 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganized Event Participant Prediction Enhanced by Social Media Retweeting Data
Oct 02, 2023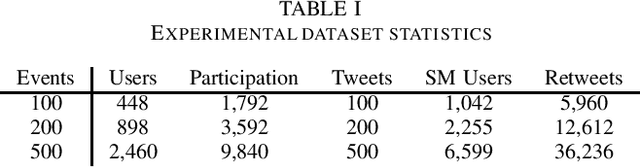
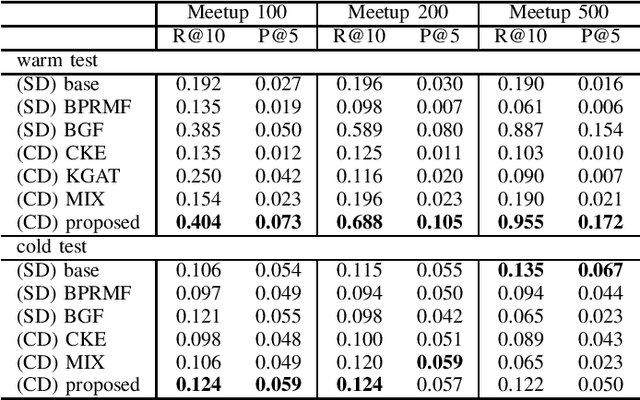
Nowadays, many platforms on the Web offer organized events, allowing users to be organizers or participants. For such platforms, it is beneficial to predict potential event participants. Existing work on this problem tends to borrow recommendation techniques. However, compared to e-commerce items and purchases, events and participation are usually of a much smaller frequency, and the data may be insufficient to learn an accurate model. In this paper, we propose to utilize social media retweeting activity data to enhance the learning of event participant prediction models. We create a joint knowledge graph to bridge the social media and the target domain, assuming that event descriptions and tweets are written in the same language. Furthermore, we propose a learning model that utilizes retweeting information for the target domain prediction more effectively. We conduct comprehensive experiments in two scenarios with real-world data. In each scenario, we set up training data of different sizes, as well as warm and cold test cases. The evaluation results show that our approach consistently outperforms several baseline models, especially with the warm test cases, and when target domain data is limited.
Unsupervised Human Activity Recognition through Two-stage Prompting with ChatGPT
Jun 03, 2023Wearable sensor devices, which offer the advantage of recording daily objects used by a person while performing an activity, enable the feasibility of unsupervised Human Activity Recognition (HAR). Unfortunately, previous unsupervised approaches using the usage sequence of objects usually require a proper description of activities manually prepared by humans. Instead, we leverage the knowledge embedded in a Large Language Model (LLM) of ChatGPT. Because the sequence of objects robustly characterizes the activity identity, it is possible that ChatGPT already learned the association between activities and objects from existing contexts. However, previous prompt engineering for ChatGPT exhibits limited generalization ability when dealing with a list of words (i.e., sequence of objects) due to the similar weighting assigned to each word in the list. In this study, we propose a two-stage prompt engineering, which first guides ChatGPT to generate activity descriptions associated with objects while emphasizing important objects for distinguishing similar activities; then outputs activity classes and explanations for enhancing the contexts that are helpful for HAR. To the best of our knowledge, this is the first study that utilizes ChatGPT to recognize activities using objects in an unsupervised manner. We conducted our approach on three datasets and demonstrated the state-of-the-art performance.
OpenPack: A Large-scale Dataset for Recognizing Packaging Works in IoT-enabled Logistic Environments
Dec 10, 2022Unlike human daily activities, existing publicly available sensor datasets for work activity recognition in industrial domains are limited by difficulties in collecting realistic data as close collaboration with industrial sites is required. This also limits research on and development of AI methods for industrial applications. To address these challenges and contribute to research on machine recognition of work activities in industrial domains, in this study, we introduce a new large-scale dataset for packaging work recognition called OpenPack. OpenPack contains 53.8 hours of multimodal sensor data, including keypoints, depth images, acceleration data, and readings from IoT-enabled devices (e.g., handheld barcode scanners used in work procedures), collected from 16 distinct subjects with different levels of packaging work experience. On the basis of this dataset, we propose a neural network model designed to recognize work activities, which efficiently fuses sensor data and readings from IoT-enabled devices by processing them within different streams in a ladder-shaped architecture, and the experiment showed the effectiveness of the architecture. We believe that OpenPack will contribute to the community of action/activity recognition with sensors. OpenPack dataset is available at https://open-pack.github.io/.
Debiasing Graph Transfer Learning via Item Semantic Clustering for Cross-Domain Recommendations
Nov 07, 2022Deep learning-based recommender systems may lead to over-fitting when lacking training interaction data. This over-fitting significantly degrades recommendation performances. To address this data sparsity problem, cross-domain recommender systems (CDRSs) exploit the data from an auxiliary source domain to facilitate the recommendation on the sparse target domain. Most existing CDRSs rely on overlapping users or items to connect domains and transfer knowledge. However, matching users is an arduous task and may involve privacy issues when data comes from different companies, resulting in a limited application for the above CDRSs. Some studies develop CDRSs that require no overlapping users and items by transferring learned user interaction patterns. However, they ignore the bias in user interaction patterns between domains and hence suffer from an inferior performance compared with single-domain recommender systems. In this paper, based on the above findings, we propose a novel CDRS, namely semantic clustering enhanced debiasing graph neural recommender system (SCDGN), that requires no overlapping users and items and can handle the domain bias. More precisely, SCDGN semantically clusters items from both domains and constructs a cross-domain bipartite graph generated from item clusters and users. Then, the knowledge is transferred via this cross-domain user-cluster graph from the source to the target. Furthermore, we design a debiasing graph convolutional layer for SCDGN to extract unbiased structural knowledge from the cross-domain user-cluster graph. Our Experimental results on three public datasets and a pair of proprietary datasets verify the effectiveness of SCDGN over state-of-the-art models in terms of cross-domain recommendations.
Learned k-NN Distance Estimation
Aug 29, 2022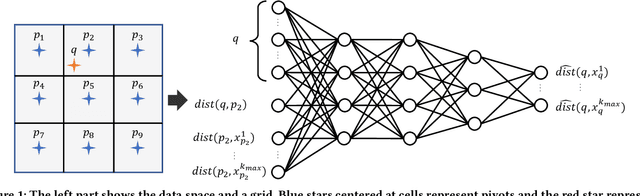
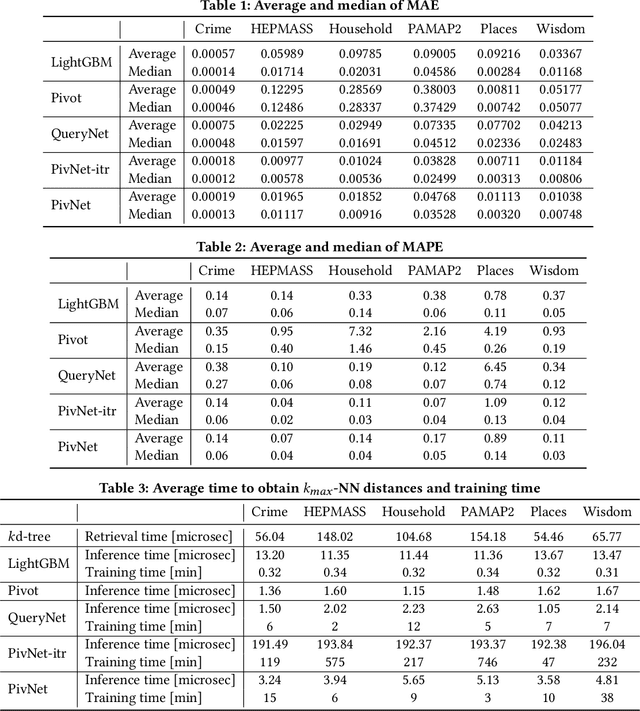

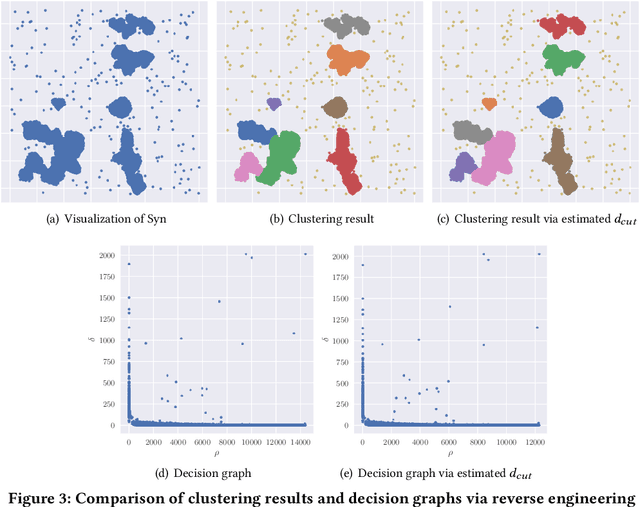
Big data mining is well known to be an important task for data science, because it can provide useful observations and new knowledge hidden in given large datasets. Proximity-based data analysis is particularly utilized in many real-life applications. In such analysis, the distances to k nearest neighbors are usually employed, thus its main bottleneck is derived from data retrieval. Much efforts have been made to improve the efficiency of these analyses. However, they still incur large costs, because they essentially need many data accesses. To avoid this issue, we propose a machine-learning technique that quickly and accurately estimates the k-NN distances (i.e., distances to the k nearest neighbors) of a given query. We train a fully connected neural network model and utilize pivots to achieve accurate estimation. Our model is designed to have useful advantages: it infers distances to the k-NNs at a time, its inference time is O(1) (no data accesses are incurred), but it keeps high accuracy. Our experimental results and case studies on real datasets demonstrate the efficiency and effectiveness of our solution.
Using Social Media Background to Improve Cold-start Recommendation Deep Models
Jun 04, 2021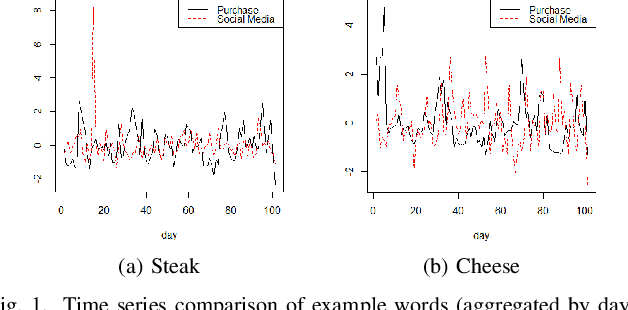
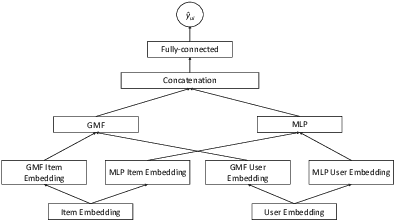
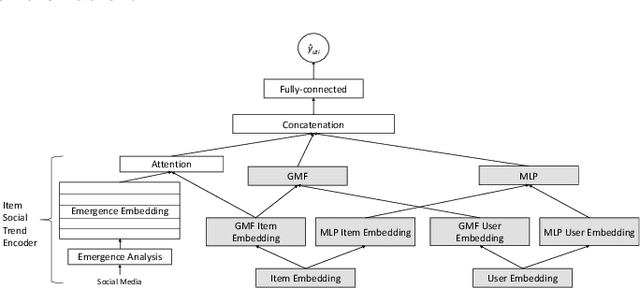
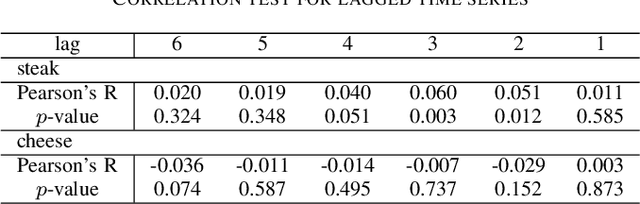
In recommender systems, a cold-start problem occurs when there is no past interaction record associated with the user or item. Typical solutions to the cold-start problem make use of contextual information, such as user demographic attributes or product descriptions. A group of works have shown that social media background can help predicting temporal phenomenons such as product sales and stock price movements. In this work, our goal is to investigate whether social media background can be used as extra contextual information to improve recommendation models. Based on an existing deep neural network model, we proposed a method to represent temporal social media background as embeddings and fuse them as an extra component in the model. We conduct experimental evaluations on a real-world e-commerce dataset and a Twitter dataset. The results show that our method of fusing social media background with the existing model does generally improve recommendation performance. In some cases the recommendation accuracy measured by hit-rate@K doubles after fusing with social media background. Our findings can be beneficial for future recommender system designs that consider complex temporal information representing social interests.
A General Method for Event Detection on Social Media
Jun 04, 2021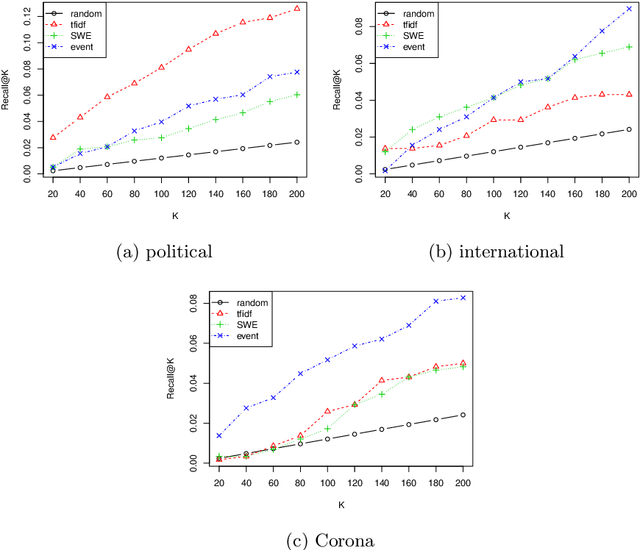
Event detection on social media has attracted a number of researches, given the recent availability of large volumes of social media discussions. Previous works on social media event detection either assume a specific type of event, or assume certain behavior of observed variables. In this paper, we propose a general method for event detection on social media that makes few assumptions. The main assumption we make is that when an event occurs, affected semantic aspects will behave differently from its usual behavior. We generalize the representation of time units based on word embeddings of social media text, and propose an algorithm to detect events in time series in a general sense. In the experimental evaluation, we use a novel setting to test if our method and baseline methods can exhaustively catch all real-world news in the test period. The evaluation results show that when the event is quite unusual with regard to the base social media discussion, it can be captured more effectively with our method. Our method can be easily implemented and can be treated as a starting point for more specific applications.