 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025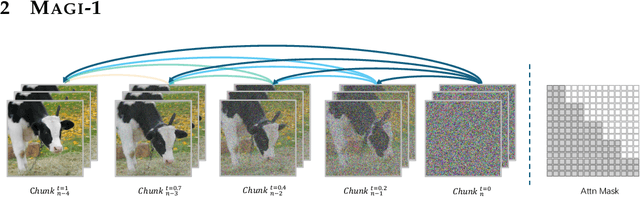
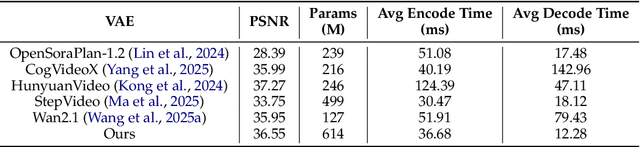
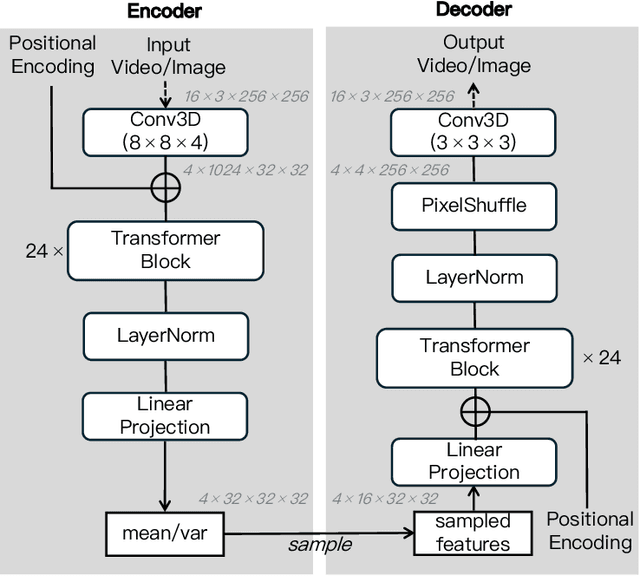
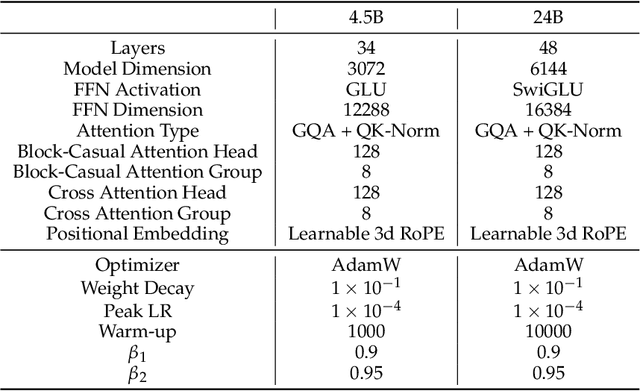
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Neuro-symbolic Learning Yielding Logical Constraints
Oct 28, 2024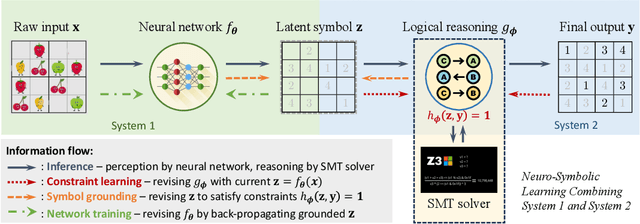
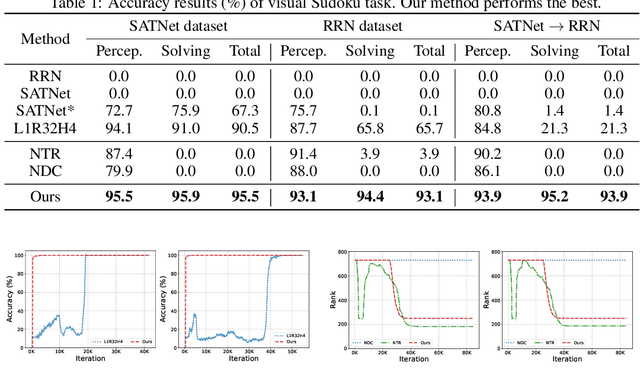
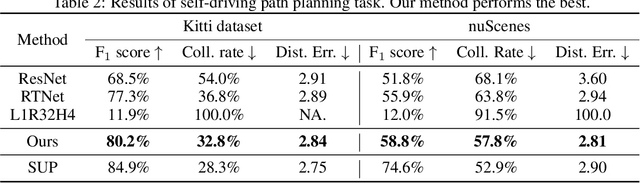
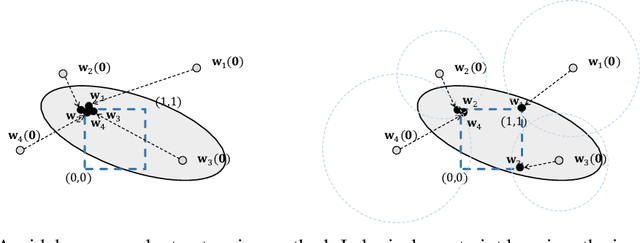
Neuro-symbolic systems combine the abilities of neural perception and logical reasoning. However, end-to-end learning of neuro-symbolic systems is still an unsolved challenge. This paper proposes a natural framework that fuses neural network training, symbol grounding, and logical constraint synthesis into a coherent and efficient end-to-end learning process. The capability of this framework comes from the improved interactions between the neural and the symbolic parts of the system in both the training and inference stages. Technically, to bridge the gap between the continuous neural network and the discrete logical constraint, we introduce a difference-of-convex programming technique to relax the logical constraints while maintaining their precision. We also employ cardinality constraints as the language for logical constraint learning and incorporate a trust region method to avoid the degeneracy of logical constraint in learning. Both theoretical analyses and empirical evaluations substantiate the effectiveness of the proposed framework.
LASER: Script Execution by Autonomous Agents for On-demand Traffic Simulation
Oct 21, 2024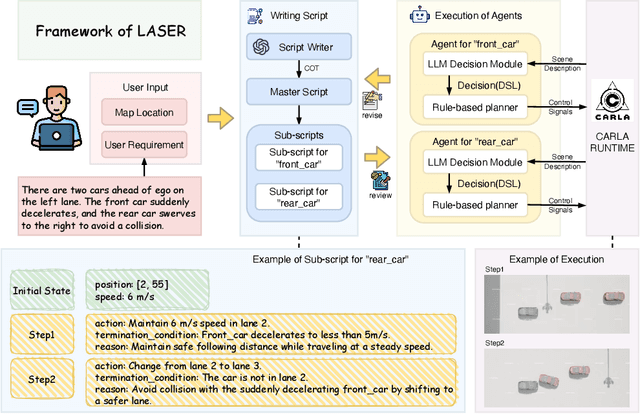
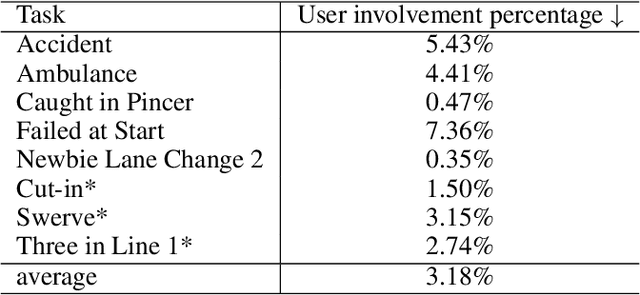
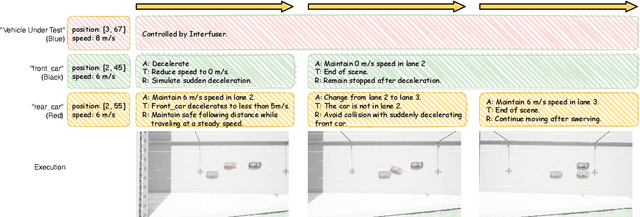
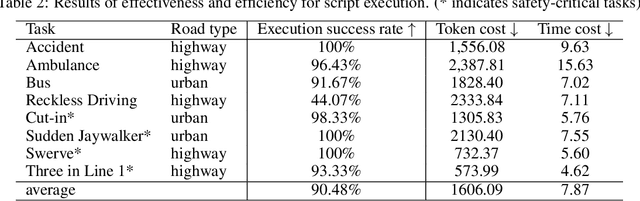
Autonomous Driving Systems (ADS) require diverse and safety-critical traffic scenarios for effective training and testing, but the existing data generation methods struggle to provide flexibility and scalability. We propose LASER, a novel frame-work that leverage large language models (LLMs) to conduct traffic simulations based on natural language inputs. The framework operates in two stages: it first generates scripts from user-provided descriptions and then executes them using autonomous agents in real time. Validated in the CARLA simulator, LASER successfully generates complex, on-demand driving scenarios, significantly improving ADS training and testing data generation.
Executing Arithmetic: Fine-Tuning Large Language Models as Turing Machines
Oct 10, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing and reasoning tasks. However, their performance in the foundational domain of arithmetic remains unsatisfactory. When dealing with arithmetic tasks, LLMs often memorize specific examples rather than learning the underlying computational logic, limiting their ability to generalize to new problems. In this paper, we propose a Composable Arithmetic Execution Framework (CAEF) that enables LLMs to learn to execute step-by-step computations by emulating Turing Machines, thereby gaining a genuine understanding of computational logic. Moreover, the proposed framework is highly scalable, allowing composing learned operators to significantly reduce the difficulty of learning complex operators. In our evaluation, CAEF achieves nearly 100% accuracy across seven common mathematical operations on the LLaMA 3.1-8B model, effectively supporting computations involving operands with up to 100 digits, a level where GPT-4o falls short noticeably in some settings.
MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models
May 19, 2024



The \textit{pretrain+fine-tune} paradigm is foundational in deploying large language models (LLMs) across a diverse range of downstream applications. Among these, Low-Rank Adaptation (LoRA) stands out for its parameter-efficient fine-tuning (PEFT), producing numerous off-the-shelf task-specific LoRA adapters. However, this approach requires explicit task intention selection, posing challenges for automatic task sensing and switching during inference with multiple existing LoRA adapters embedded in a single LLM. In this work, we introduce \textbf{\method} (\textbf{M}ultiple-\textbf{T}asks embedded \textbf{LoRA}), a scalable multi-knowledge LoRA fusion framework designed for LLMs. \method\ integrates various LoRA adapters in a Mixture-of-Experts (MoE) style into the base LLM, enabling the model to automatically select the most pertinent adapter based on the task input. This advancement significantly enhances the LLM's capability to handle composite tasks that require different adapters to solve various components of the problem. Our evaluations, featuring the LlaMA2-13B and LlaMA3-8B base models equipped with off-the-shelf 28 LoRA adapters through \method, demonstrate equivalent performance with the individual adapters. Furthermore, both base models equipped with \method\ achieve superior performance in sequentially solving composite tasks with ten problems in only a single inference process, highlighting the ability of timely intention switching in \method\ embedded LLMs.
Securing Reliability: A Brief Overview on Enhancing In-Context Learning for Foundation Models
Feb 27, 2024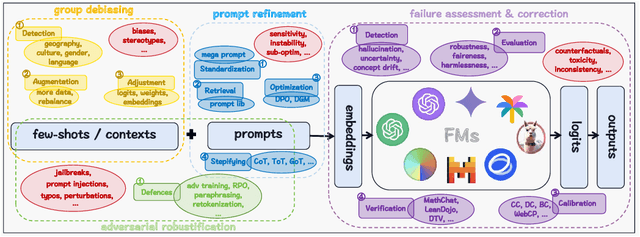


As foundation models (FMs) continue to shape the landscape of AI, the in-context learning (ICL) paradigm thrives but also encounters issues such as toxicity, hallucination, disparity, adversarial vulnerability, and inconsistency. Ensuring the reliability and responsibility of FMs is crucial for the sustainable development of the AI ecosystem. In this concise overview, we investigate recent advancements in enhancing the reliability and trustworthiness of FMs within ICL frameworks, focusing on four key methodologies, each with its corresponding subgoals. We sincerely hope this paper can provide valuable insights for researchers and practitioners endeavoring to build safe and dependable FMs and foster a stable and consistent ICL environment, thereby unlocking their vast potential.
Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey
Nov 21, 2023



With the bomb ignited by ChatGPT, Transformer-based Large Language Models (LLMs) have paved a revolutionary path toward Artificial General Intelligence (AGI) and have been applied in diverse areas as knowledge bases, human interfaces, and dynamic agents. However, a prevailing limitation exists: many current LLMs, constrained by resources, are primarily pre-trained on shorter texts, rendering them less effective for longer-context prompts, commonly encountered in real-world settings. In this paper, we present a comprehensive survey focusing on the advancement of model architecture in Transformer-based LLMs to optimize long-context capabilities across all stages from pre-training to inference. We firstly delineate and analyze the problems of handling long-context input and output with the current Transformer-based models. Then, we mainly offer a holistic taxonomy to navigate the landscape of Transformer upgrades on architecture to solve these problems. Afterward, we provide the investigation on wildly used evaluation necessities tailored for long-context LLMs, including datasets, metrics, and baseline models, as well as some amazing optimization toolkits like libraries, systems, and compilers to augment LLMs' efficiency and efficacy across different stages. Finally, we further discuss the predominant challenges and potential avenues for future research in this domain. Additionally, we have established a repository where we curate relevant literature with real-time updates at https://github.com/Strivin0311/long-llms-learning.