 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Opportunities and Challenges of Offline Reinforcement Learning for Recommender Systems
Paper and Code
Aug 22, 2023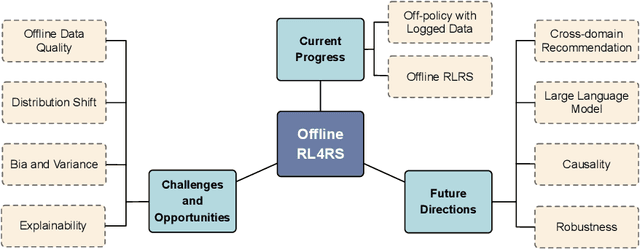

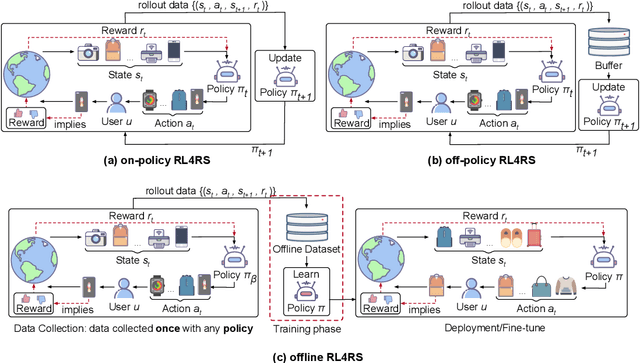
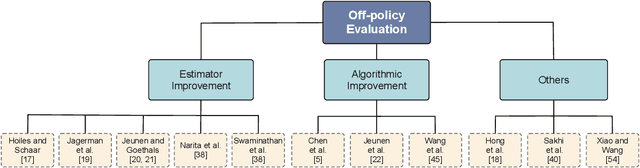
Reinforcement learning serves as a potent tool for modeling dynamic user interests within recommender systems, garnering increasing research attention of late. However, a significant drawback persists: its poor data efficiency, stemming from its interactive nature. The training of reinforcement learning-based recommender systems demands expensive online interactions to amass adequate trajectories, essential for agents to learn user preferences. This inefficiency renders reinforcement learning-based recommender systems a formidable undertaking, necessitating the exploration of potential solutions. Recent strides in offline reinforcement learning present a new perspective. Offline reinforcement learning empowers agents to glean insights from offline datasets and deploy learned policies in online settings. Given that recommender systems possess extensive offline datasets, the framework of offline reinforcement learning aligns seamlessly. Despite being a burgeoning field, works centered on recommender systems utilizing offline reinforcement learning remain limited. This survey aims to introduce and delve into offline reinforcement learning within recommender systems, offering an inclusive review of existing literature in this domain. Furthermore, we strive to underscore prevalent challenges, opportunities, and future pathways, poised to propel research in this evolving field.