 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023

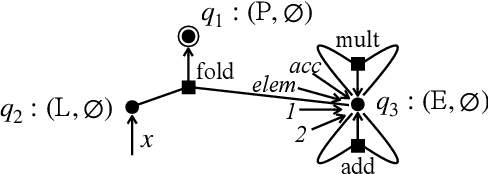
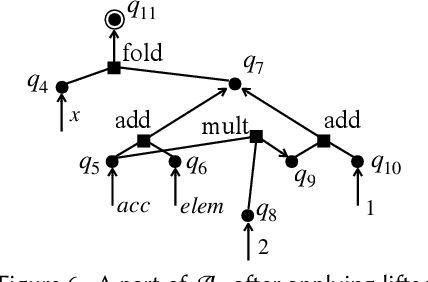
We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
Organized Event Participant Prediction Enhanced by Social Media Retweeting Data
Oct 02, 2023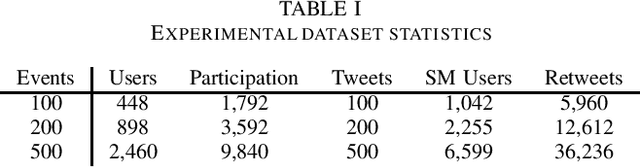
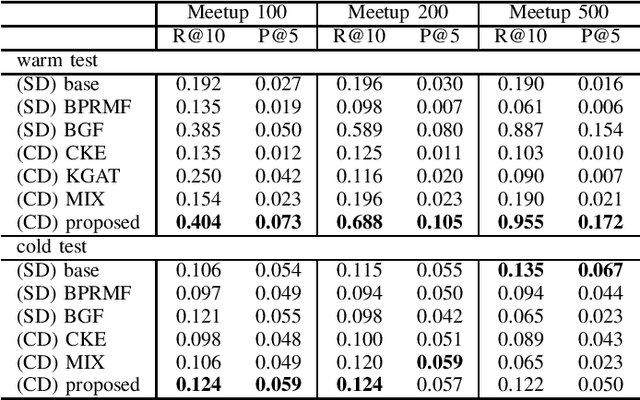
Nowadays, many platforms on the Web offer organized events, allowing users to be organizers or participants. For such platforms, it is beneficial to predict potential event participants. Existing work on this problem tends to borrow recommendation techniques. However, compared to e-commerce items and purchases, events and participation are usually of a much smaller frequency, and the data may be insufficient to learn an accurate model. In this paper, we propose to utilize social media retweeting activity data to enhance the learning of event participant prediction models. We create a joint knowledge graph to bridge the social media and the target domain, assuming that event descriptions and tweets are written in the same language. Furthermore, we propose a learning model that utilizes retweeting information for the target domain prediction more effectively. We conduct comprehensive experiments in two scenarios with real-world data. In each scenario, we set up training data of different sizes, as well as warm and cold test cases. The evaluation results show that our approach consistently outperforms several baseline models, especially with the warm test cases, and when target domain data is limited.
Causal Disentangled Variational Auto-Encoder for Preference Understanding in Recommendation
Apr 17, 2023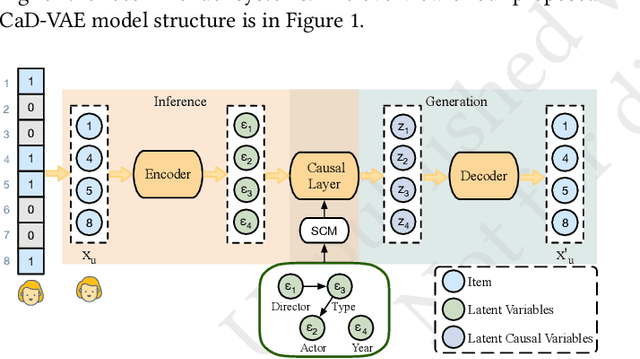
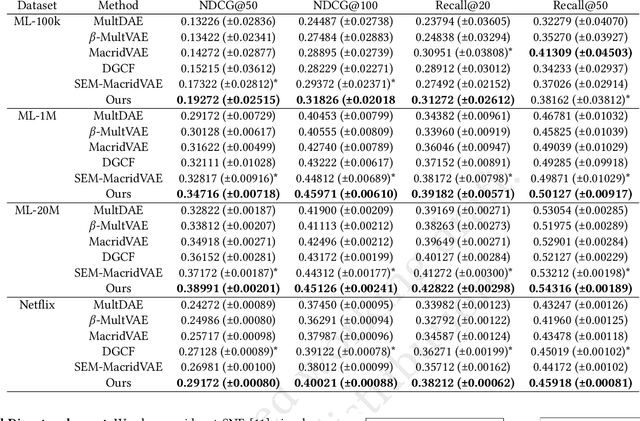
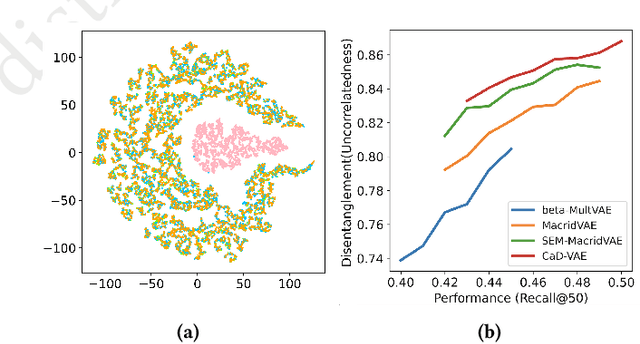
Recommendation models are typically trained on observational user interaction data, but the interactions between latent factors in users' decision-making processes lead to complex and entangled data. Disentangling these latent factors to uncover their underlying representation can improve the robustness, interpretability, and controllability of recommendation models. This paper introduces the Causal Disentangled Variational Auto-Encoder (CaD-VAE), a novel approach for learning causal disentangled representations from interaction data in recommender systems. The CaD-VAE method considers the causal relationships between semantically related factors in real-world recommendation scenarios, rather than enforcing independence as in existing disentanglement methods. The approach utilizes structural causal models to generate causal representations that describe the causal relationship between latent factors. The results demonstrate that CaD-VAE outperforms existing methods, offering a promising solution for disentangling complex user behavior data in recommendation systems.
Debiasing Graph Transfer Learning via Item Semantic Clustering for Cross-Domain Recommendations
Nov 07, 2022Deep learning-based recommender systems may lead to over-fitting when lacking training interaction data. This over-fitting significantly degrades recommendation performances. To address this data sparsity problem, cross-domain recommender systems (CDRSs) exploit the data from an auxiliary source domain to facilitate the recommendation on the sparse target domain. Most existing CDRSs rely on overlapping users or items to connect domains and transfer knowledge. However, matching users is an arduous task and may involve privacy issues when data comes from different companies, resulting in a limited application for the above CDRSs. Some studies develop CDRSs that require no overlapping users and items by transferring learned user interaction patterns. However, they ignore the bias in user interaction patterns between domains and hence suffer from an inferior performance compared with single-domain recommender systems. In this paper, based on the above findings, we propose a novel CDRS, namely semantic clustering enhanced debiasing graph neural recommender system (SCDGN), that requires no overlapping users and items and can handle the domain bias. More precisely, SCDGN semantically clusters items from both domains and constructs a cross-domain bipartite graph generated from item clusters and users. Then, the knowledge is transferred via this cross-domain user-cluster graph from the source to the target. Furthermore, we design a debiasing graph convolutional layer for SCDGN to extract unbiased structural knowledge from the cross-domain user-cluster graph. Our Experimental results on three public datasets and a pair of proprietary datasets verify the effectiveness of SCDGN over state-of-the-art models in terms of cross-domain recommendations.
Using Social Media Background to Improve Cold-start Recommendation Deep Models
Jun 04, 2021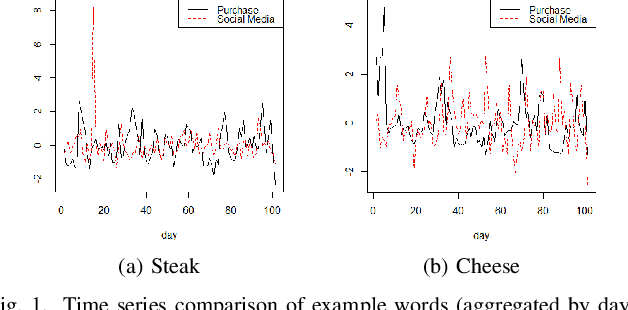
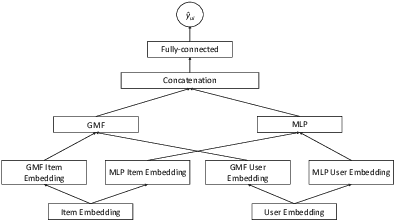
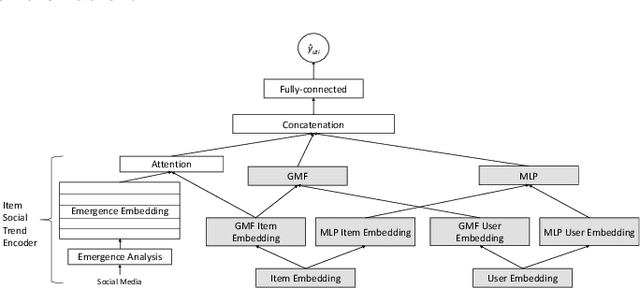
In recommender systems, a cold-start problem occurs when there is no past interaction record associated with the user or item. Typical solutions to the cold-start problem make use of contextual information, such as user demographic attributes or product descriptions. A group of works have shown that social media background can help predicting temporal phenomenons such as product sales and stock price movements. In this work, our goal is to investigate whether social media background can be used as extra contextual information to improve recommendation models. Based on an existing deep neural network model, we proposed a method to represent temporal social media background as embeddings and fuse them as an extra component in the model. We conduct experimental evaluations on a real-world e-commerce dataset and a Twitter dataset. The results show that our method of fusing social media background with the existing model does generally improve recommendation performance. In some cases the recommendation accuracy measured by hit-rate@K doubles after fusing with social media background. Our findings can be beneficial for future recommender system designs that consider complex temporal information representing social interests.
A General Method for Event Detection on Social Media
Jun 04, 2021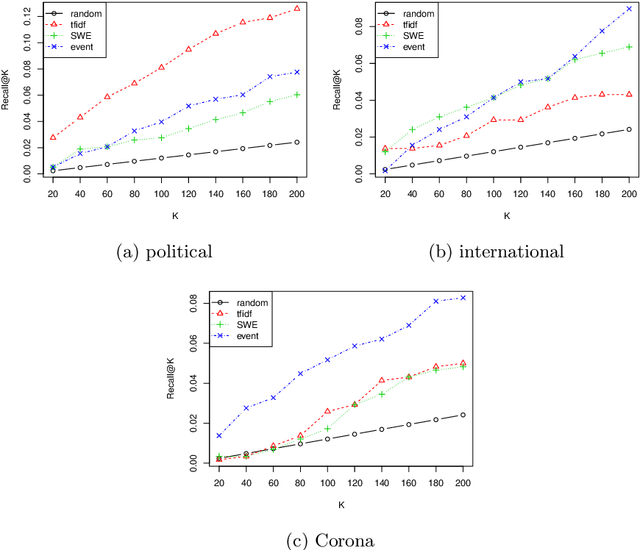
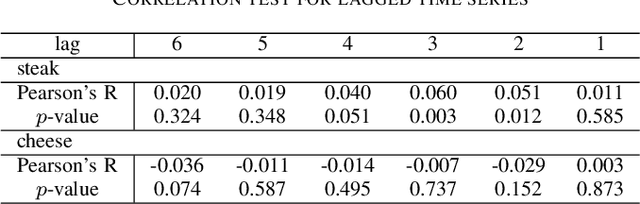
Event detection on social media has attracted a number of researches, given the recent availability of large volumes of social media discussions. Previous works on social media event detection either assume a specific type of event, or assume certain behavior of observed variables. In this paper, we propose a general method for event detection on social media that makes few assumptions. The main assumption we make is that when an event occurs, affected semantic aspects will behave differently from its usual behavior. We generalize the representation of time units based on word embeddings of social media text, and propose an algorithm to detect events in time series in a general sense. In the experimental evaluation, we use a novel setting to test if our method and baseline methods can exhaustively catch all real-world news in the test period. The evaluation results show that when the event is quite unusual with regard to the base social media discussion, it can be captured more effectively with our method. Our method can be easily implemented and can be treated as a starting point for more specific applications.
GeCo: Quality Counterfactual Explanations in Real Time
Jan 05, 2021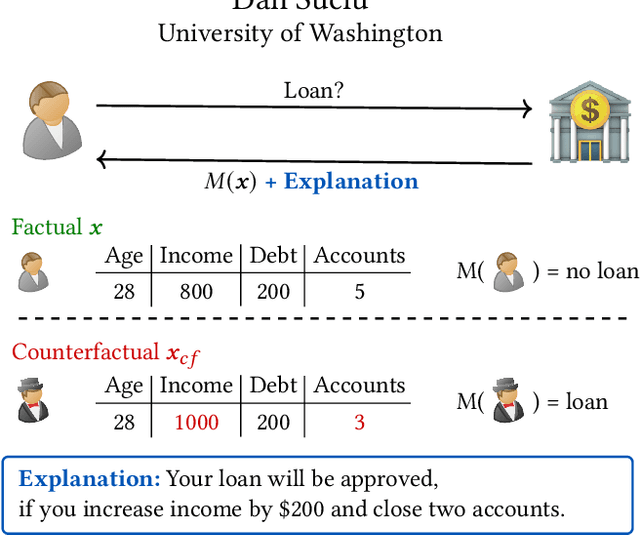
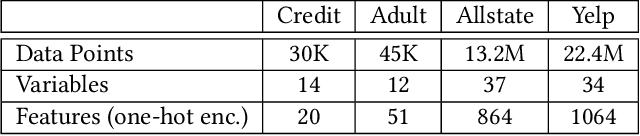

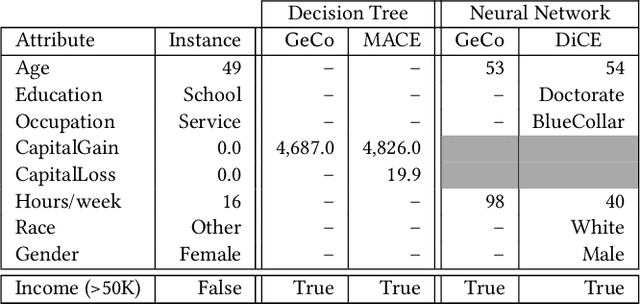
Machine learning is increasingly applied in high-stakes decision making that directly affect people's lives, and this leads to an increased demand for systems to explain their decisions. Explanations often take the form of counterfactuals, which consists of conveying to the end user what she/he needs to change in order to improve the outcome. Computing counterfactual explanations is challenging, because of the inherent tension between a rich semantics of the domain, and the need for real time response. In this paper we present GeCo, the first system that can compute plausible and feasible counterfactual explanations in real time. At its core, GeCo relies on a genetic algorithm, which is customized to favor searching counterfactual explanations with the smallest number of changes. To achieve real-time performance, we introduce two novel optimizations: $\Delta$-representation of candidate counterfactuals, and partial evaluation of the classifier. We compare empirically GeCo against four other systems described in the literature, and show that it is the only system that can achieve both high quality explanations and real time answers.