 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedbackSTS-Det: Sparse Frames-Based Spatio-Temporal Semantic Feedback Network for Infrared Small Target Detection
Jan 21, 2026Infrared small target detection (ISTD) under complex backgrounds remains a critical yet challenging task, primarily due to the extremely low signal-to-clutter ratio, persistent dynamic interference, and the lack of distinct target features. While multi-frame detection methods leverages temporal cues to improve upon single-frame approaches, existing methods still struggle with inefficient long-range dependency modeling and insufficient robustness. To overcome these issues, we propose a novel scheme for ISTD, realized through a sparse frames-based spatio-temporal semantic feedback network named FeedbackSTS-Det. The core of our approach is a novel spatio-temporal semantic feedback strategy with a closed-loop semantic association mechanism, which consists of paired forward and backward refinement modules that work cooperatively across the encoder and decoder. Moreover, both modules incorporate an embedded sparse semantic module (SSM), which performs structured sparse temporal modeling to capture long-range dependencies with low computational cost. This integrated design facilitates robust implicit inter-frame registration and continuous semantic refinement, effectively suppressing false alarms. Furthermore, our overall procedure maintains a consistent training-inference pipeline, which ensures reliable performance transfer and increases model robustness. Extensive experiments on multiple benchmark datasets confirm the effectiveness of FeedbackSTS-Det. Code and models are available at: https://github.com/IDIP-Lab/FeedbackSTS-Det.
Vibe Reasoning: Eliciting Frontier AI Mathematical Capabilities -- A Case Study on IMO 2025 Problem 6
Dec 22, 2025We introduce Vibe Reasoning, a human-AI collaborative paradigm for solving complex mathematical problems. Our key insight is that frontier AI models already possess the knowledge required to solve challenging problems -- they simply do not know how, what, or when to apply it. Vibe Reasoning transforms AI's latent potential into manifested capability through generic meta-prompts, agentic grounding, and model orchestration. We demonstrate this paradigm through IMO 2025 Problem 6, a combinatorial optimization problem where autonomous AI systems publicly reported failures. Our solution combined GPT-5's exploratory capabilities with Gemini 3 Pro's proof strengths, leveraging agentic workflows with Python code execution and file-based memory, to derive both the correct answer (2112) and a rigorous mathematical proof. Through iterative refinement across multiple attempts, we discovered the necessity of agentic grounding and model orchestration, while human prompts evolved from problem-specific hints to generic, transferable meta-prompts. We analyze why capable AI fails autonomously, how each component addresses specific failure modes, and extract principles for effective vibe reasoning. Our findings suggest that lightweight human guidance can unlock frontier models' mathematical reasoning potential. This is ongoing work; we are developing automated frameworks and conducting broader evaluations to further validate Vibe Reasoning's generality and effectiveness.
Reviving DSP for Advanced Theorem Proving in the Era of Reasoning Models
Jun 13, 2025Recent advancements, such as DeepSeek-Prover-V2-671B and Kimina-Prover-Preview-72B, demonstrate a prevailing trend in leveraging reinforcement learning (RL)-based large-scale training for automated theorem proving. Surprisingly, we discover that even without any training, careful neuro-symbolic coordination of existing off-the-shelf reasoning models and tactic step provers can achieve comparable performance. This paper introduces \textbf{DSP+}, an improved version of the Draft, Sketch, and Prove framework, featuring a \emph{fine-grained and integrated} neuro-symbolic enhancement for each phase: (1) In the draft phase, we prompt reasoning models to generate concise natural-language subgoals to benefit the sketch phase, removing thinking tokens and references to human-written proofs; (2) In the sketch phase, subgoals are autoformalized with hypotheses to benefit the proving phase, and sketch lines containing syntactic errors are masked according to predefined rules; (3) In the proving phase, we tightly integrate symbolic search methods like Aesop with step provers to establish proofs for the sketch subgoals. Experimental results show that, without any additional model training or fine-tuning, DSP+ solves 80.7\%, 32.8\%, and 24 out of 644 problems from miniF2F, ProofNet, and PutnamBench, respectively, while requiring fewer budgets compared to state-of-the-arts. DSP+ proves \texttt{imo\_2019\_p1}, an IMO problem in miniF2F that is not solved by any prior work. Additionally, DSP+ generates proof patterns comprehensible by human experts, facilitating the identification of formalization errors; For example, eight wrongly formalized statements in miniF2F are discovered. Our results highlight the potential of classical reasoning patterns besides the RL-based training. All components will be open-sourced.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
May 23, 2025Humans naturally understand moments in a video by integrating visual and auditory cues. For example, localizing a scene in the video like "A scientist passionately speaks on wildlife conservation as dramatic orchestral music plays, with the audience nodding and applauding" requires simultaneous processing of visual, audio, and speech signals. However, existing models often struggle to effectively fuse and interpret audio information, limiting their capacity for comprehensive video temporal understanding. To address this, we present TriSense, a triple-modality large language model designed for holistic video temporal understanding through the integration of visual, audio, and speech modalities. Central to TriSense is a Query-Based Connector that adaptively reweights modality contributions based on the input query, enabling robust performance under modality dropout and allowing flexible combinations of available inputs. To support TriSense's multimodal capabilities, we introduce TriSense-2M, a high-quality dataset of over 2 million curated samples generated via an automated pipeline powered by fine-tuned LLMs. TriSense-2M includes long-form videos and diverse modality combinations, facilitating broad generalization. Extensive experiments across multiple benchmarks demonstrate the effectiveness of TriSense and its potential to advance multimodal video analysis. Code and dataset will be publicly released.
Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning
Feb 19, 2025



Large language models (LLMs) can prove mathematical theorems formally by generating proof steps (\textit{a.k.a.} tactics) within a proof system. However, the space of possible tactics is vast and complex, while the available training data for formal proofs is limited, posing a significant challenge to LLM-based tactic generation. To address this, we introduce a neuro-symbolic tactic generator that synergizes the mathematical intuition learned by LLMs with domain-specific insights encoded by symbolic methods. The key aspect of this integration is identifying which parts of mathematical reasoning are best suited to LLMs and which to symbolic methods. While the high-level idea of neuro-symbolic integration is broadly applicable to various mathematical problems, in this paper, we focus specifically on Olympiad inequalities (Figure~1). We analyze how humans solve these problems and distill the techniques into two types of tactics: (1) scaling, handled by symbolic methods, and (2) rewriting, handled by LLMs. In addition, we combine symbolic tools with LLMs to prune and rank the proof goals for efficient proof search. We evaluate our framework on 161 challenging inequalities from multiple mathematics competitions, achieving state-of-the-art performance and significantly outperforming existing LLM and symbolic approaches without requiring additional training data.
Multi-task Visual Grounding with Coarse-to-Fine Consistency Constraints
Jan 12, 2025
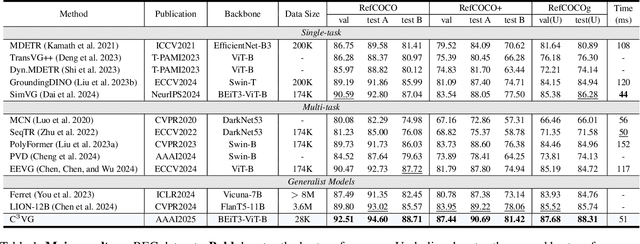

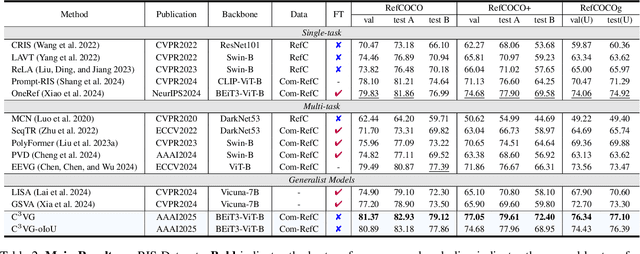
Multi-task visual grounding involves the simultaneous execution of localization and segmentation in images based on textual expressions. The majority of advanced methods predominantly focus on transformer-based multimodal fusion, aiming to extract robust multimodal representations. However, ambiguity between referring expression comprehension (REC) and referring image segmentation (RIS) is error-prone, leading to inconsistencies between multi-task predictions. Besides, insufficient multimodal understanding directly contributes to biased target perception. To overcome these challenges, we propose a Coarse-to-fine Consistency Constraints Visual Grounding architecture ($\text{C}^3\text{VG}$), which integrates implicit and explicit modeling approaches within a two-stage framework. Initially, query and pixel decoders are employed to generate preliminary detection and segmentation outputs, a process referred to as the Rough Semantic Perception (RSP) stage. These coarse predictions are subsequently refined through the proposed Mask-guided Interaction Module (MIM) and a novel explicit bidirectional consistency constraint loss to ensure consistent representations across tasks, which we term the Refined Consistency Interaction (RCI) stage. Furthermore, to address the challenge of insufficient multimodal understanding, we leverage pre-trained models based on visual-linguistic fusion representations. Empirical evaluations on the RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate the efficacy and soundness of $\text{C}^3\text{VG}$, which significantly outperforms state-of-the-art REC and RIS methods by a substantial margin. Code and model will be available at \url{https://github.com/Dmmm1997/C3VG}.
Neuro-Symbolic Data Generation for Math Reasoning
Dec 06, 2024



A critical question about Large Language Models (LLMs) is whether their apparent deficiency in mathematical reasoning is inherent, or merely a result of insufficient exposure to high-quality mathematical data. To explore this, we developed an automated method for generating high-quality, supervised mathematical datasets. The method carefully mutates existing math problems, ensuring both diversity and validity of the newly generated problems. This is achieved by a neuro-symbolic data generation framework combining the intuitive informalization strengths of LLMs, and the precise symbolic reasoning of math solvers along with projected Markov chain Monte Carlo sampling in the highly-irregular symbolic space. Empirical experiments demonstrate the high quality of data generated by the proposed method, and that the LLMs, specifically LLaMA-2 and Mistral, when realigned with the generated data, surpass their state-of-the-art counterparts.
Autoformalize Mathematical Statements by Symbolic Equivalence and Semantic Consistency
Oct 28, 2024
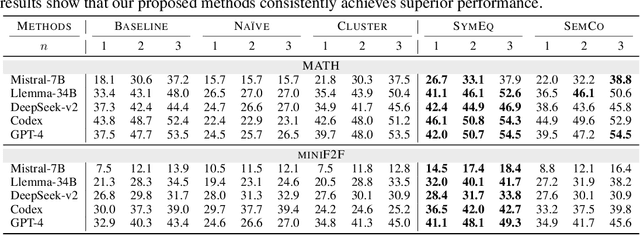

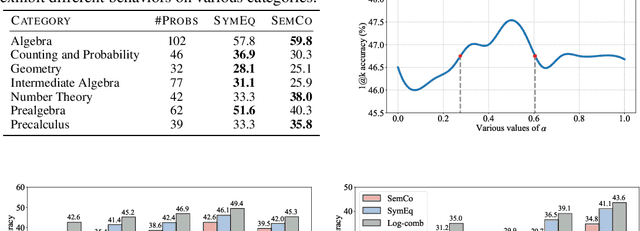
Autoformalization, the task of automatically translating natural language descriptions into a formal language, poses a significant challenge across various domains, especially in mathematics. Recent advancements in large language models (LLMs) have unveiled their promising capabilities to formalize even competition-level math problems. However, we observe a considerable discrepancy between pass@1 and pass@k accuracies in LLM-generated formalizations. To address this gap, we introduce a novel framework that scores and selects the best result from k autoformalization candidates based on two complementary self-consistency methods: symbolic equivalence and semantic consistency. Elaborately, symbolic equivalence identifies the logical homogeneity among autoformalization candidates using automated theorem provers, and semantic consistency evaluates the preservation of the original meaning by informalizing the candidates and computing the similarity between the embeddings of the original and informalized texts. Our extensive experiments on the MATH and miniF2F datasets demonstrate that our approach significantly enhances autoformalization accuracy, achieving up to 0.22-1.35x relative improvements across various LLMs and baseline methods.
Exploit CAM by itself: Complementary Learning System for Weakly Supervised Semantic Segmentation
Mar 04, 2023



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has long been suffering from fragmentary object regions led by Class Activation Map (CAM), which is incapable of generating fine-grained masks for semantic segmentation. To guide CAM to find more non-discriminating object patterns, this paper turns to an interesting working mechanism in agent learning named Complementary Learning System (CLS). CLS holds that the neocortex builds a sensation of general knowledge, while the hippocampus specially learns specific details, completing the learned patterns. Motivated by this simple but effective learning pattern, we propose a General-Specific Learning Mechanism (GSLM) to explicitly drive a coarse-grained CAM to a fine-grained pseudo mask. Specifically, GSLM develops a General Learning Module (GLM) and a Specific Learning Module (SLM). The GLM is trained with image-level supervision to extract coarse and general localization representations from CAM. Based on the general knowledge in the GLM, the SLM progressively exploits the specific spatial knowledge from the localization representations, expanding the CAM in an explicit way. To this end, we propose the Seed Reactivation to help SLM reactivate non-discriminating regions by setting a boundary for activation values, which successively identifies more regions of CAM. Without extra refinement processes, our method is able to achieve breakthrough improvements for CAM of over 20.0% mIoU on PASCAL VOC 2012 and 10.0% mIoU on MS COCO 2014 datasets, representing a new state-of-the-art among existing WSSS methods.
EfficientGrasp: A Unified Data-Efficient Learning to Grasp Method for Multi-fingered Robot Hands
Jun 30, 2022
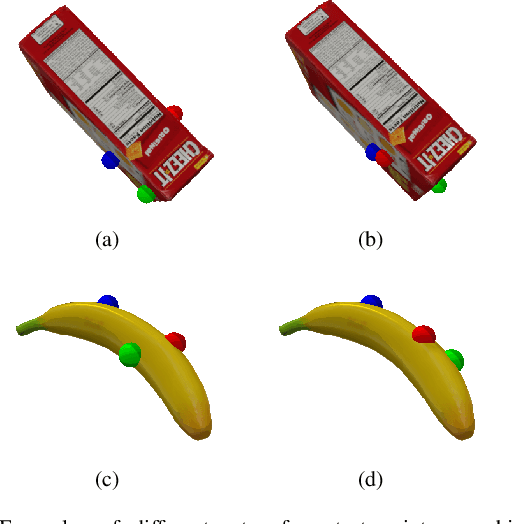


Autonomous grasping of novel objects that are previously unseen to a robot is an ongoing challenge in robotic manipulation. In the last decades, many approaches have been presented to address this problem for specific robot hands. The UniGrasp framework, introduced recently, has the ability to generalize to different types of robotic grippers; however, this method does not work on grippers with closed-loop constraints and is data-inefficient when applied to robot hands with multigrasp configurations. In this paper, we present EfficientGrasp, a generalized grasp synthesis and gripper control method that is independent of gripper model specifications. EfficientGrasp utilizes a gripper workspace feature rather than UniGrasp's gripper attribute inputs. This reduces memory use by 81.7% during training and makes it possible to generalize to more types of grippers, such as grippers with closed-loop constraints. The effectiveness of EfficientGrasp is evaluated by conducting object grasping experiments both in simulation and real-world; results show that the proposed method also outperforms UniGrasp when considering only grippers without closed-loop constraints. In these cases, EfficientGrasp shows 9.85% higher accuracy in generating contact points and 3.10% higher grasping success rate in simulation. The real-world experiments are conducted with a gripper with closed-loop constraints, which UniGrasp fails to handle while EfficientGrasp achieves a success rate of 83.3%. The main causes of grasping failures of the proposed method are analyzed, highlighting ways of enhancing grasp performance.