 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
Reviving DSP for Advanced Theorem Proving in the Era of Reasoning Models
Jun 13, 2025Recent advancements, such as DeepSeek-Prover-V2-671B and Kimina-Prover-Preview-72B, demonstrate a prevailing trend in leveraging reinforcement learning (RL)-based large-scale training for automated theorem proving. Surprisingly, we discover that even without any training, careful neuro-symbolic coordination of existing off-the-shelf reasoning models and tactic step provers can achieve comparable performance. This paper introduces \textbf{DSP+}, an improved version of the Draft, Sketch, and Prove framework, featuring a \emph{fine-grained and integrated} neuro-symbolic enhancement for each phase: (1) In the draft phase, we prompt reasoning models to generate concise natural-language subgoals to benefit the sketch phase, removing thinking tokens and references to human-written proofs; (2) In the sketch phase, subgoals are autoformalized with hypotheses to benefit the proving phase, and sketch lines containing syntactic errors are masked according to predefined rules; (3) In the proving phase, we tightly integrate symbolic search methods like Aesop with step provers to establish proofs for the sketch subgoals. Experimental results show that, without any additional model training or fine-tuning, DSP+ solves 80.7\%, 32.8\%, and 24 out of 644 problems from miniF2F, ProofNet, and PutnamBench, respectively, while requiring fewer budgets compared to state-of-the-arts. DSP+ proves \texttt{imo\_2019\_p1}, an IMO problem in miniF2F that is not solved by any prior work. Additionally, DSP+ generates proof patterns comprehensible by human experts, facilitating the identification of formalization errors; For example, eight wrongly formalized statements in miniF2F are discovered. Our results highlight the potential of classical reasoning patterns besides the RL-based training. All components will be open-sourced.
CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs
Dec 27, 2024



Computer-aided design (CAD) significantly enhances the efficiency, accuracy, and innovation of design processes by enabling precise 2D and 3D modeling, extensive analysis, and optimization. Existing methods for creating CAD models rely on latent vectors or point clouds, which are difficult to obtain and costly to store. Recent advances in Multimodal Large Language Models (MLLMs) have inspired researchers to use natural language instructions and images for CAD model construction. However, these models still struggle with inferring accurate 3D spatial location and orientation, leading to inaccuracies in determining the spatial 3D starting points and extrusion directions for constructing geometries. This work introduces CAD-GPT, a CAD synthesis method with spatial reasoning-enhanced MLLM that takes either a single image or a textual description as input. To achieve precise spatial inference, our approach introduces a 3D Modeling Spatial Mechanism. This method maps 3D spatial positions and 3D sketch plane rotation angles into a 1D linguistic feature space using a specialized spatial unfolding mechanism, while discretizing 2D sketch coordinates into an appropriate planar space to enable precise determination of spatial starting position, sketch orientation, and 2D sketch coordinate translations. Extensive experiments demonstrate that CAD-GPT consistently outperforms existing state-of-the-art methods in CAD model synthesis, both quantitatively and qualitatively.
SAIL: Sample-Centric In-Context Learning for Document Information Extraction
Dec 22, 2024Document Information Extraction (DIE) aims to extract structured information from Visually Rich Documents (VRDs). Previous full-training approaches have demonstrated strong performance but may struggle with generalization to unseen data. In contrast, training-free methods leverage powerful pre-trained models like Large Language Models (LLMs) to address various downstream tasks with only a few examples. Nonetheless, training-free methods for DIE encounter two primary challenges: (1) understanding the complex relationship between layout and textual elements in VRDs, and (2) providing accurate guidance to pre-trained models. To address these challenges, we propose Sample-centric In-context Learning (SAIL) for DIE. SAIL introduces a fine-grained entity-level textual similarity to facilitate in-depth text analysis by LLMs and incorporates layout similarity to enhance the analysis of layouts in VRDs. Additionally, SAIL formulates a unified In-Context Learning (ICL) prompt template for various sample-centric examples, enabling tailored prompts that deliver precise guidance to pre-trained models for each sample. Extensive experiments on FUNSD, CORD, and SROIE benchmarks with various base models (e.g., LLMs) indicate that our method outperforms training-free baselines, even closer to the full-training methods. The results show the superiority and generalization of our method.
GTA: A Benchmark for General Tool Agents
Jul 11, 2024



Significant focus has been placed on integrating large language models (LLMs) with various tools in developing general-purpose agents. This poses a challenge to LLMs' tool-use capabilities. However, there are evident gaps between existing tool-use evaluations and real-world scenarios. Current evaluations often use AI-generated queries, single-step tasks, dummy tools, and text-only interactions, failing to reveal the agents' real-world problem-solving abilities effectively. To address this, we propose GTA, a benchmark for General Tool Agents, featuring three main aspects: (i) Real user queries: human-written queries with simple real-world objectives but implicit tool-use, requiring the LLM to reason the suitable tools and plan the solution steps. (ii) Real deployed tools: an evaluation platform equipped with tools across perception, operation, logic, and creativity categories to evaluate the agents' actual task execution performance. (iii) Real multimodal inputs: authentic image files, such as spatial scenes, web page screenshots, tables, code snippets, and printed/handwritten materials, used as the query contexts to align with real-world scenarios closely. We design 229 real-world tasks and executable tool chains to evaluate mainstream LLMs. Our findings show that real-world user queries are challenging for existing LLMs, with GPT-4 completing less than 50% of the tasks and most LLMs achieving below 25%. This evaluation reveals the bottlenecks in the tool-use capabilities of current LLMs in real-world scenarios, which provides future direction for advancing general-purpose tool agents. The code and dataset are available at https://github.com/open-compass/GTA.
ADTR: Anomaly Detection Transformer with Feature Reconstruction
Sep 05, 2022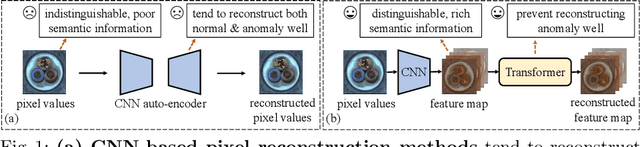
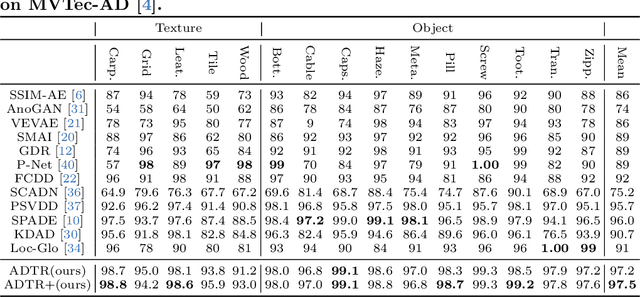
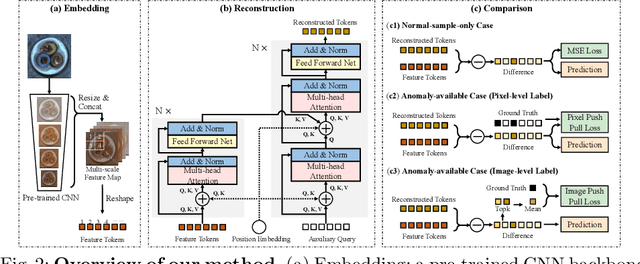
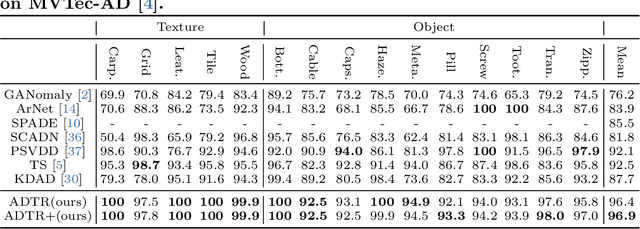
Anomaly detection with only prior knowledge from normal samples attracts more attention because of the lack of anomaly samples. Existing CNN-based pixel reconstruction approaches suffer from two concerns. First, the reconstruction source and target are raw pixel values that contain indistinguishable semantic information. Second, CNN tends to reconstruct both normal samples and anomalies well, making them still hard to distinguish. In this paper, we propose Anomaly Detection TRansformer (ADTR) to apply a transformer to reconstruct pre-trained features. The pre-trained features contain distinguishable semantic information. Also, the adoption of transformer limits to reconstruct anomalies well such that anomalies could be detected easily once the reconstruction fails. Moreover, we propose novel loss functions to make our approach compatible with the normal-sample-only case and the anomaly-available case with both image-level and pixel-level labeled anomalies. The performance could be further improved by adding simple synthetic or external irrelevant anomalies. Extensive experiments are conducted on anomaly detection datasets including MVTec-AD and CIFAR-10. Our method achieves superior performance compared with all baselines.
A Unified Model for Multi-class Anomaly Detection
Jun 08, 2022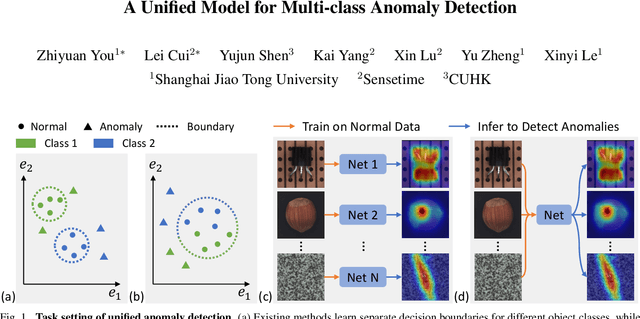
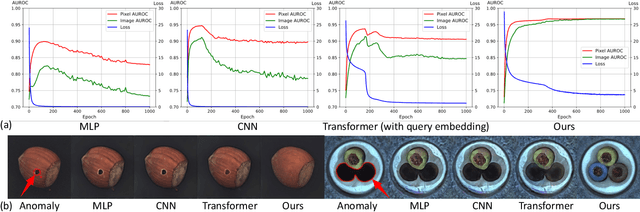

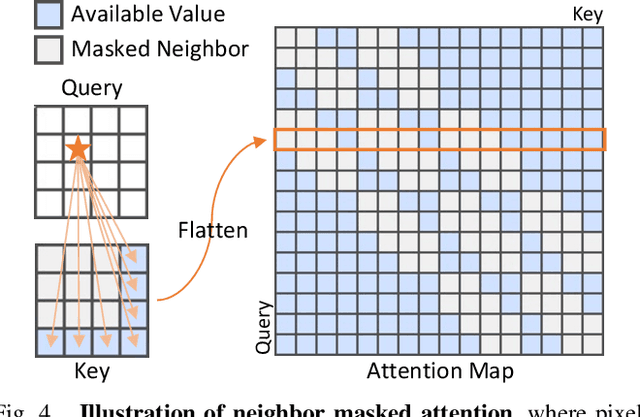
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an "identical shortcut", where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%). Code will be made publicly available.
The Z-axis, X-axis, Weight and Disambiguation Methods for Constructing Local Reference Frame in 3D Registration: An Evaluation
Apr 17, 2022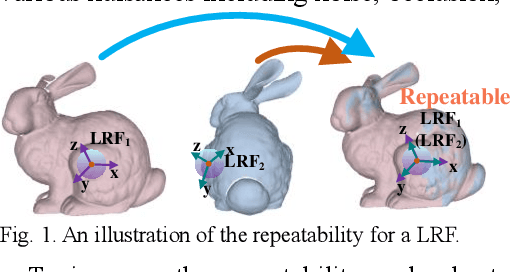
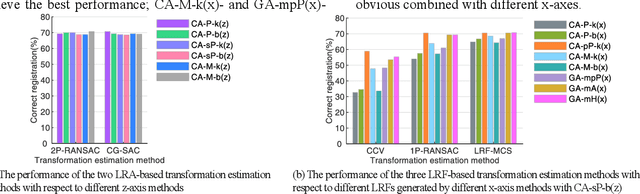
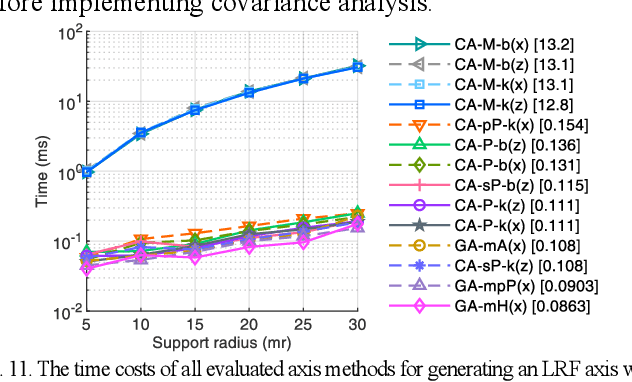
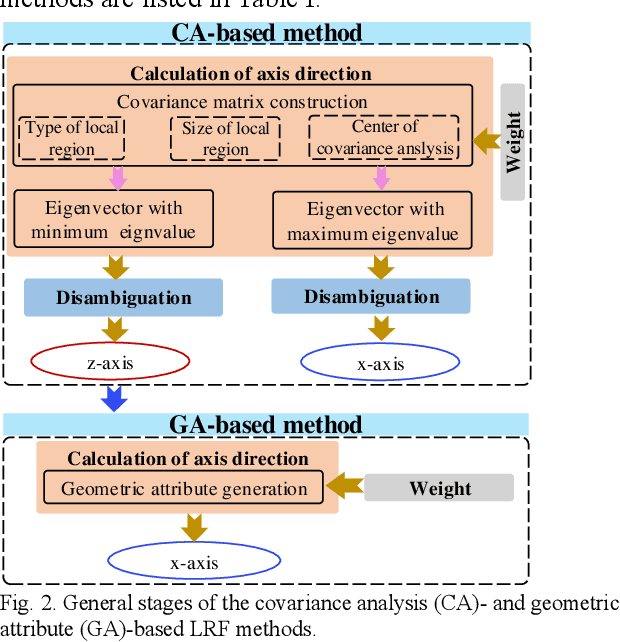
The local reference frame (LRF), as an independent coordinate system generated on a local 3D surface, is widely used in 3D local feature descriptor construction and 3D transformation estimation which are two key steps in the local method-based surface matching. There are numerous LRF methods have been proposed in literatures. In these methods, the x- and z-axis are commonly generated by different methods or strategies, and some x-axis methods are implemented on the basis of a z-axis being given. In addition, the weight and disambiguation methods are commonly used in these LRF methods. In existing evaluations of LRF, each LRF method is evaluated with a complete form. However, the merits and demerits of the z-axis, x-axis, weight and disambiguation methods in LRF construction are unclear. In this paper, we comprehensively analyze the z-axis, x-axis, weight and disambiguation methods in existing LRFs, and obtain six z-axis and eight x-axis, five weight and two disambiguation methods. The performance of these methods are comprehensively evaluated on six standard datasets with different application scenarios and nuisances. Considering the evaluation outcomes, the merits and demerits of different weight, disambiguation, z- and x-axis methods are analyzed and summarized. The experimental result also shows that some new designed LRF axes present superior performance compared with the state-of-the-art ones.
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Mar 14, 2022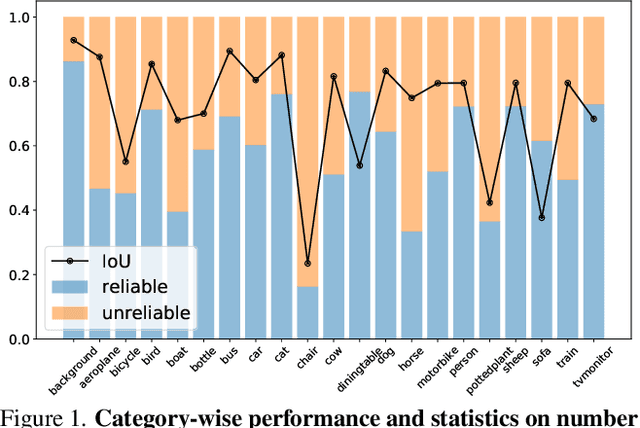
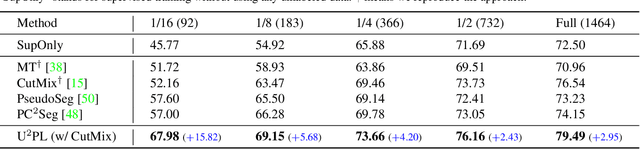
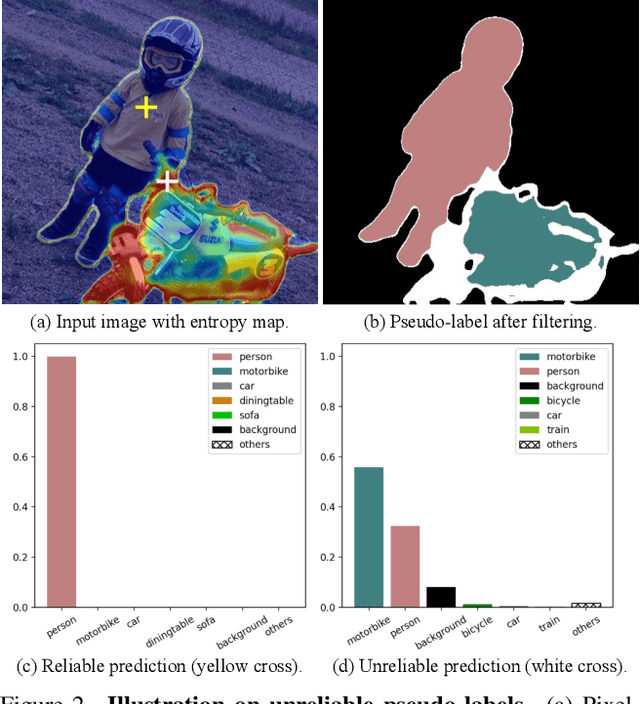
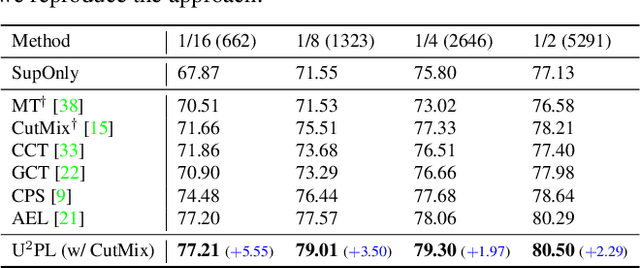
The crux of semi-supervised semantic segmentation is to assign adequate pseudo-labels to the pixels of unlabeled images. A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability. We argue that every pixel matters to the model training, even its prediction is ambiguous. Intuitively, an unreliable prediction may get confused among the top classes (i.e., those with the highest probabilities), however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative sample to those most unlikely categories. Based on this insight, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative samples, and manage to train the model with all candidate pixels. Considering the training evolution, where the prediction becomes more and more accurate, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.
Iterative Correlation-based Feature Refinement for Few-shot Counting
Jan 22, 2022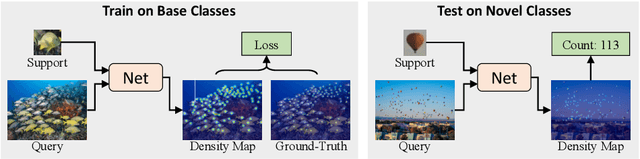

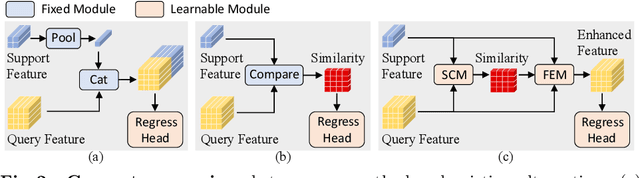
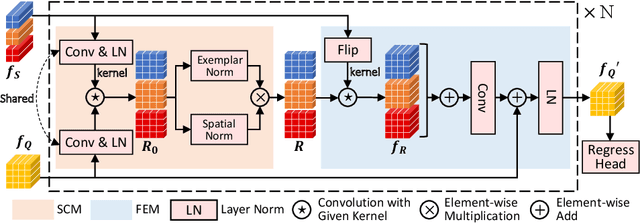
Few-shot counting aims to count objects of any class in an image given only a few exemplars of the same class. Existing correlation-based few-shot counting approaches suffer from the coarseness and low semantic level of the correlation. To solve these problems, we propose an iterative framework to progressively refine the exemplar-related features based on the correlation between the image and exemplars. Then the density map is predicted from the final refined feature map. The iterative framework includes a Correlation Distillation module and a Feature Refinement module. During the iterations, the exemplar-related features are gradually refined, while the exemplar-unrelated features are suppressed, benefiting few-shot counting where the exemplar-related features are more important. Our approach surpasses all baselines significantly on few-shot counting benchmark FSC-147. Surprisingly, though designed for general class-agnostic counting, our approach still achieves state-of-the-art performance on car counting benchmarks CARPK and PUCPR+, and crowd counting benchmarks UCSD and Mall. We also achieve competitive performance on crowd counting benchmark ShanghaiTech. The code will be released soon.