 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVD-GS: Gaussian Splatting SLAM for Dynamic Scenes via Hierarchical Explicit-Implicit Representation Collaboration Rendering
Oct 26, 20253D Gaussian Splatting SLAM has emerged as a widely used technique for high-fidelity mapping in spatial intelligence. However, existing methods often rely on a single representation scheme, which limits their performance in large-scale dynamic outdoor scenes and leads to cumulative pose errors and scale ambiguity. To address these challenges, we propose \textbf{LVD-GS}, a novel LiDAR-Visual 3D Gaussian Splatting SLAM system. Motivated by the human chain-of-thought process for information seeking, we introduce a hierarchical collaborative representation module that facilitates mutual reinforcement for mapping optimization, effectively mitigating scale drift and enhancing reconstruction robustness. Furthermore, to effectively eliminate the influence of dynamic objects, we propose a joint dynamic modeling module that generates fine-grained dynamic masks by fusing open-world segmentation with implicit residual constraints, guided by uncertainty estimates from DINO-Depth features. Extensive evaluations on KITTI, nuScenes, and self-collected datasets demonstrate that our approach achieves state-of-the-art performance compared to existing methods.
CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs
Dec 27, 2024



Computer-aided design (CAD) significantly enhances the efficiency, accuracy, and innovation of design processes by enabling precise 2D and 3D modeling, extensive analysis, and optimization. Existing methods for creating CAD models rely on latent vectors or point clouds, which are difficult to obtain and costly to store. Recent advances in Multimodal Large Language Models (MLLMs) have inspired researchers to use natural language instructions and images for CAD model construction. However, these models still struggle with inferring accurate 3D spatial location and orientation, leading to inaccuracies in determining the spatial 3D starting points and extrusion directions for constructing geometries. This work introduces CAD-GPT, a CAD synthesis method with spatial reasoning-enhanced MLLM that takes either a single image or a textual description as input. To achieve precise spatial inference, our approach introduces a 3D Modeling Spatial Mechanism. This method maps 3D spatial positions and 3D sketch plane rotation angles into a 1D linguistic feature space using a specialized spatial unfolding mechanism, while discretizing 2D sketch coordinates into an appropriate planar space to enable precise determination of spatial starting position, sketch orientation, and 2D sketch coordinate translations. Extensive experiments demonstrate that CAD-GPT consistently outperforms existing state-of-the-art methods in CAD model synthesis, both quantitatively and qualitatively.
CANS: Communication Limited Camera Network Self-Configuration for Intelligent Industrial Surveillance
Sep 13, 2021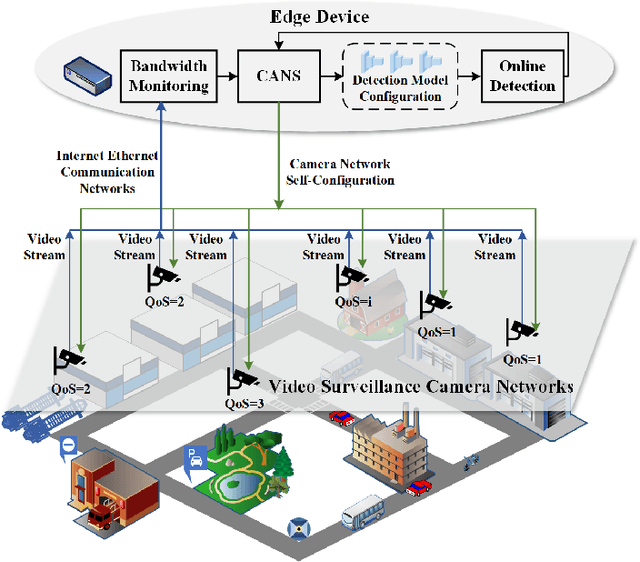
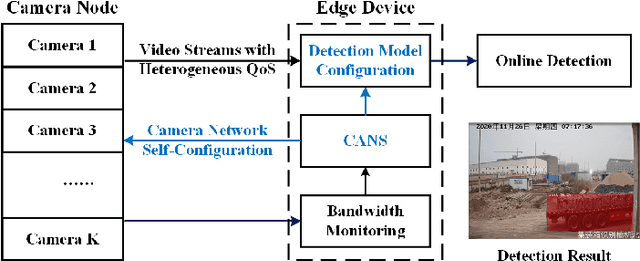

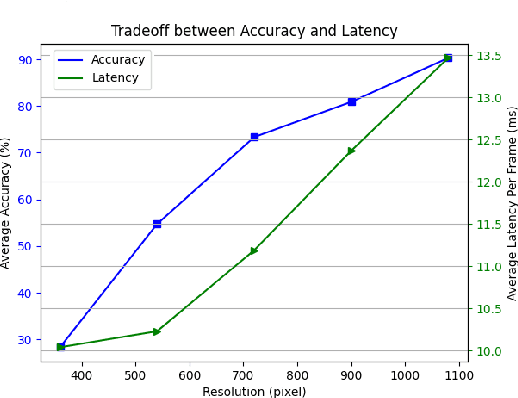
Realtime and intelligent video surveillance via camera networks involve computation-intensive vision detection tasks with massive video data, which is crucial for safety in the edge-enabled industrial Internet of Things (IIoT). Multiple video streams compete for limited communication resources on the link between edge devices and camera networks, resulting in considerable communication congestion. It postpones the completion time and degrades the accuracy of vision detection tasks. Thus, achieving high accuracy of vision detection tasks under the communication constraints and vision task deadline constraints is challenging. Previous works focus on single camera configuration to balance the tradeoff between accuracy and processing time of detection tasks by setting video quality parameters. In this paper, an adaptive camera network self-configuration method (CANS) of video surveillance is proposed to cope with multiple video streams of heterogeneous quality of service (QoS) demands for edge-enabled IIoT. Moreover, it adapts to video content and network dynamics. Specifically, the tradeoff between two key performance metrics, \emph{i.e.,} accuracy and latency, is formulated as an NP-hard optimization problem with latency constraints. Simulation on real-world surveillance datasets demonstrates that the proposed CANS method achieves low end-to-end latency (13 ms on average) with high accuracy (92\% on average) with network dynamics. The results validate the effectiveness of the CANS.