 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
Jan 20, 2026Writing effective rebuttals is a high-stakes task that demands more than linguistic fluency, as it requires precise alignment between reviewer intent and manuscript details. Current solutions typically treat this as a direct-to-text generation problem, suffering from hallucination, overlooked critiques, and a lack of verifiable grounding. To address these limitations, we introduce $\textbf{RebuttalAgent}$, the first multi-agents framework that reframes rebuttal generation as an evidence-centric planning task. Our system decomposes complex feedback into atomic concerns and dynamically constructs hybrid contexts by synthesizing compressed summaries with high-fidelity text while integrating an autonomous and on-demand external search module to resolve concerns requiring outside literature. By generating an inspectable response plan before drafting, $\textbf{RebuttalAgent}$ ensures that every argument is explicitly anchored in internal or external evidence. We validate our approach on the proposed $\textbf{RebuttalBench}$ and demonstrate that our pipeline outperforms strong baselines in coverage, faithfulness, and strategic coherence, offering a transparent and controllable assistant for the peer review process. Code will be released.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Effective Attention-Guided Multi-Scale Medical Network for Skin Lesion Segmentation
Dec 08, 2025In the field of healthcare, precise skin lesion segmentation is crucial for the early detection and accurate diagnosis of skin diseases. Despite significant advances in deep learning for image processing, existing methods have yet to effectively address the challenges of irregular lesion shapes and low contrast. To address these issues, this paper proposes an innovative encoder-decoder network architecture based on multi-scale residual structures, capable of extracting rich feature information from different receptive fields to effectively identify lesion areas. By introducing a Multi-Resolution Multi-Channel Fusion (MRCF) module, our method captures cross-scale features, enhancing the clarity and accuracy of the extracted information. Furthermore, we propose a Cross-Mix Attention Module (CMAM), which redefines the attention scope and dynamically calculates weights across multiple contexts, thus improving the flexibility and depth of feature capture and enabling deeper exploration of subtle features. To overcome the information loss caused by skip connections in traditional U-Net, an External Attention Bridge (EAB) is introduced, facilitating the effective utilization of information in the decoder and compensating for the loss during upsampling. Extensive experimental evaluations on several skin lesion segmentation datasets demonstrate that the proposed model significantly outperforms existing transformer and convolutional neural network-based models, showcasing exceptional segmentation accuracy and robustness.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Apr 02, 2025The exponential growth of online content has posed significant challenges to ID-based models in industrial recommendation systems, ranging from extremely high cardinality and dynamically growing ID space, to highly skewed engagement distributions, to prediction instability as a result of natural id life cycles (e.g, the birth of new IDs and retirement of old IDs). To address these issues, many systems rely on random hashing to handle the id space and control the corresponding model parameters (i.e embedding table). However, this approach introduces data pollution from multiple ids sharing the same embedding, leading to degraded model performance and embedding representation instability. This paper examines these challenges and introduces Semantic ID prefix ngram, a novel token parameterization technique that significantly improves the performance of the original Semantic ID. Semantic ID prefix ngram creates semantically meaningful collisions by hierarchically clustering items based on their content embeddings, as opposed to random assignments. Through extensive experimentation, we demonstrate that Semantic ID prefix ngram not only addresses embedding instability but also significantly improves tail id modeling, reduces overfitting, and mitigates representation shifts. We further highlight the advantages of Semantic ID prefix ngram in attention-based models that contextualize user histories, showing substantial performance improvements. We also report our experience of integrating Semantic ID into Meta production Ads Ranking system, leading to notable performance gains and enhanced prediction stability in live deployments.
Policy-Guided Causal State Representation for Offline Reinforcement Learning Recommendation
Feb 04, 2025



In offline reinforcement learning-based recommender systems (RLRS), learning effective state representations is crucial for capturing user preferences that directly impact long-term rewards. However, raw state representations often contain high-dimensional, noisy information and components that are not causally relevant to the reward. Additionally, missing transitions in offline data make it challenging to accurately identify features that are most relevant to user satisfaction. To address these challenges, we propose Policy-Guided Causal Representation (PGCR), a novel two-stage framework for causal feature selection and state representation learning in offline RLRS. In the first stage, we learn a causal feature selection policy that generates modified states by isolating and retaining only the causally relevant components (CRCs) while altering irrelevant components. This policy is guided by a reward function based on the Wasserstein distance, which measures the causal effect of state components on the reward and encourages the preservation of CRCs that directly influence user interests. In the second stage, we train an encoder to learn compact state representations by minimizing the mean squared error (MSE) loss between the latent representations of the original and modified states, ensuring that the representations focus on CRCs. We provide a theoretical analysis proving the identifiability of causal effects from interventions, validating the ability of PGCR to isolate critical state components for decision-making. Extensive experiments demonstrate that PGCR significantly improves recommendation performance, confirming its effectiveness for offline RL-based recommender systems.
CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs
Dec 27, 2024



Computer-aided design (CAD) significantly enhances the efficiency, accuracy, and innovation of design processes by enabling precise 2D and 3D modeling, extensive analysis, and optimization. Existing methods for creating CAD models rely on latent vectors or point clouds, which are difficult to obtain and costly to store. Recent advances in Multimodal Large Language Models (MLLMs) have inspired researchers to use natural language instructions and images for CAD model construction. However, these models still struggle with inferring accurate 3D spatial location and orientation, leading to inaccuracies in determining the spatial 3D starting points and extrusion directions for constructing geometries. This work introduces CAD-GPT, a CAD synthesis method with spatial reasoning-enhanced MLLM that takes either a single image or a textual description as input. To achieve precise spatial inference, our approach introduces a 3D Modeling Spatial Mechanism. This method maps 3D spatial positions and 3D sketch plane rotation angles into a 1D linguistic feature space using a specialized spatial unfolding mechanism, while discretizing 2D sketch coordinates into an appropriate planar space to enable precise determination of spatial starting position, sketch orientation, and 2D sketch coordinate translations. Extensive experiments demonstrate that CAD-GPT consistently outperforms existing state-of-the-art methods in CAD model synthesis, both quantitatively and qualitatively.
Action-Attentive Deep Reinforcement Learning for Autonomous Alignment of Beamlines
Nov 19, 2024Synchrotron radiation sources play a crucial role in fields such as materials science, biology, and chemistry. The beamline, a key subsystem of the synchrotron, modulates and directs the radiation to the sample for analysis. However, the alignment of beamlines is a complex and time-consuming process, primarily carried out manually by experienced engineers. Even minor misalignments in optical components can significantly affect the beam's properties, leading to suboptimal experimental outcomes. Current automated methods, such as bayesian optimization (BO) and reinforcement learning (RL), although these methods enhance performance, limitations remain. The relationship between the current and target beam properties, crucial for determining the adjustment, is not fully considered. Additionally, the physical characteristics of optical elements are overlooked, such as the need to adjust specific devices to control the output beam's spot size or position. This paper addresses the alignment of beamlines by modeling it as a Markov Decision Process (MDP) and training an intelligent agent using RL. The agent calculates adjustment values based on the current and target beam states, executes actions, and iterates until optimal parameters are achieved. A policy network with action attention is designed to improve decision-making by considering both state differences and the impact of optical components. Experiments on two simulated beamlines demonstrate that our algorithm outperforms existing methods, with ablation studies highlighting the effectiveness of the action attention-based policy network.
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.
FoLDTree: A ULDA-Based Decision Tree Framework for Efficient Oblique Splits and Feature Selection
Oct 30, 2024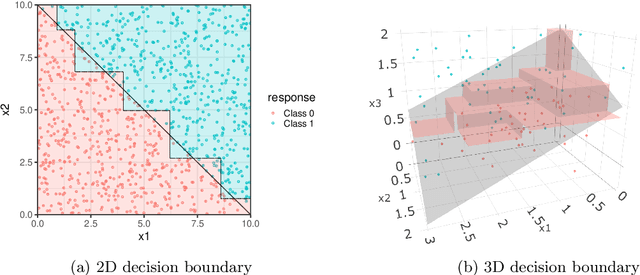

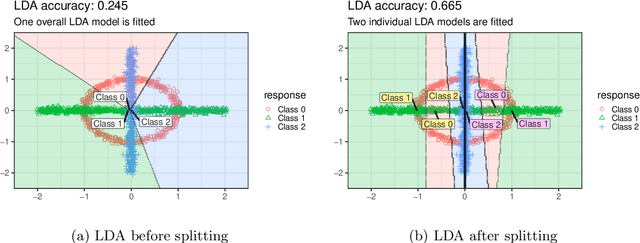

Traditional decision trees are limited by axis-orthogonal splits, which can perform poorly when true decision boundaries are oblique. While oblique decision tree methods address this limitation, they often face high computational costs, difficulties with multi-class classification, and a lack of effective feature selection. In this paper, we introduce LDATree and FoLDTree, two novel frameworks that integrate Uncorrelated Linear Discriminant Analysis (ULDA) and Forward ULDA into a decision tree structure. These methods enable efficient oblique splits, handle missing values, support feature selection, and provide both class labels and probabilities as model outputs. Through evaluations on simulated and real-world datasets, LDATree and FoLDTree consistently outperform axis-orthogonal and other oblique decision tree methods, achieving accuracy levels comparable to the random forest. The results highlight the potential of these frameworks as robust alternatives to traditional single-tree methods.