 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned spatial data partitioning
Jun 19, 2023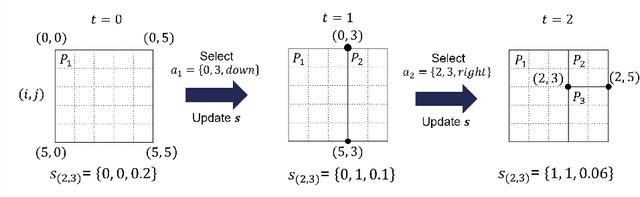
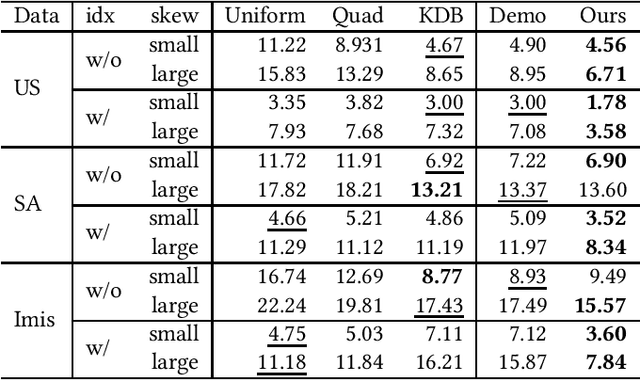
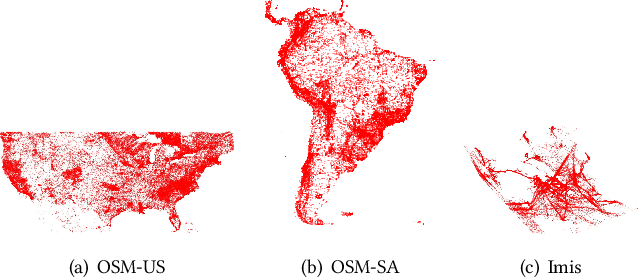
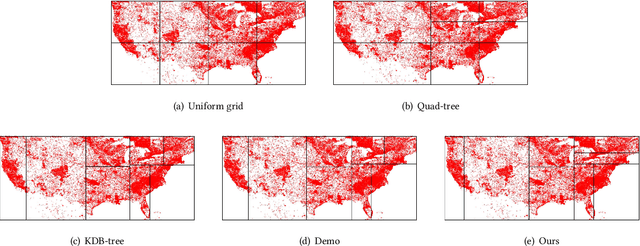
Due to the significant increase in the size of spatial data, it is essential to use distributed parallel processing systems to efficiently analyze spatial data. In this paper, we first study learned spatial data partitioning, which effectively assigns groups of big spatial data to computers based on locations of data by using machine learning techniques. We formalize spatial data partitioning in the context of reinforcement learning and develop a novel deep reinforcement learning algorithm. Our learning algorithm leverages features of spatial data partitioning and prunes ineffective learning processes to find optimal partitions efficiently. Our experimental study, which uses Apache Sedona and real-world spatial data, demonstrates that our method efficiently finds partitions for accelerating distance join queries and reduces the workload run time by up to 59.4%.
Debiasing Graph Transfer Learning via Item Semantic Clustering for Cross-Domain Recommendations
Nov 07, 2022Deep learning-based recommender systems may lead to over-fitting when lacking training interaction data. This over-fitting significantly degrades recommendation performances. To address this data sparsity problem, cross-domain recommender systems (CDRSs) exploit the data from an auxiliary source domain to facilitate the recommendation on the sparse target domain. Most existing CDRSs rely on overlapping users or items to connect domains and transfer knowledge. However, matching users is an arduous task and may involve privacy issues when data comes from different companies, resulting in a limited application for the above CDRSs. Some studies develop CDRSs that require no overlapping users and items by transferring learned user interaction patterns. However, they ignore the bias in user interaction patterns between domains and hence suffer from an inferior performance compared with single-domain recommender systems. In this paper, based on the above findings, we propose a novel CDRS, namely semantic clustering enhanced debiasing graph neural recommender system (SCDGN), that requires no overlapping users and items and can handle the domain bias. More precisely, SCDGN semantically clusters items from both domains and constructs a cross-domain bipartite graph generated from item clusters and users. Then, the knowledge is transferred via this cross-domain user-cluster graph from the source to the target. Furthermore, we design a debiasing graph convolutional layer for SCDGN to extract unbiased structural knowledge from the cross-domain user-cluster graph. Our Experimental results on three public datasets and a pair of proprietary datasets verify the effectiveness of SCDGN over state-of-the-art models in terms of cross-domain recommendations.
Learned k-NN Distance Estimation
Aug 29, 2022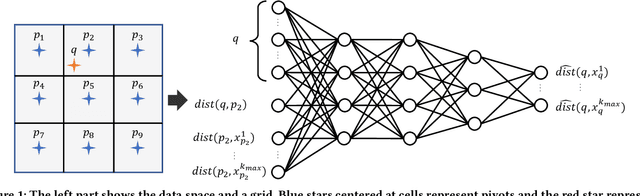
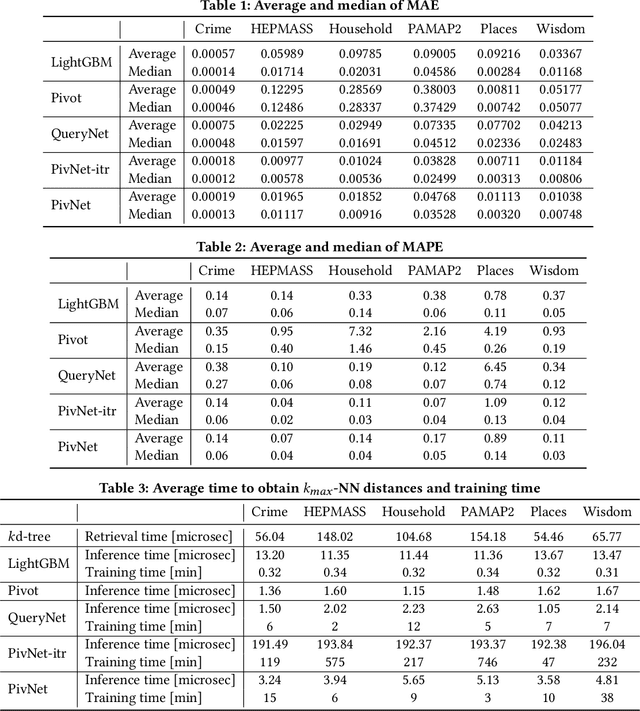

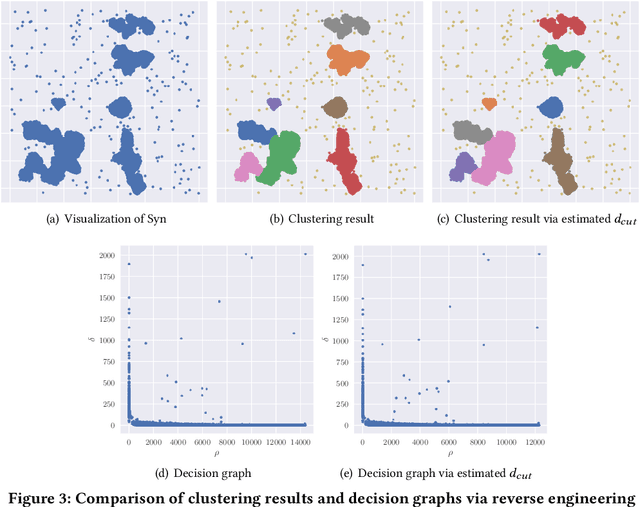
Big data mining is well known to be an important task for data science, because it can provide useful observations and new knowledge hidden in given large datasets. Proximity-based data analysis is particularly utilized in many real-life applications. In such analysis, the distances to k nearest neighbors are usually employed, thus its main bottleneck is derived from data retrieval. Much efforts have been made to improve the efficiency of these analyses. However, they still incur large costs, because they essentially need many data accesses. To avoid this issue, we propose a machine-learning technique that quickly and accurately estimates the k-NN distances (i.e., distances to the k nearest neighbors) of a given query. We train a fully connected neural network model and utilize pivots to achieve accurate estimation. Our model is designed to have useful advantages: it infers distances to the k-NNs at a time, its inference time is O(1) (no data accesses are incurred), but it keeps high accuracy. Our experimental results and case studies on real datasets demonstrate the efficiency and effectiveness of our solution.