 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025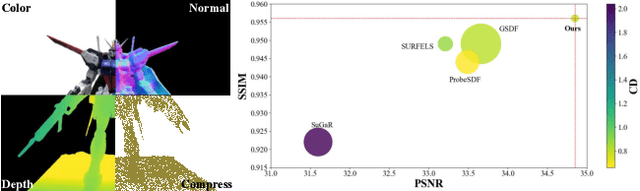
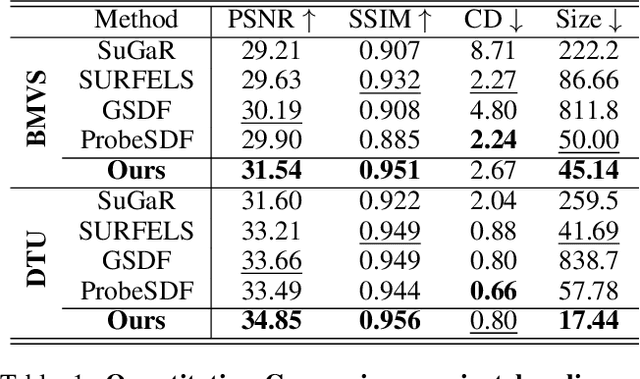
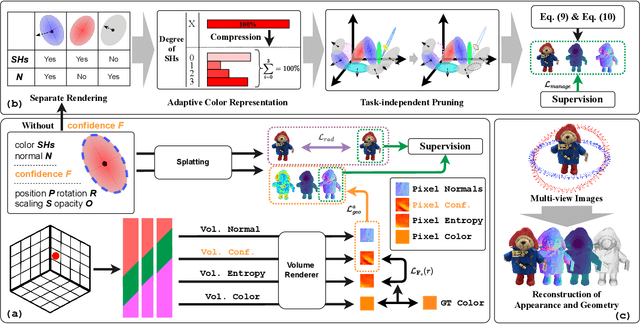
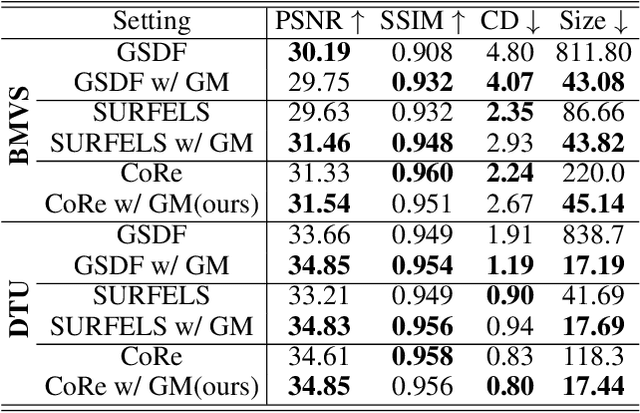
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
LLM-Enabled In-Context Learning for Data Collection Scheduling in UAV-assisted Sensor Networks
Apr 20, 2025Unmanned Aerial Vehicles (UAVs) are increasingly being used in various private and commercial applications, e.g. traffic control, package delivery, and Search and Rescue (SAR) operations. Machine Learning (ML) methods used in UAV-assisted Sensor Networks (UASNETs) and especially in Deep Reinforcement Learning (DRL) face challenges such as complex and lengthy model training, gaps between simulation and reality, and low sample efficiency, which conflict with the urgency of emergencies such as SAR operations. This paper proposes In-Context Learning (ICL)-based Data Collection Scheduling (ICLDC) scheme, as an alternative to DRL in emergencies. The UAV collects and transmits logged sensory data, to an LLM, to generate a task description in natural language, from which it obtains a data collection schedule to be executed by the UAV. The system continuously adapts by adding feedback to task descriptions and utilizing feedback for future decisions. This method is tested against jailbreaking attacks, where task description is manipulated to undermine network performance, highlighting the vulnerability of LLMs to such attacks. The proposed ICLDC outperforms the Maximum Channel Gain by reducing cumulative packet loss by approximately 56\%. ICLDC presents a promising direction for intelligent scheduling and control in UAV-assisted data collection.
RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
Feb 18, 2025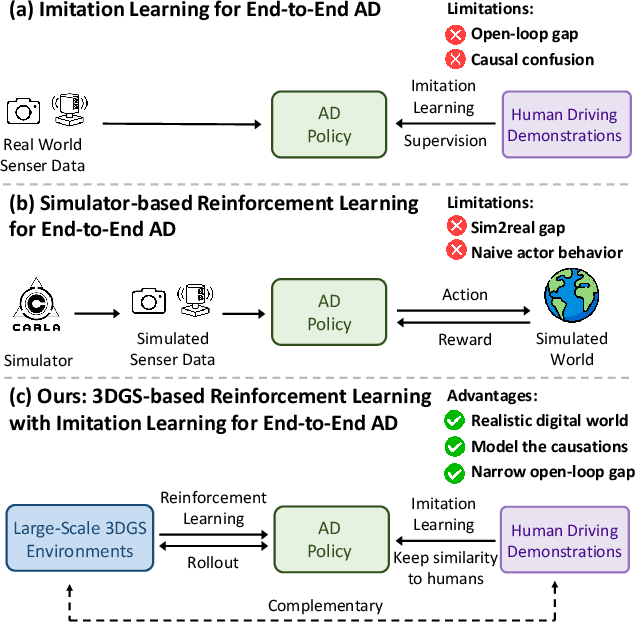
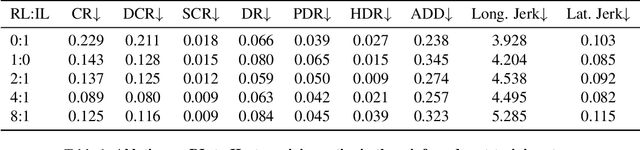
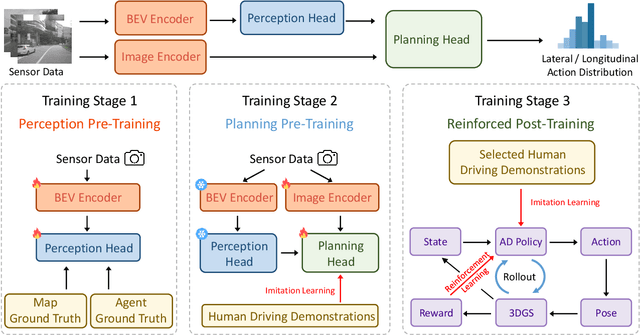
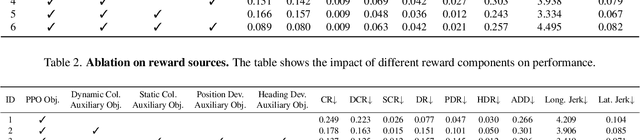
Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and the open-loop gap. In this work, we establish a 3DGS-based closed-loop Reinforcement Learning (RL) training paradigm. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards that guide the policy to effectively respond to safety-critical events and understand real-world causal relationships. For better alignment with human driving behavior, IL is incorporated into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, especially 3x lower collision rate. Abundant closed-loop results are presented at https://hgao-cv.github.io/RAD.
An Oversampling-enhanced Multi-class Imbalanced Classification Framework for Patient Health Status Prediction Using Patient-reported Outcomes
Nov 16, 2024



Patient-reported outcomes (PROs) directly collected from cancer patients being treated with radiation therapy play a vital role in assisting clinicians in counseling patients regarding likely toxicities. Precise prediction and evaluation of symptoms or health status associated with PROs are fundamental to enhancing decision-making and planning for the required services and support as patients transition into survivorship. However, the raw PRO data collected from hospitals exhibits some intrinsic challenges such as incomplete item reports and imbalance patient toxicities. To the end, in this study, we explore various machine learning techniques to predict patient outcomes related to health status such as pain levels and sleep discomfort using PRO datasets from a cancer photon/proton therapy center. Specifically, we deploy six advanced machine learning classifiers -- Random Forest (RF), XGBoost, Gradient Boosting (GB), Support Vector Machine (SVM), Multi-Layer Perceptron with Bagging (MLP-Bagging), and Logistic Regression (LR) -- to tackle a multi-class imbalance classification problem across three prevalent cancer types: head and neck, prostate, and breast cancers. To address the class imbalance issue, we employ an oversampling strategy, adjusting the training set sample sizes through interpolations of in-class neighboring samples, thereby augmenting minority classes without deviating from the original skewed class distribution. Our experimental findings across multiple PRO datasets indicate that the RF and XGB methods achieve robust generalization performance, evidenced by weighted AUC and detailed confusion matrices, in categorizing outcomes as mild, intermediate, and severe post-radiation therapy. These results underscore the models' effectiveness and potential utility in clinical settings.
LASER: Script Execution by Autonomous Agents for On-demand Traffic Simulation
Oct 21, 2024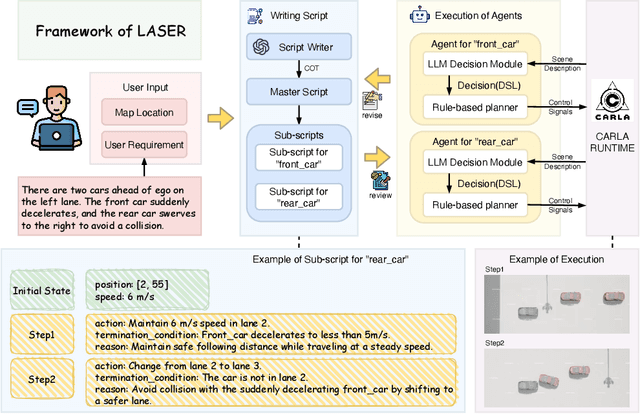
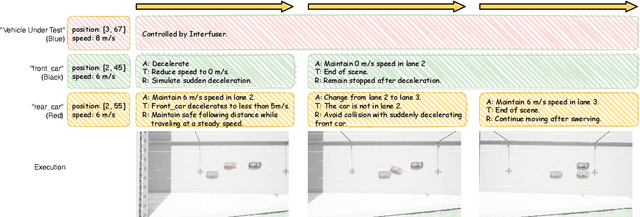
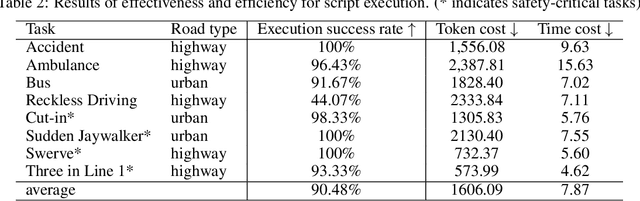
Autonomous Driving Systems (ADS) require diverse and safety-critical traffic scenarios for effective training and testing, but the existing data generation methods struggle to provide flexibility and scalability. We propose LASER, a novel frame-work that leverage large language models (LLMs) to conduct traffic simulations based on natural language inputs. The framework operates in two stages: it first generates scripts from user-provided descriptions and then executes them using autonomous agents in real time. Validated in the CARLA simulator, LASER successfully generates complex, on-demand driving scenarios, significantly improving ADS training and testing data generation.
Adaptive Advantage-Guided Policy Regularization for Offline Reinforcement Learning
Jun 01, 2024In offline reinforcement learning, the challenge of out-of-distribution (OOD) is pronounced. To address this, existing methods often constrain the learned policy through policy regularization. However, these methods often suffer from the issue of unnecessary conservativeness, hampering policy improvement. This occurs due to the indiscriminate use of all actions from the behavior policy that generates the offline dataset as constraints. The problem becomes particularly noticeable when the quality of the dataset is suboptimal. Thus, we propose Adaptive Advantage-guided Policy Regularization (A2PR), obtaining high-advantage actions from an augmented behavior policy combined with VAE to guide the learned policy. A2PR can select high-advantage actions that differ from those present in the dataset, while still effectively maintaining conservatism from OOD actions. This is achieved by harnessing the VAE capacity to generate samples matching the distribution of the data points. We theoretically prove that the improvement of the behavior policy is guaranteed. Besides, it effectively mitigates value overestimation with a bounded performance gap. Empirically, we conduct a series of experiments on the D4RL benchmark, where A2PR demonstrates state-of-the-art performance. Furthermore, experimental results on additional suboptimal mixed datasets reveal that A2PR exhibits superior performance. Code is available at https://github.com/ltlhuuu/A2PR.
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Feb 20, 2024



Learning a human-like driving policy from large-scale driving demonstrations is promising, but the uncertainty and non-deterministic nature of planning make it challenging. In this work, to cope with the uncertainty problem, we propose VADv2, an end-to-end driving model based on probabilistic planning. VADv2 takes multi-view image sequences as input in a streaming manner, transforms sensor data into environmental token embeddings, outputs the probabilistic distribution of action, and samples one action to control the vehicle. Only with camera sensors, VADv2 achieves state-of-the-art closed-loop performance on the CARLA Town05 benchmark, significantly outperforming all existing methods. It runs stably in a fully end-to-end manner, even without the rule-based wrapper. Closed-loop demos are presented at https://hgao-cv.github.io/VADv2.
Diverse and Lifespan Facial Age Transformation Synthesis with Identity Variation Rationality Metric
Jan 25, 2024



Face aging has received continuous research attention over the past two decades. Although previous works on this topic have achieved impressive success, two longstanding problems remain unsettled: 1) generating diverse and plausible facial aging patterns at the target age stage; 2) measuring the rationality of identity variation between the original portrait and its syntheses with age progression or regression. In this paper, we introduce DLAT + , the first algorithm that can realize Diverse and Lifespan Age Transformation on human faces, where the diversity jointly manifests in the transformation of facial textures and shapes. Apart from the diversity mechanism embedded in the model, multiple consistency restrictions are leveraged to keep it away from counterfactual aging syntheses. Moreover, we propose a new metric to assess the rationality of Identity Deviation under Age Gaps (IDAG) between the input face and its series of age-transformed generations, which is based on statistical laws summarized from plenty of genuine face-aging data. Extensive experimental results demonstrate the uniqueness and effectiveness of our method in synthesizing diverse and perceptually reasonable faces across the whole lifetime.
GaussianHead: Impressive 3D Gaussian-based Head Avatars with Dynamic Hybrid Neural Field
Dec 04, 2023



Previous head avatar methods have mostly relied on fixed explicit primitives (mesh, point) or implicit surfaces (Sign Distance Function) and volumetric neural radiance field, it challenging to strike a balance among high fidelity, training speed, and resource consumption. The recent popularity of hybrid field has brought novel representation, but is limited by relying on parameterization factors obtained through fixed mappings. We propose GaussianHead: an head avatar algorithm based on anisotropic 3D gaussian primitives. We leverage canonical gaussians to represent dynamic scenes. Using explicit "dynamic" tri-plane as an efficient container for parameterized head geometry, aligned well with factors in the underlying geometry and tri-plane, we obtain aligned canonical factors for the canonical gaussians. With a tiny MLP, factors are decoded into opacity and spherical harmonic coefficients of 3D gaussian primitives. Finally, we use efficient differentiable gaussian rasterizer for rendering. Our approach benefits significantly from our novel representation based on 3D gaussians, and the proper alignment transformation of underlying geometry structures and factors in tri-plane eliminates biases introduced by fixed mappings. Compared to state-of-the-art techniques, we achieve optimal visual results in tasks such as self-reconstruction, novel view synthesis, and cross-identity reenactment while maintaining high rendering efficiency (0.12s per frame). Even the pores around the nose are clearly visible in some cases. Code and additional video can be found on the project homepage.
Regression-free Blind Image Quality Assessment
Jul 18, 2023



Regression-based blind image quality assessment (IQA) models are susceptible to biased training samples, leading to a biased estimation of model parameters. To mitigate this issue, we propose a regression-free framework for image quality evaluation, which is founded upon retrieving similar instances by incorporating semantic and distortion features. The motivation behind this approach is rooted in the observation that the human visual system (HVS) has analogous visual responses to semantically similar image contents degraded by the same distortion. The proposed framework comprises two classification-based modules: semantic-based classification (SC) module and distortion-based classification (DC) module. Given a test image and an IQA database, the SC module retrieves multiple pristine images based on semantic similarity. The DC module then retrieves instances based on distortion similarity from the distorted images that correspond to each retrieved pristine image. Finally, the predicted quality score is derived by aggregating the subjective quality scores of multiple retrieved instances. Experimental results on four benchmark databases validate that the proposed model can remarkably outperform the state-of-the-art regression-based models.