 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise: Neuro-Symbolic Proof Search for Automated Systems Verification
Mar 20, 2026Formal verification via interactive theorem proving is increasingly used to ensure the correctness of critical systems, yet constructing large proof scripts remains highly manual and limits scalability. Advances in large language models (LLMs), especially in mathematical reasoning, make their integration into software verification increasingly promising. This paper introduces a neuro-symbolic proof generation framework designed to automate proof search for systems-level verification projects. The framework performs a best-first tree search over proof states, repeatedly querying an LLM for the next candidate proof step. On the neural side, we fine-tune LLMs using datasets of proof state-step pairs; on the symbolic side, we incorporate a range of ITP tools to repair rejected steps, filter and rank proof states, and automatically discharge subgoals when search progress stalls. This synergy enables data-efficient LLM adaptation and semantics-informed pruning of the search space. We implement the framework on a new Isabelle REPL that exposes fine-grained proof states and automation tools, and evaluate it on the FVEL seL4 benchmark and additional Isabelle developments. On seL4, the system proves up to 77.6\% of the theorems, substantially surpassing previous LLM-based approaches and standalone Sledgehammer, while solving significantly more multi-step proofs. Results across further benchmarks demonstrate strong generalization, indicating a viable path toward scalable automated software verification.
Learning to Disprove: Formal Counterexample Generation with Large Language Models
Mar 19, 2026Mathematical reasoning demands two critical, complementary skills: constructing rigorous proofs for true statements and discovering counterexamples that disprove false ones. However, current AI efforts in mathematics focus almost exclusively on proof construction, often neglecting the equally important task of finding counterexamples. In this paper, we address this gap by fine-tuning large language models (LLMs) to reason about and generate counterexamples. We formalize this task as formal counterexample generation, which requires LLMs not only to propose candidate counterexamples but also to produce formal proofs that can be automatically verified in the Lean 4 theorem prover. To enable effective learning, we introduce a symbolic mutation strategy that synthesizes diverse training data by systematically extracting theorems and discarding selected hypotheses, thereby producing diverse counterexample instances. Together with curated datasets, this strategy enables a multi-reward expert iteration framework that substantially enhances both the effectiveness and efficiency of training LLMs for counterexample generation and theorem proving. Experiments on three newly collected benchmarks validate the advantages of our approach, showing that the mutation strategy and training framework yield significant performance gains.
AlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Feb 10, 2026Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
Bridging Your Imagination with Audio-Video Generation via a Unified Director
Dec 29, 2025Existing AI-driven video creation systems typically treat script drafting and key-shot design as two disjoint tasks: the former relies on large language models, while the latter depends on image generation models. We argue that these two tasks should be unified within a single framework, as logical reasoning and imaginative thinking are both fundamental qualities of a film director. In this work, we propose UniMAGE, a unified director model that bridges user prompts with well-structured scripts, thereby empowering non-experts to produce long-context, multi-shot films by leveraging existing audio-video generation models. To achieve this, we employ the Mixture-of-Transformers architecture that unifies text and image generation. To further enhance narrative logic and keyframe consistency, we introduce a ``first interleaving, then disentangling'' training paradigm. Specifically, we first perform Interleaved Concept Learning, which utilizes interleaved text-image data to foster the model's deeper understanding and imaginative interpretation of scripts. We then conduct Disentangled Expert Learning, which decouples script writing from keyframe generation, enabling greater flexibility and creativity in storytelling. Extensive experiments demonstrate that UniMAGE achieves state-of-the-art performance among open-source models, generating logically coherent video scripts and visually consistent keyframe images.
Reviving DSP for Advanced Theorem Proving in the Era of Reasoning Models
Jun 13, 2025Recent advancements, such as DeepSeek-Prover-V2-671B and Kimina-Prover-Preview-72B, demonstrate a prevailing trend in leveraging reinforcement learning (RL)-based large-scale training for automated theorem proving. Surprisingly, we discover that even without any training, careful neuro-symbolic coordination of existing off-the-shelf reasoning models and tactic step provers can achieve comparable performance. This paper introduces \textbf{DSP+}, an improved version of the Draft, Sketch, and Prove framework, featuring a \emph{fine-grained and integrated} neuro-symbolic enhancement for each phase: (1) In the draft phase, we prompt reasoning models to generate concise natural-language subgoals to benefit the sketch phase, removing thinking tokens and references to human-written proofs; (2) In the sketch phase, subgoals are autoformalized with hypotheses to benefit the proving phase, and sketch lines containing syntactic errors are masked according to predefined rules; (3) In the proving phase, we tightly integrate symbolic search methods like Aesop with step provers to establish proofs for the sketch subgoals. Experimental results show that, without any additional model training or fine-tuning, DSP+ solves 80.7\%, 32.8\%, and 24 out of 644 problems from miniF2F, ProofNet, and PutnamBench, respectively, while requiring fewer budgets compared to state-of-the-arts. DSP+ proves \texttt{imo\_2019\_p1}, an IMO problem in miniF2F that is not solved by any prior work. Additionally, DSP+ generates proof patterns comprehensible by human experts, facilitating the identification of formalization errors; For example, eight wrongly formalized statements in miniF2F are discovered. Our results highlight the potential of classical reasoning patterns besides the RL-based training. All components will be open-sourced.
Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning
Feb 19, 2025



Large language models (LLMs) can prove mathematical theorems formally by generating proof steps (\textit{a.k.a.} tactics) within a proof system. However, the space of possible tactics is vast and complex, while the available training data for formal proofs is limited, posing a significant challenge to LLM-based tactic generation. To address this, we introduce a neuro-symbolic tactic generator that synergizes the mathematical intuition learned by LLMs with domain-specific insights encoded by symbolic methods. The key aspect of this integration is identifying which parts of mathematical reasoning are best suited to LLMs and which to symbolic methods. While the high-level idea of neuro-symbolic integration is broadly applicable to various mathematical problems, in this paper, we focus specifically on Olympiad inequalities (Figure~1). We analyze how humans solve these problems and distill the techniques into two types of tactics: (1) scaling, handled by symbolic methods, and (2) rewriting, handled by LLMs. In addition, we combine symbolic tools with LLMs to prune and rank the proof goals for efficient proof search. We evaluate our framework on 161 challenging inequalities from multiple mathematics competitions, achieving state-of-the-art performance and significantly outperforming existing LLM and symbolic approaches without requiring additional training data.
Neuro-Symbolic Data Generation for Math Reasoning
Dec 06, 2024



A critical question about Large Language Models (LLMs) is whether their apparent deficiency in mathematical reasoning is inherent, or merely a result of insufficient exposure to high-quality mathematical data. To explore this, we developed an automated method for generating high-quality, supervised mathematical datasets. The method carefully mutates existing math problems, ensuring both diversity and validity of the newly generated problems. This is achieved by a neuro-symbolic data generation framework combining the intuitive informalization strengths of LLMs, and the precise symbolic reasoning of math solvers along with projected Markov chain Monte Carlo sampling in the highly-irregular symbolic space. Empirical experiments demonstrate the high quality of data generated by the proposed method, and that the LLMs, specifically LLaMA-2 and Mistral, when realigned with the generated data, surpass their state-of-the-art counterparts.
Decoupling Training-Free Guided Diffusion by ADMM
Nov 18, 2024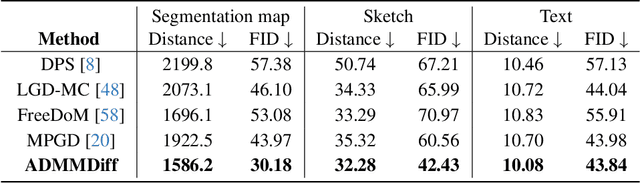
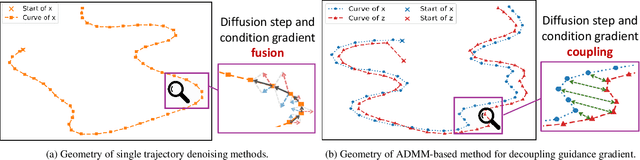


In this paper, we consider the conditional generation problem by guiding off-the-shelf unconditional diffusion models with differentiable loss functions in a plug-and-play fashion. While previous research has primarily focused on balancing the unconditional diffusion model and the guided loss through a tuned weight hyperparameter, we propose a novel framework that distinctly decouples these two components. Specifically, we introduce two variables ${x}$ and ${z}$, to represent the generated samples governed by the unconditional generation model and the guidance function, respectively. This decoupling reformulates conditional generation into two manageable subproblems, unified by the constraint ${x} = {z}$. Leveraging this setup, we develop a new algorithm based on the Alternating Direction Method of Multipliers (ADMM) to adaptively balance these components. Additionally, we establish the equivalence between the diffusion reverse step and the proximal operator of ADMM and provide a detailed convergence analysis of our algorithm under certain mild assumptions. Our experiments demonstrate that our proposed method ADMMDiff consistently generates high-quality samples while ensuring strong adherence to the conditioning criteria. It outperforms existing methods across a range of conditional generation tasks, including image generation with various guidance and controllable motion synthesis.
Autoformalize Mathematical Statements by Symbolic Equivalence and Semantic Consistency
Oct 28, 2024
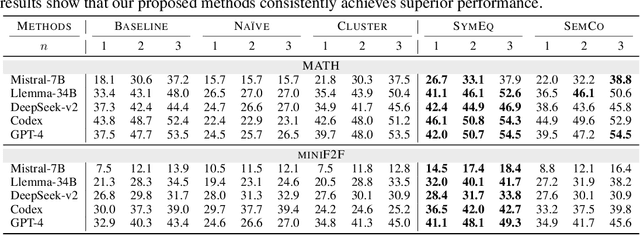

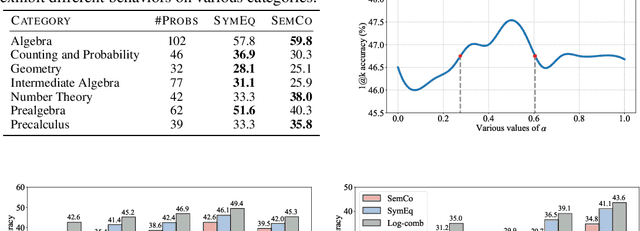
Autoformalization, the task of automatically translating natural language descriptions into a formal language, poses a significant challenge across various domains, especially in mathematics. Recent advancements in large language models (LLMs) have unveiled their promising capabilities to formalize even competition-level math problems. However, we observe a considerable discrepancy between pass@1 and pass@k accuracies in LLM-generated formalizations. To address this gap, we introduce a novel framework that scores and selects the best result from k autoformalization candidates based on two complementary self-consistency methods: symbolic equivalence and semantic consistency. Elaborately, symbolic equivalence identifies the logical homogeneity among autoformalization candidates using automated theorem provers, and semantic consistency evaluates the preservation of the original meaning by informalizing the candidates and computing the similarity between the embeddings of the original and informalized texts. Our extensive experiments on the MATH and miniF2F datasets demonstrate that our approach significantly enhances autoformalization accuracy, achieving up to 0.22-1.35x relative improvements across various LLMs and baseline methods.
Neuro-symbolic Learning Yielding Logical Constraints
Oct 28, 2024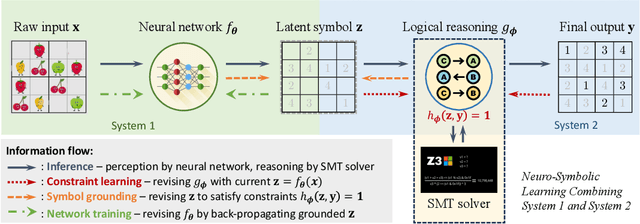
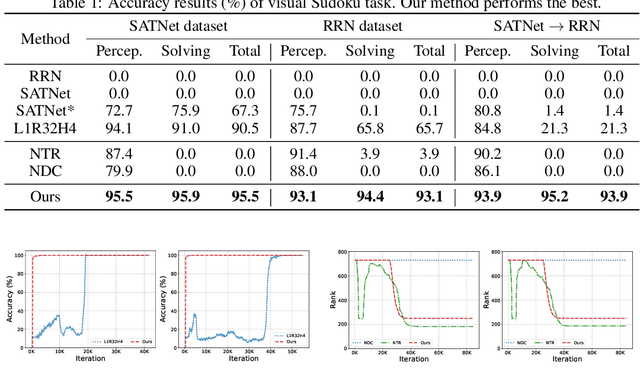
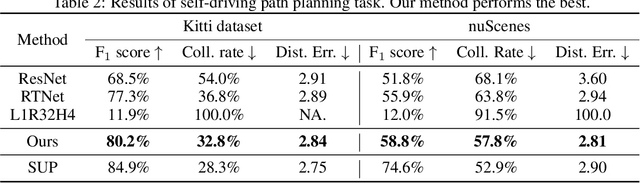
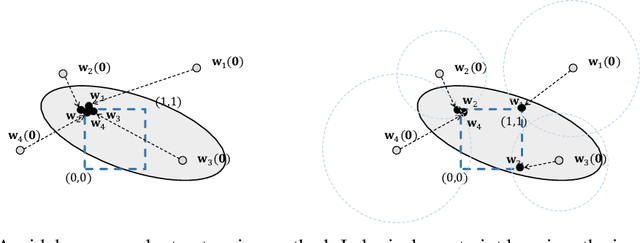
Neuro-symbolic systems combine the abilities of neural perception and logical reasoning. However, end-to-end learning of neuro-symbolic systems is still an unsolved challenge. This paper proposes a natural framework that fuses neural network training, symbol grounding, and logical constraint synthesis into a coherent and efficient end-to-end learning process. The capability of this framework comes from the improved interactions between the neural and the symbolic parts of the system in both the training and inference stages. Technically, to bridge the gap between the continuous neural network and the discrete logical constraint, we introduce a difference-of-convex programming technique to relax the logical constraints while maintaining their precision. We also employ cardinality constraints as the language for logical constraint learning and incorporate a trust region method to avoid the degeneracy of logical constraint in learning. Both theoretical analyses and empirical evaluations substantiate the effectiveness of the proposed framework.