 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned k-NN Distance Estimation
Paper and Code
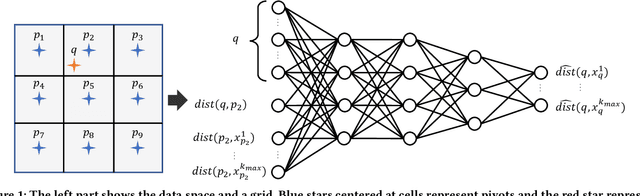
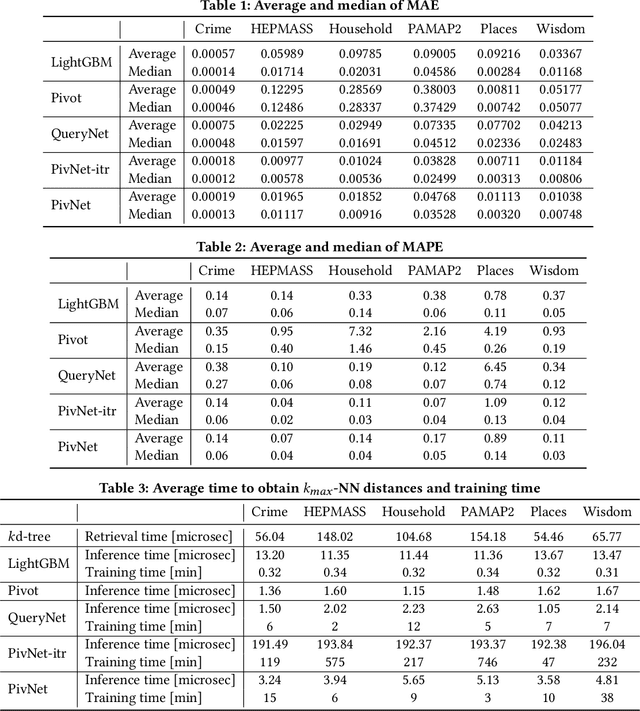

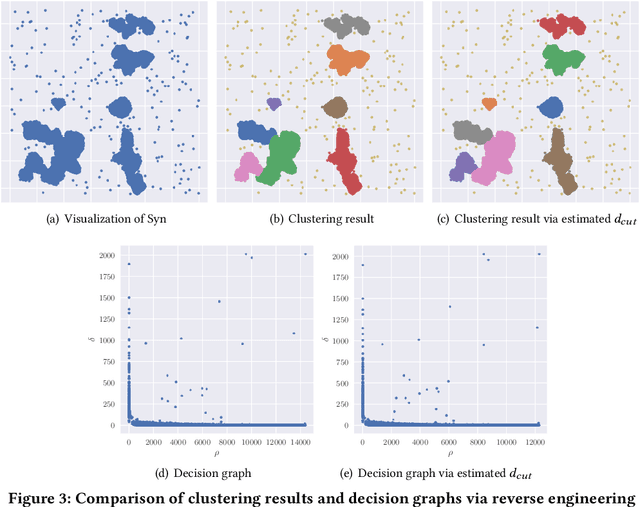
Big data mining is well known to be an important task for data science, because it can provide useful observations and new knowledge hidden in given large datasets. Proximity-based data analysis is particularly utilized in many real-life applications. In such analysis, the distances to k nearest neighbors are usually employed, thus its main bottleneck is derived from data retrieval. Much efforts have been made to improve the efficiency of these analyses. However, they still incur large costs, because they essentially need many data accesses. To avoid this issue, we propose a machine-learning technique that quickly and accurately estimates the k-NN distances (i.e., distances to the k nearest neighbors) of a given query. We train a fully connected neural network model and utilize pivots to achieve accurate estimation. Our model is designed to have useful advantages: it infers distances to the k-NNs at a time, its inference time is O(1) (no data accesses are incurred), but it keeps high accuracy. Our experimental results and case studies on real datasets demonstrate the efficiency and effectiveness of our solution.