 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Guided Causal State Representation for Offline Reinforcement Learning Recommendation
Feb 04, 2025



In offline reinforcement learning-based recommender systems (RLRS), learning effective state representations is crucial for capturing user preferences that directly impact long-term rewards. However, raw state representations often contain high-dimensional, noisy information and components that are not causally relevant to the reward. Additionally, missing transitions in offline data make it challenging to accurately identify features that are most relevant to user satisfaction. To address these challenges, we propose Policy-Guided Causal Representation (PGCR), a novel two-stage framework for causal feature selection and state representation learning in offline RLRS. In the first stage, we learn a causal feature selection policy that generates modified states by isolating and retaining only the causally relevant components (CRCs) while altering irrelevant components. This policy is guided by a reward function based on the Wasserstein distance, which measures the causal effect of state components on the reward and encourages the preservation of CRCs that directly influence user interests. In the second stage, we train an encoder to learn compact state representations by minimizing the mean squared error (MSE) loss between the latent representations of the original and modified states, ensuring that the representations focus on CRCs. We provide a theoretical analysis proving the identifiability of causal effects from interventions, validating the ability of PGCR to isolate critical state components for decision-making. Extensive experiments demonstrate that PGCR significantly improves recommendation performance, confirming its effectiveness for offline RL-based recommender systems.
On Causally Disentangled State Representation Learning for Reinforcement Learning based Recommender Systems
Jul 18, 2024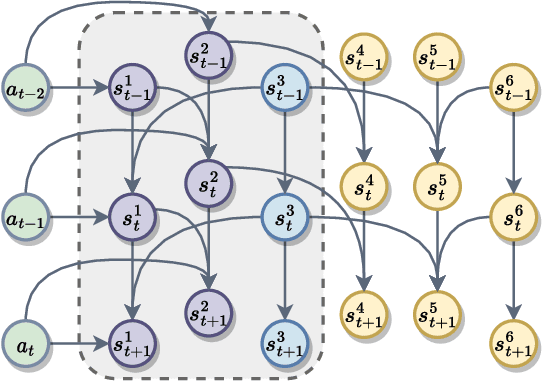
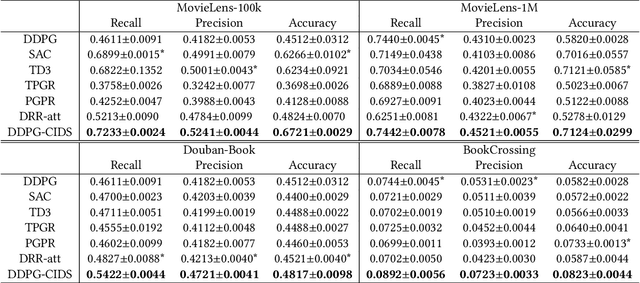
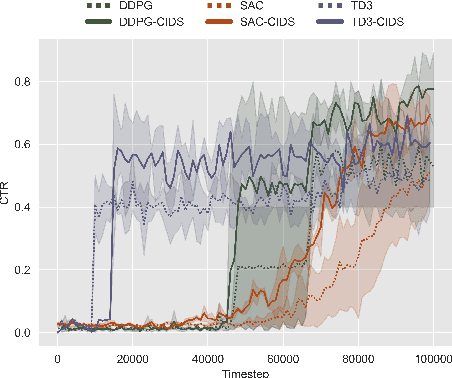

In Reinforcement Learning-based Recommender Systems (RLRS), the complexity and dynamism of user interactions often result in high-dimensional and noisy state spaces, making it challenging to discern which aspects of the state are truly influential in driving the decision-making process. This issue is exacerbated by the evolving nature of user preferences and behaviors, requiring the recommender system to adaptively focus on the most relevant information for decision-making while preserving generaliability. To tackle this problem, we introduce an innovative causal approach for decomposing the state and extracting \textbf{C}ausal-\textbf{I}n\textbf{D}ispensable \textbf{S}tate Representations (CIDS) in RLRS. Our method concentrates on identifying the \textbf{D}irectly \textbf{A}ction-\textbf{I}nfluenced \textbf{S}tate Variables (DAIS) and \textbf{A}ction-\textbf{I}nfluence \textbf{A}ncestors (AIA), which are essential for making effective recommendations. By leveraging conditional mutual information, we develop a framework that not only discerns the causal relationships within the generative process but also isolates critical state variables from the typically dense and high-dimensional state representations. We provide theoretical evidence for the identifiability of these variables. Then, by making use of the identified causal relationship, we construct causal-indispensable state representations, enabling the training of policies over a more advantageous subset of the agent's state space. We demonstrate the efficacy of our approach through extensive experiments, showcasing our method outperforms state-of-the-art methods.
Maximum-Entropy Regularized Decision Transformer with Reward Relabelling for Dynamic Recommendation
Jun 02, 2024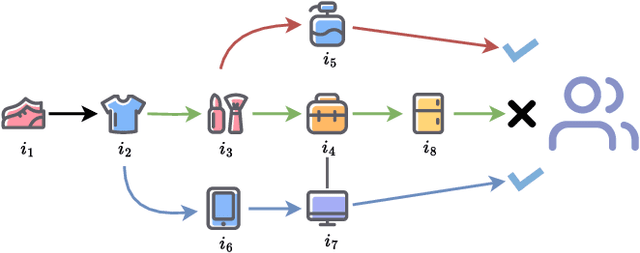
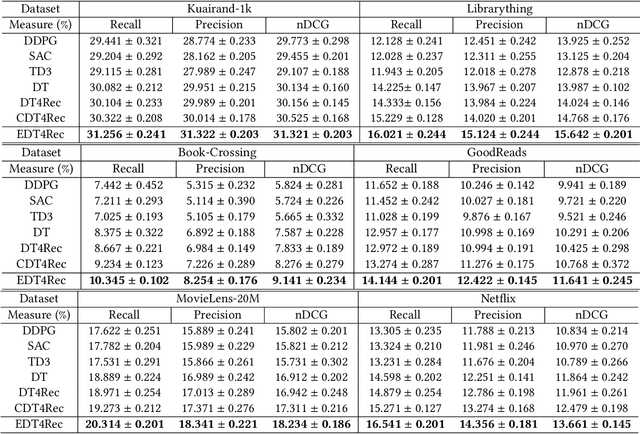
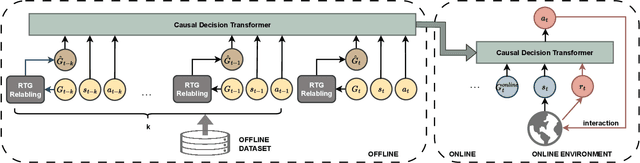
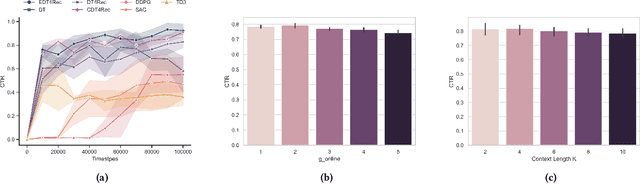
Reinforcement learning-based recommender systems have recently gained popularity. However, due to the typical limitations of simulation environments (e.g., data inefficiency), most of the work cannot be broadly applied in all domains. To counter these challenges, recent advancements have leveraged offline reinforcement learning methods, notable for their data-driven approach utilizing offline datasets. A prominent example of this is the Decision Transformer. Despite its popularity, the Decision Transformer approach has inherent drawbacks, particularly evident in recommendation methods based on it. This paper identifies two key shortcomings in existing Decision Transformer-based methods: a lack of stitching capability and limited effectiveness in online adoption. In response, we introduce a novel methodology named Max-Entropy enhanced Decision Transformer with Reward Relabeling for Offline RLRS (EDT4Rec). Our approach begins with a max entropy perspective, leading to the development of a max entropy enhanced exploration strategy. This strategy is designed to facilitate more effective exploration in online environments. Additionally, to augment the model's capability to stitch sub-optimal trajectories, we incorporate a unique reward relabeling technique. To validate the effectiveness and superiority of EDT4Rec, we have conducted comprehensive experiments across six real-world offline datasets and in an online simulator.
Retentive Decision Transformer with Adaptive Masking for Reinforcement Learning based Recommendation Systems
Mar 26, 2024



Reinforcement Learning-based Recommender Systems (RLRS) have shown promise across a spectrum of applications, from e-commerce platforms to streaming services. Yet, they grapple with challenges, notably in crafting reward functions and harnessing large pre-existing datasets within the RL framework. Recent advancements in offline RLRS provide a solution for how to address these two challenges. However, existing methods mainly rely on the transformer architecture, which, as sequence lengths increase, can introduce challenges associated with computational resources and training costs. Additionally, the prevalent methods employ fixed-length input trajectories, restricting their capacity to capture evolving user preferences. In this study, we introduce a new offline RLRS method to deal with the above problems. We reinterpret the RLRS challenge by modeling sequential decision-making as an inference task, leveraging adaptive masking configurations. This adaptive approach selectively masks input tokens, transforming the recommendation task into an inference challenge based on varying token subsets, thereby enhancing the agent's ability to infer across diverse trajectory lengths. Furthermore, we incorporate a multi-scale segmented retention mechanism that facilitates efficient modeling of long sequences, significantly enhancing computational efficiency. Our experimental analysis, conducted on both online simulator and offline datasets, clearly demonstrates the advantages of our proposed method.
Uncertainty-aware Distributional Offline Reinforcement Learning
Mar 26, 2024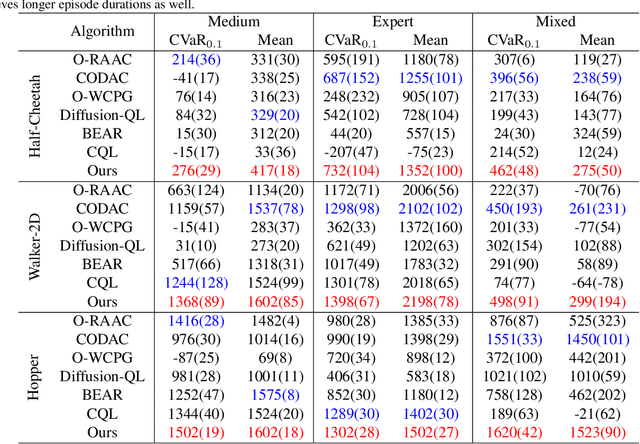
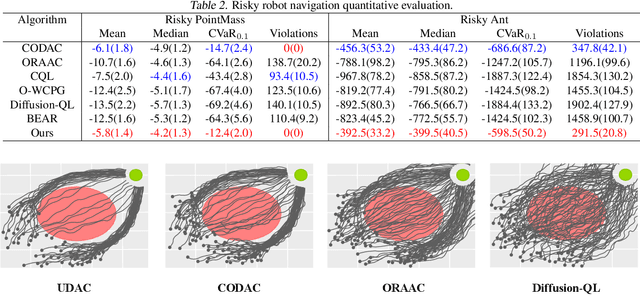
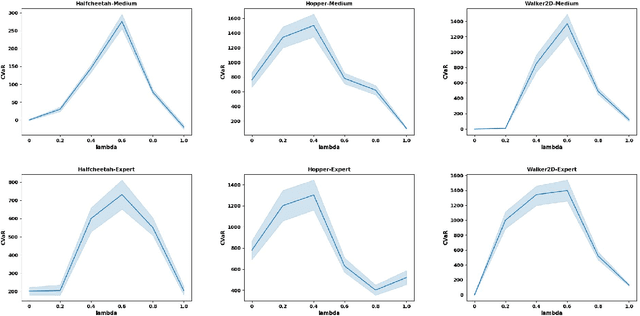
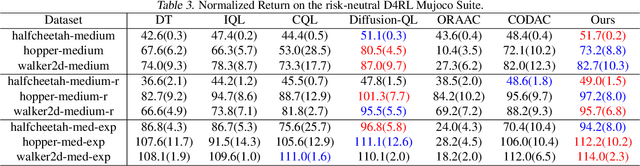
Offline reinforcement learning (RL) presents distinct challenges as it relies solely on observational data. A central concern in this context is ensuring the safety of the learned policy by quantifying uncertainties associated with various actions and environmental stochasticity. Traditional approaches primarily emphasize mitigating epistemic uncertainty by learning risk-averse policies, often overlooking environmental stochasticity. In this study, we propose an uncertainty-aware distributional offline RL method to simultaneously address both epistemic uncertainty and environmental stochasticity. We propose a model-free offline RL algorithm capable of learning risk-averse policies and characterizing the entire distribution of discounted cumulative rewards, as opposed to merely maximizing the expected value of accumulated discounted returns. Our method is rigorously evaluated through comprehensive experiments in both risk-sensitive and risk-neutral benchmarks, demonstrating its superior performance.
On the Opportunities and Challenges of Offline Reinforcement Learning for Recommender Systems
Aug 22, 2023

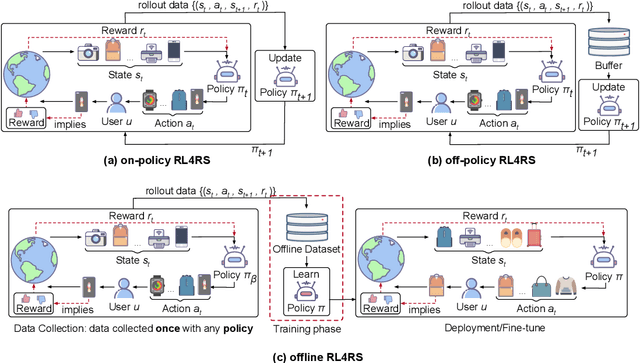
Reinforcement learning serves as a potent tool for modeling dynamic user interests within recommender systems, garnering increasing research attention of late. However, a significant drawback persists: its poor data efficiency, stemming from its interactive nature. The training of reinforcement learning-based recommender systems demands expensive online interactions to amass adequate trajectories, essential for agents to learn user preferences. This inefficiency renders reinforcement learning-based recommender systems a formidable undertaking, necessitating the exploration of potential solutions. Recent strides in offline reinforcement learning present a new perspective. Offline reinforcement learning empowers agents to glean insights from offline datasets and deploy learned policies in online settings. Given that recommender systems possess extensive offline datasets, the framework of offline reinforcement learning aligns seamlessly. Despite being a burgeoning field, works centered on recommender systems utilizing offline reinforcement learning remain limited. This survey aims to introduce and delve into offline reinforcement learning within recommender systems, offering an inclusive review of existing literature in this domain. Furthermore, we strive to underscore prevalent challenges, opportunities, and future pathways, poised to propel research in this evolving field.
Causal Decision Transformer for Recommender Systems via Offline Reinforcement Learning
Apr 17, 2023



Reinforcement learning-based recommender systems have recently gained popularity. However, the design of the reward function, on which the agent relies to optimize its recommendation policy, is often not straightforward. Exploring the causality underlying users' behavior can take the place of the reward function in guiding the agent to capture the dynamic interests of users. Moreover, due to the typical limitations of simulation environments (e.g., data inefficiency), most of the work cannot be broadly applied in large-scale situations. Although some works attempt to convert the offline dataset into a simulator, data inefficiency makes the learning process even slower. Because of the nature of reinforcement learning (i.e., learning by interaction), it cannot collect enough data to train during a single interaction. Furthermore, traditional reinforcement learning algorithms do not have a solid capability like supervised learning methods to learn from offline datasets directly. In this paper, we propose a new model named the causal decision transformer for recommender systems (CDT4Rec). CDT4Rec is an offline reinforcement learning system that can learn from a dataset rather than from online interaction. Moreover, CDT4Rec employs the transformer architecture, which is capable of processing large offline datasets and capturing both short-term and long-term dependencies within the data to estimate the causal relationship between action, state, and reward. To demonstrate the feasibility and superiority of our model, we have conducted experiments on six real-world offline datasets and one online simulator.
Causal Disentangled Variational Auto-Encoder for Preference Understanding in Recommendation
Apr 17, 2023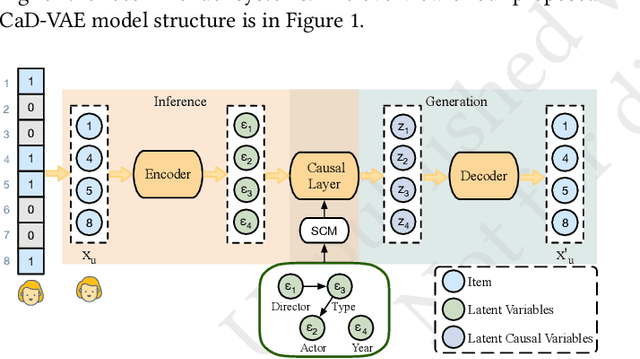
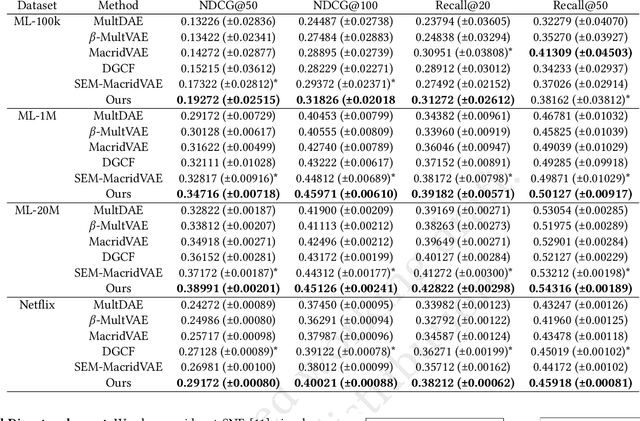
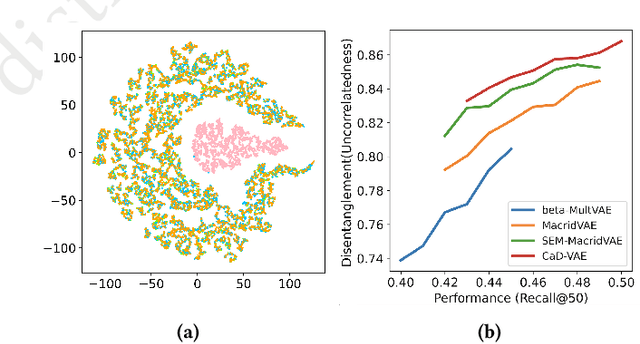
Recommendation models are typically trained on observational user interaction data, but the interactions between latent factors in users' decision-making processes lead to complex and entangled data. Disentangling these latent factors to uncover their underlying representation can improve the robustness, interpretability, and controllability of recommendation models. This paper introduces the Causal Disentangled Variational Auto-Encoder (CaD-VAE), a novel approach for learning causal disentangled representations from interaction data in recommender systems. The CaD-VAE method considers the causal relationships between semantically related factors in real-world recommendation scenarios, rather than enforcing independence as in existing disentanglement methods. The approach utilizes structural causal models to generate causal representations that describe the causal relationship between latent factors. The results demonstrate that CaD-VAE outperforms existing methods, offering a promising solution for disentangling complex user behavior data in recommendation systems.
Intrinsically Motivated Reinforcement Learning based Recommendation with Counterfactual Data Augmentation
Sep 17, 2022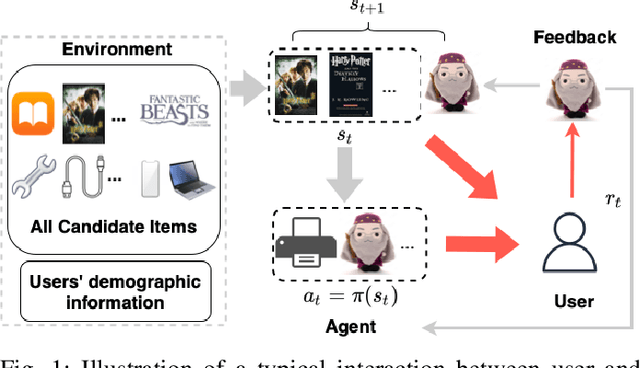
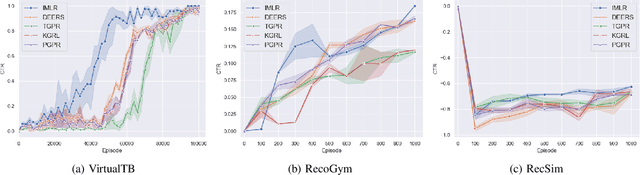
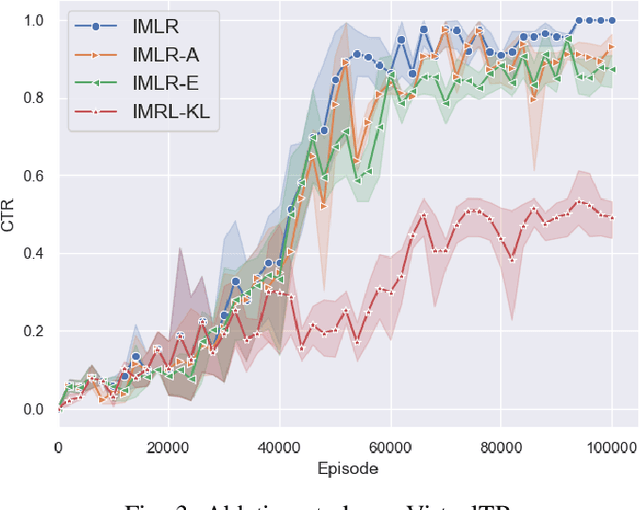
Deep reinforcement learning (DRL) has been proven its efficiency in capturing users' dynamic interests in recent literature. However, training a DRL agent is challenging, because of the sparse environment in recommender systems (RS), DRL agents could spend times either exploring informative user-item interaction trajectories or using existing trajectories for policy learning. It is also known as the exploration and exploitation trade-off which affects the recommendation performance significantly when the environment is sparse. It is more challenging to balance the exploration and exploitation in DRL RS where RS agent need to deeply explore the informative trajectories and exploit them efficiently in the context of recommender systems. As a step to address this issue, We design a novel intrinsically ,otivated reinforcement learning method to increase the capability of exploring informative interaction trajectories in the sparse environment, which are further enriched via a counterfactual augmentation strategy for more efficient exploitation. The extensive experiments on six offline datasets and three online simulation platforms demonstrate the superiority of our model to a set of existing state-of-the-art methods.
Interventional Recommendation with Contrastive Counterfactual Learning for Better Understanding User Preferences
Aug 13, 2022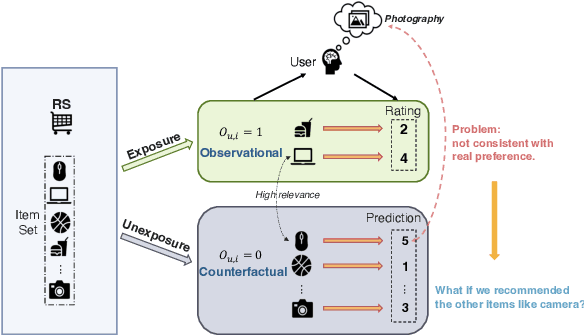
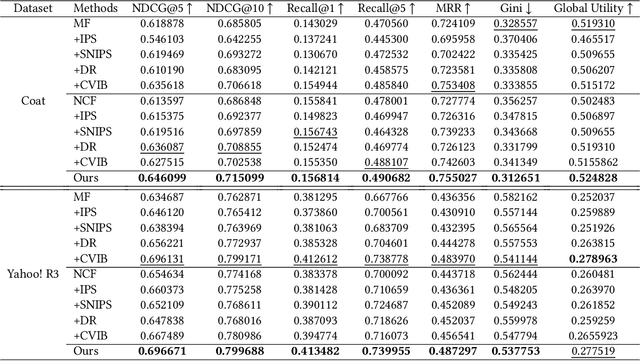
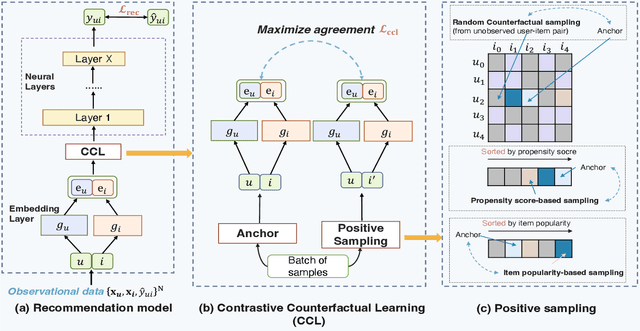
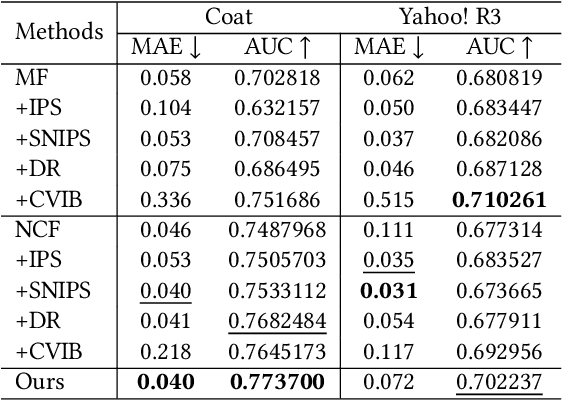
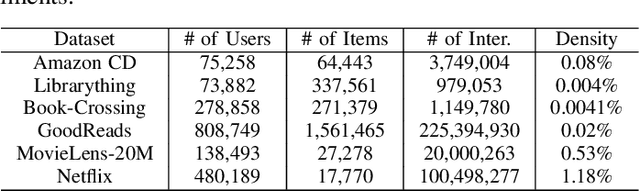
Recently, there has been a surging interest in formulating recommendations in the context of causal inference. The studies regard the recommendation as an intervention in causal inference and frame the users' preferences as interventional effects to improve recommender systems' generalization. Many studies in the field of causal inference for recommender systems have been focusing on utilizing propensity scores from the causal community that reduce the bias while inducing additional variance. Alternatively, some studies suggest the existence of a set of unbiased data from randomized controlled trials while it requires to satisfy certain assumptions that may be challenging in practice. In this paper, we first design a causal graph representing recommender systems' data generation and propagation process. Then, we reveal that the underlying exposure mechanism biases the maximum likelihood estimation (MLE) on observational feedback. In order to figure out users' preferences in terms of causality behind data, we leverage the back-door adjustment and do-calculus, which induces an interventional recommendation model (IREC). Furthermore, considering the confounder may be inaccessible for measurement, we propose a contrastive counterfactual learning method (CCL) for simulating the intervention. In addition, we present two extra novel sampling strategies and show an intriguing finding that sampling from counterfactual sets contributes to superior performance. We perform extensive experiments on two real-world datasets to evaluate and analyze the performance of our model IREC-CCL on unbiased test sets. Experimental results demonstrate our model outperforms the state-of-the-art methods.