 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality and Independence Enhancement for Biased Node Classification
Oct 14, 2023



Most existing methods that address out-of-distribution (OOD) generalization for node classification on graphs primarily focus on a specific type of data biases, such as label selection bias or structural bias. However, anticipating the type of bias in advance is extremely challenging, and designing models solely for one specific type may not necessarily improve overall generalization performance. Moreover, limited research has focused on the impact of mixed biases, which are more prevalent and demanding in real-world scenarios. To address these limitations, we propose a novel Causality and Independence Enhancement (CIE) framework, applicable to various graph neural networks (GNNs). Our approach estimates causal and spurious features at the node representation level and mitigates the influence of spurious correlations through the backdoor adjustment. Meanwhile, independence constraint is introduced to improve the discriminability and stability of causal and spurious features in complex biased environments. Essentially, CIE eliminates different types of data biases from a unified perspective, without the need to design separate methods for each bias as before. To evaluate the performance under specific types of data biases, mixed biases, and low-resource scenarios, we conducted comprehensive experiments on five publicly available datasets. Experimental results demonstrate that our approach CIE not only significantly enhances the performance of GNNs but outperforms state-of-the-art debiased node classification methods.
OpenGDA: Graph Domain Adaptation Benchmark for Cross-network Learning
Jul 21, 2023



Graph domain adaptation models are widely adopted in cross-network learning tasks, with the aim of transferring labeling or structural knowledge. Currently, there mainly exist two limitations in evaluating graph domain adaptation models. On one side, they are primarily tested for the specific cross-network node classification task, leaving tasks at edge-level and graph-level largely under-explored. Moreover, they are primarily tested in limited scenarios, such as social networks or citation networks, lacking validation of model's capability in richer scenarios. As comprehensively assessing models could enhance model practicality in real-world applications, we propose a benchmark, known as OpenGDA. It provides abundant pre-processed and unified datasets for different types of tasks (node, edge, graph). They originate from diverse scenarios, covering web information systems, urban systems and natural systems. Furthermore, it integrates state-of-the-art models with standardized and end-to-end pipelines. Overall, OpenGDA provides a user-friendly, scalable and reproducible benchmark for evaluating graph domain adaptation models. The benchmark experiments highlight the challenges of applying GDA models to real-world applications with consistent good performance, and potentially provide insights to future research. As an emerging project, OpenGDA will be regularly updated with new datasets and models. It could be accessed from https://github.com/Skyorca/OpenGDA.
Locate Who You Are: Matching Geo-location to Text for Anchor Link Prediction
Apr 19, 2021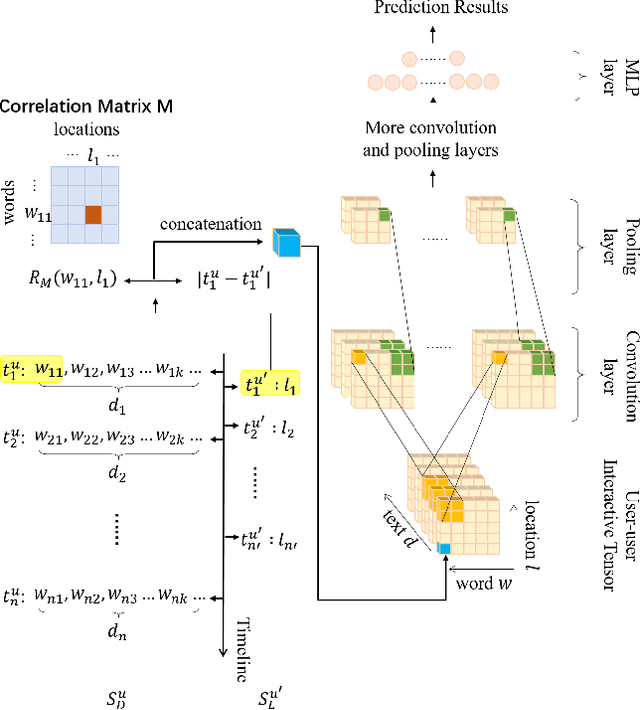
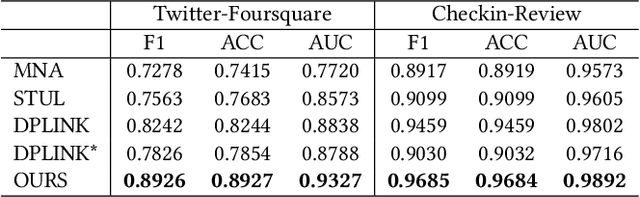
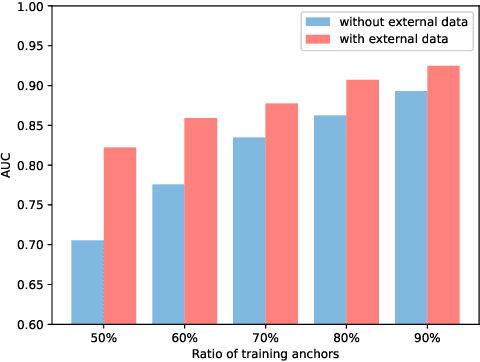
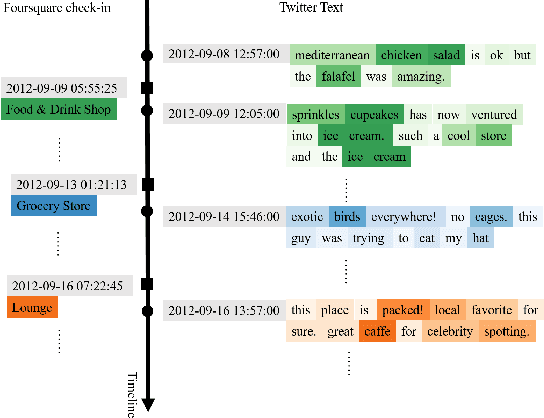
Nowadays, users are encouraged to activate across multiple online social networks simultaneously. Anchor link prediction, which aims to reveal the correspondence among different accounts of the same user across networks, has been regarded as a fundamental problem for user profiling, marketing, cybersecurity, and recommendation. Existing methods mainly address the prediction problem by utilizing profile, content, or structural features of users in symmetric ways. However, encouraged by online services, users would also post asymmetric information across networks, such as geo-locations and texts. It leads to an emerged challenge in aligning users with asymmetric information across networks. Instead of similarity evaluation applied in previous works, we formalize correlation between geo-locations and texts and propose a novel anchor link prediction framework for matching users across networks. Moreover, our model can alleviate the label scarcity problem by introducing external data. Experimental results on real-world datasets show that our approach outperforms existing methods and achieves state-of-the-art results.