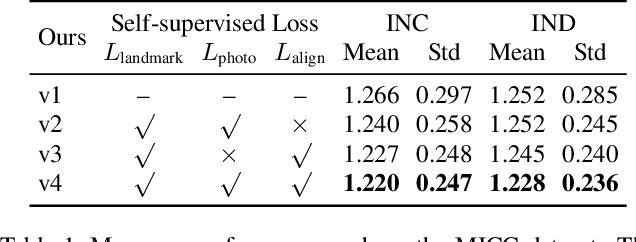
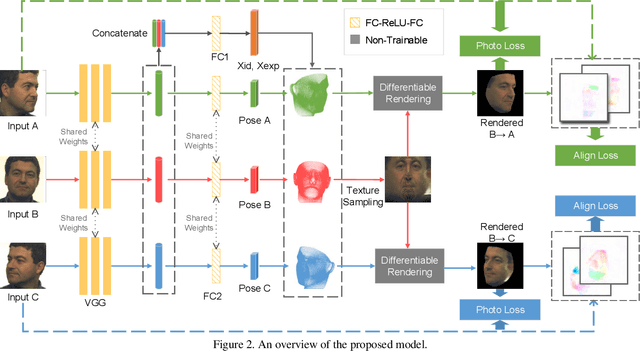
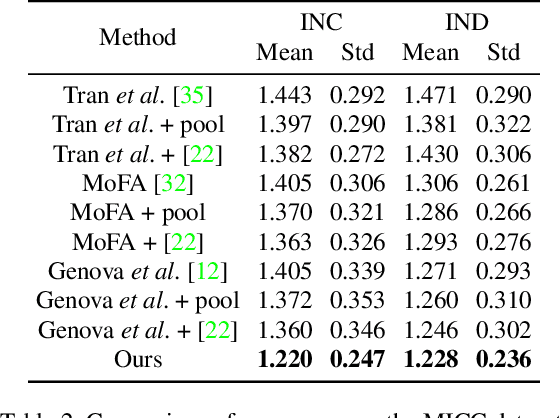
We address the problem of recovering the 3D geometry of a human face from a set of facial images in multiple views. While recent studies have shown impressive progress in 3D Morphable Model (3DMM) based facial reconstruction, the settings are mostly restricted to a single view. There is an inherent drawback in the single-view setting: the lack of reliable 3D constraints can cause unresolvable ambiguities. We in this paper explore 3DMM-based shape recovery in a different setting, where a set of multi-view facial images are given as input. A novel approach is proposed to regress 3DMM parameters from multi-view inputs with an end-to-end trainable Convolutional Neural Network (CNN). Multiview geometric constraints are incorporated into the network by establishing dense correspondences between different views leveraging a novel self-supervised view alignment loss. The main ingredient of the view alignment loss is a differentiable dense optical flow estimator that can backpropagate the alignment errors between an input view and a synthetic rendering from another input view, which is projected to the target view through the 3D shape to be inferred. Through minimizing the view alignment loss, better 3D shapes can be recovered such that the synthetic projections from one view to another can better align with the observed image. Extensive experiments demonstrate the superiority of the proposed method over other 3DMM methods.
Hierarchy Neighborhood Discriminative Hashing for An Unified View of Single-Label and Multi-Label Image retrieval
Jan 11, 2019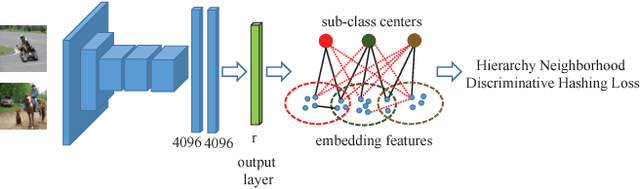

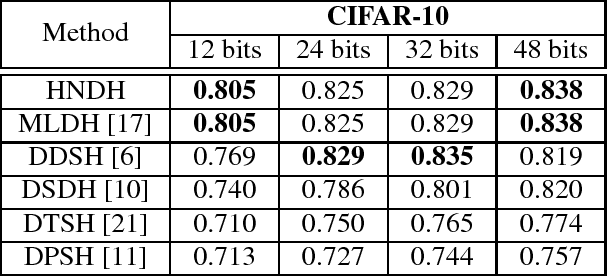
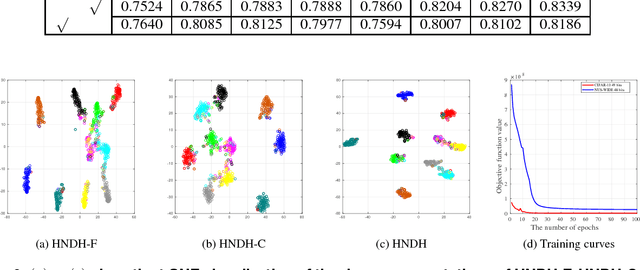
Recently, deep supervised hashing methods have become popular for large-scale image retrieval task. To preserve the semantic similarity notion between examples, they typically utilize the pairwise supervision or the triplet supervised information for hash learning. However, these methods usually ignore the semantic class information which can help the improvement of the semantic discriminative ability of hash codes. In this paper, we propose a novel hierarchy neighborhood discriminative hashing method. Specifically, we construct a bipartite graph to build coarse semantic neighbourhood relationship between the sub-class feature centers and the embeddings features. Moreover, we utilize the pairwise supervised information to construct the fined semantic neighbourhood relationship between embeddings features. Finally, we propose a hierarchy neighborhood discriminative hashing loss to unify the single-label and multilabel image retrieval problem with a one-stream deep neural network architecture. Experimental results on two largescale datasets demonstrate that the proposed method can outperform the state-of-the-art hashing methods.
3D Facial Expression Reconstruction using Cascaded Regression
Aug 17, 2018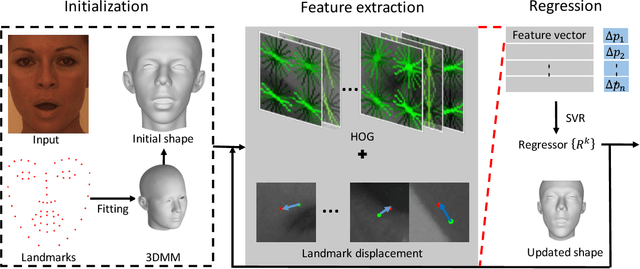
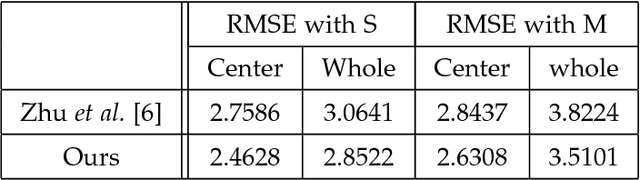
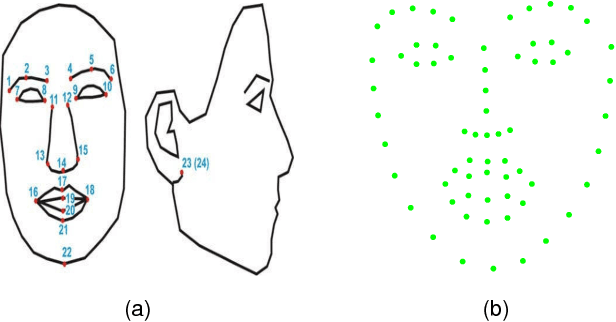
This paper proposes a novel model fitting algorithm for 3D facial expression reconstruction from a single image. Face expression reconstruction from a single image is a challenging task in computer vision. Most state-of-the-art methods fit the input image to a 3D Morphable Model (3DMM). These methods need to solve a stochastic problem and cannot deal with expression and pose variations. To solve this problem, we adopt a 3D face expression model and use a combined feature which is robust to scale, rotation and different lighting conditions. The proposed method applies a cascaded regression framework to estimate parameters for the 3DMM. 2D landmarks are detected and used to initialize the 3D shape and mapping matrices. In each iteration, residues between the current 3DMM parameters and the ground truth are estimated and then used to update the 3D shapes. The mapping matrices are also calculated based on the updated shapes and 2D landmarks. HOG features of the local patches and displacements between 3D landmark projections and 2D landmarks are exploited. Compared with existing methods, the proposed method is robust to expression and pose changes and can reconstruct higher fidelity 3D face shape.